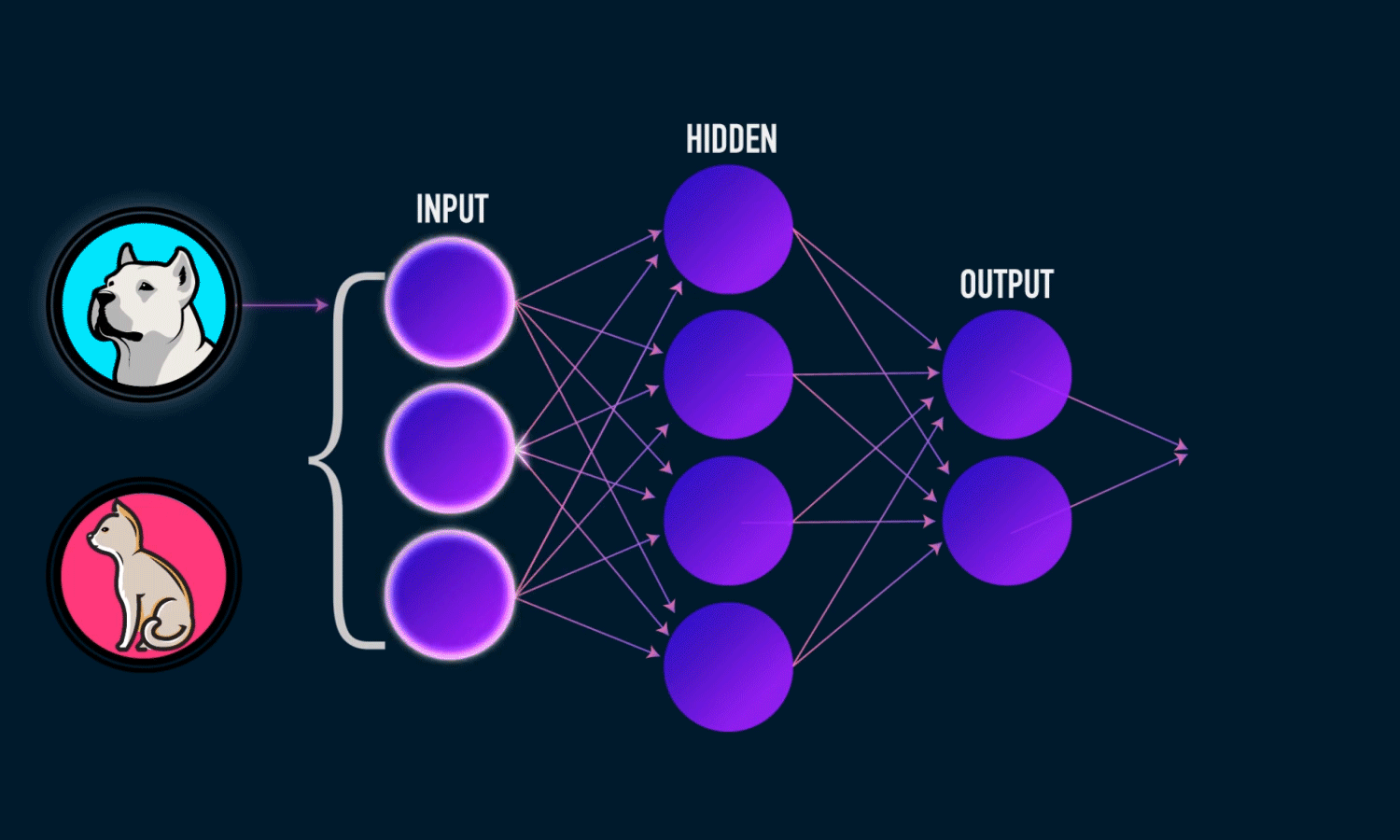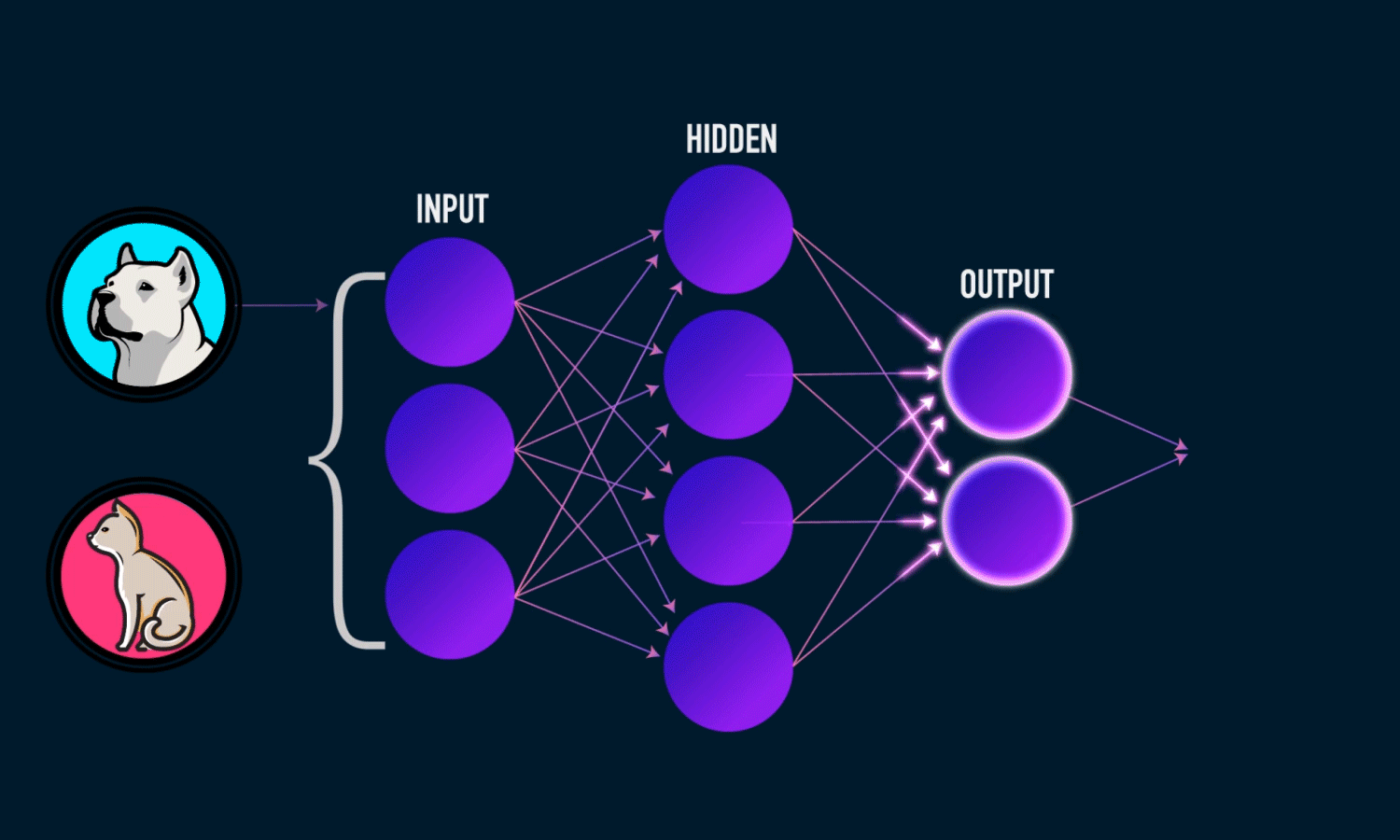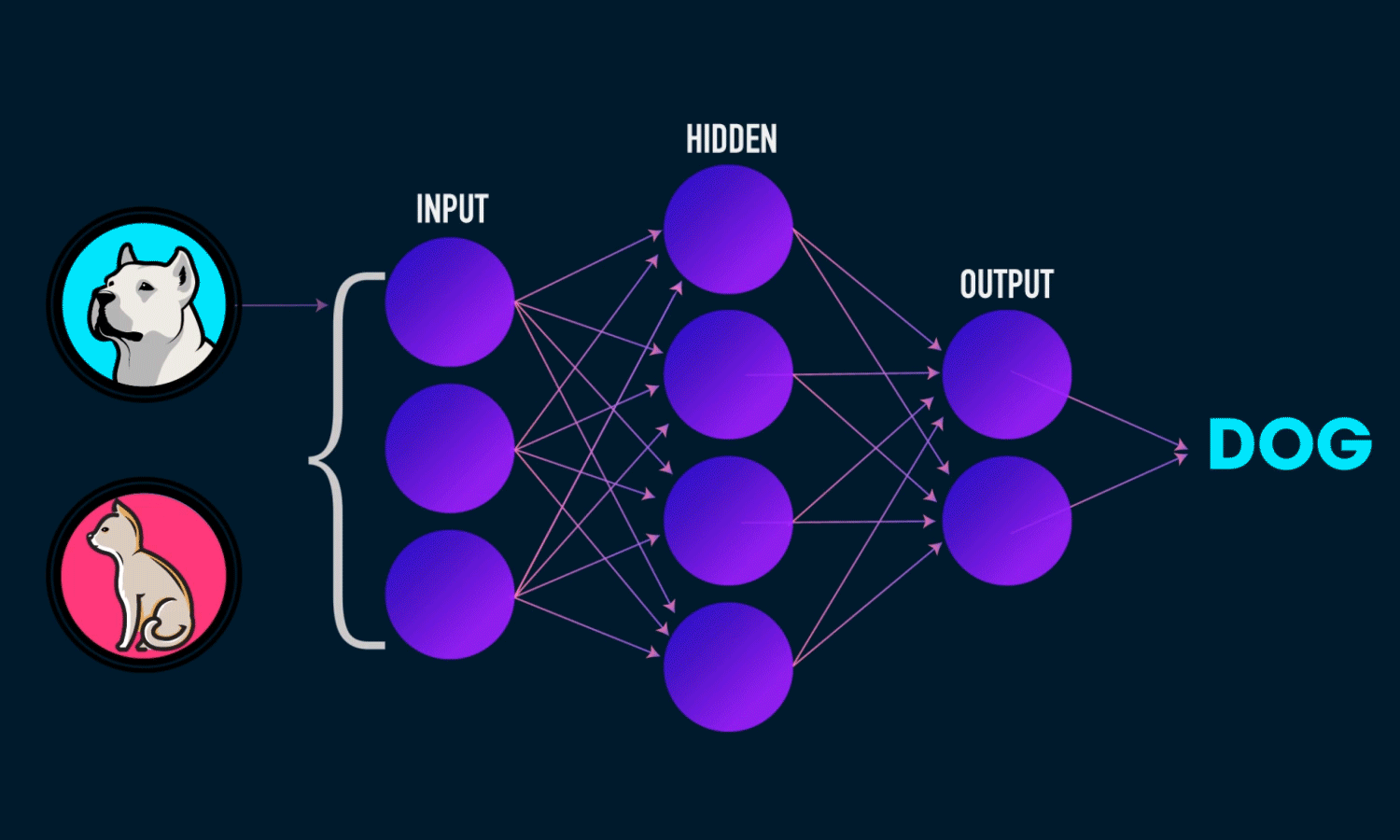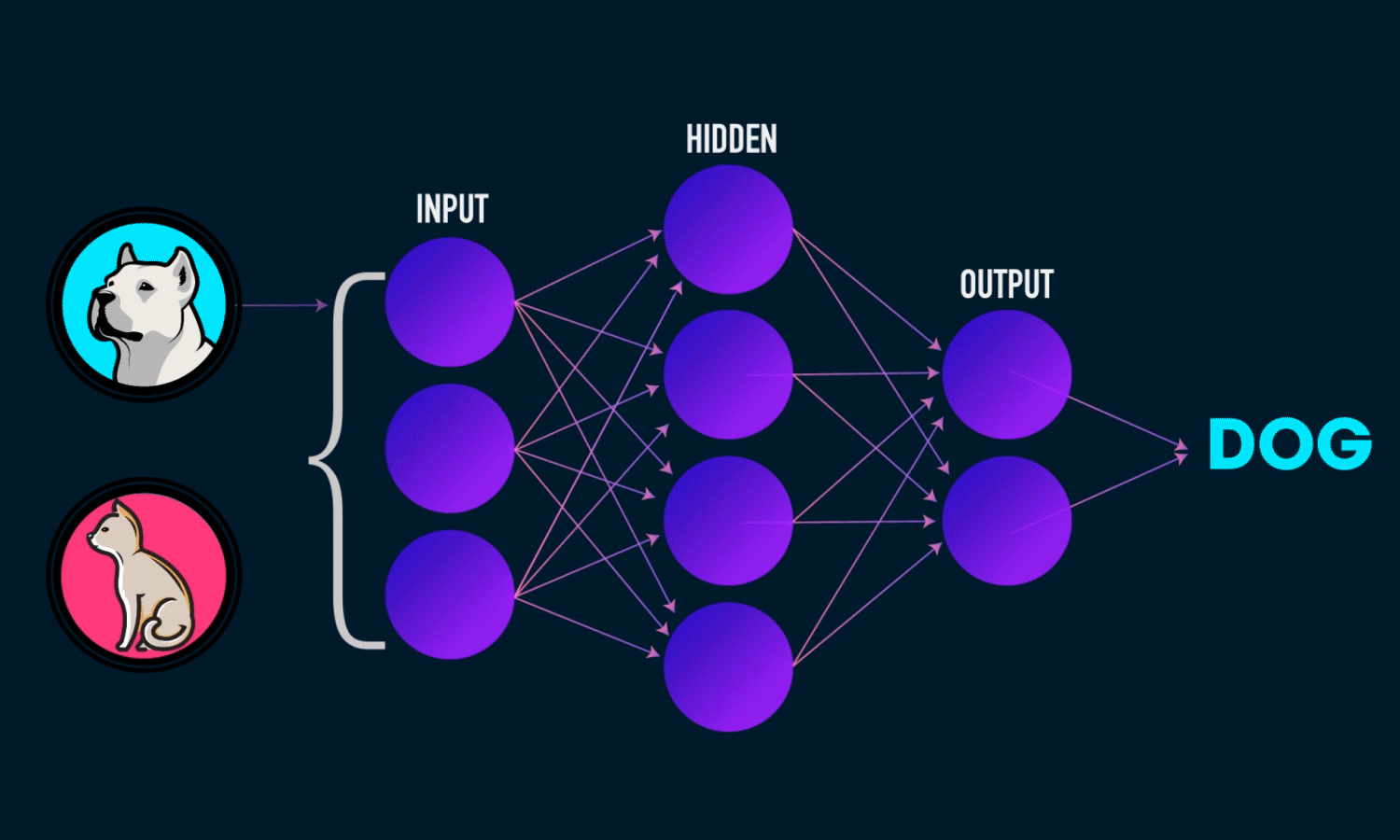
W tym rozdziale przedstawimy konwolucyjne (lub splotowe) sieci neuronowe (ang. convolutional neural networks), znane również jako CovNets, rodzaj modelu głębokiego uczenia się, który jest niemal zawsze stosowany w aplikacjach widzenia komputerowego.
Wkrótce zagłębimy się w teorię tego, czym są sieci splotowe i dlaczego odniosły taki sukces w zadaniach związanych z widzeniem komputerowym. Ale najpierw przyjrzyjmy się w praktyce prostemu przykładowi sieci splotowej. Wykorzystuje on sieć kowolucyjną do klasyfikacji cyfr MNIST, czyli zadania, które wykonaliśmy wcześniej przy użyciu sieci gęsto połączonej (nasza dokładność testu wyniosła wtedy 97,8%).
Poniższe linie kodu pokazują, jak wygląda podstawowa sieć CovNet. Jest to stos warstw layer_conv_2d i layer_max_pooling_2d, o których zasadzie działania będzie jeszcze więcej za chwilę.
Co ważne, CovNet przyjmuje jako dane wejściowe tensory o kształcie (image_height, image_width, image_channels) (nie licząc wymiaru partii). W tym przypadku skonfigurujemy sieć do przetwarzania danych wejściowych o rozmiarze (28, 28, 1), czyli w formacie obrazów MNIST. Zrobimy to przekazując argument input_shape = c(28, 28, 1) do pierwszej warstwy.
Zauważmy, że wyjścia z warstw layer_conv_2d i layer_max_pooling_2d są tensorami 3D kształtu (wysokość, szerokość, filtry)1. Wymiary szerokości i wysokości mają tendencję do kurczenia się, gdy wchodzimy głębiej w sieć. Liczba filtrów jest kontrolowana przez pierwszy argument przekazany do layer_conv_2d (32 lub 64).
1 w niektórych publikacjach ostatni parametr jest nazywany kanałami, ale aby nie wprowadzać zamieszania, ponieważ nazwa kanał jest zarezerwowana do obrazów, to zostanę przy nazwie filtry
Następnym krokiem jest wprowadzenie ostatniego tensora wyjściowego (o kształcie (3, 3, 64)) do gęsto połączonej sieci klasyfikatorów, takich jak te, które już znamy - stosu gęstych warstw. Te klasyfikatory przetwarzają wektory 1D, podczas gdy bieżące wyjście jest tensorem 3D. Najpierw musimy spłaszczyć wyjścia 3D do 1D, a następnie dodać kilka gęstych warstw na wierzchu.
Kod
model <- model %>%layer_flatten() %>%layer_dense(units =64, activation ="relu") %>%layer_dense(units =10, activation ="softmax")
Zrobimy klasyfikację 10-kierunkową, używając warstwy końcowej z 10 wyjściami i aktywacją softmax. Oto jak wygląda teraz sieć:
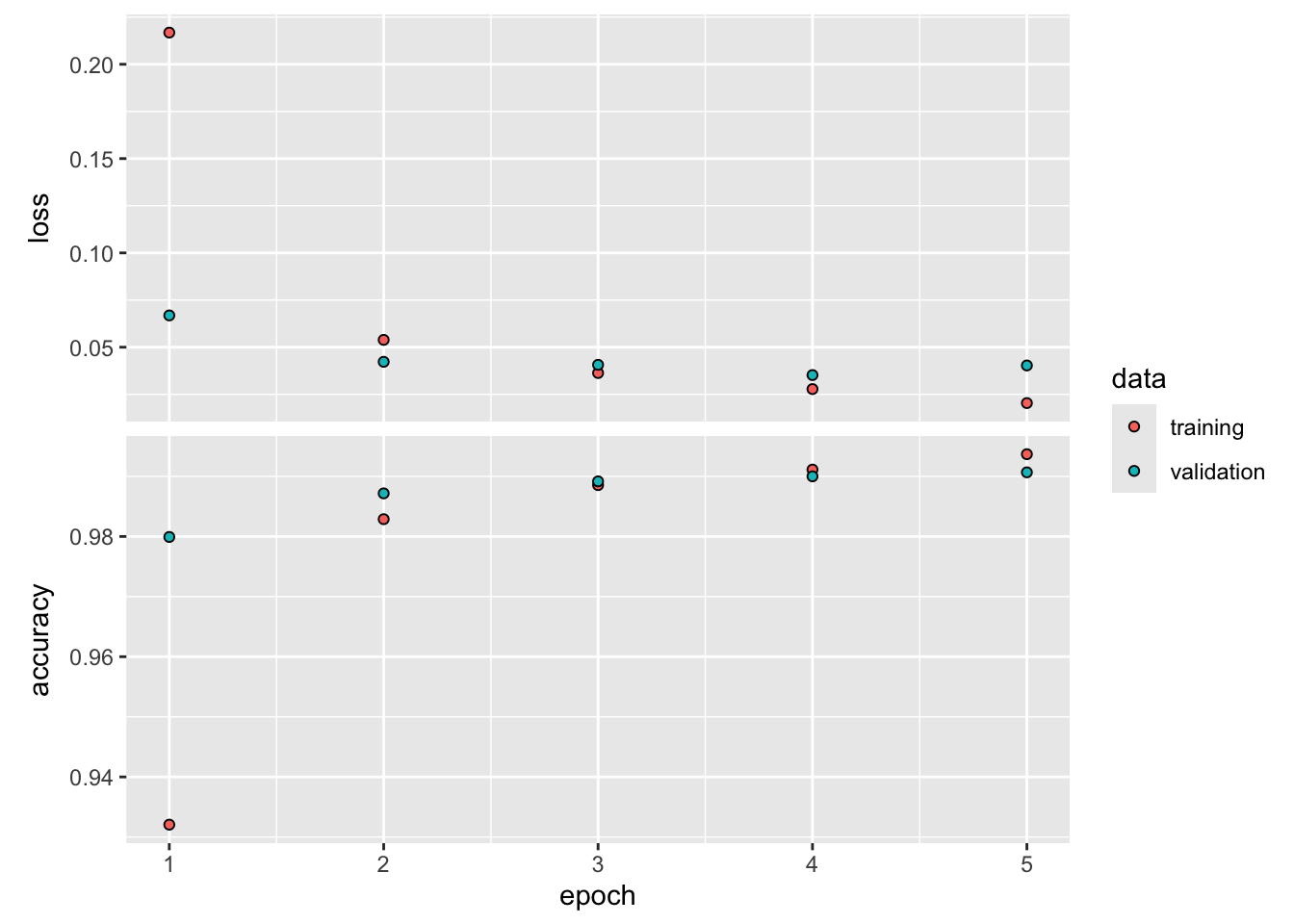
W rezultacie otrzymaliśmy sieć o dokładności 99,08%. Choć może to w stosunku do 97,79%, czyli dokładności dla sieci gęstej z pierwszego przykładu MNIST, to jednak względny błąd predykcji dla sieci splotowej zmalał o ponad 58% 🤩. Wynik imponujący, zatem pojawia się pytanie skąd taka dokładność? Na czym polega magia sieci splotowych? W poniższych listingach postaramy się to wyjaśnić.
12.1 Działanie sieci splotowej
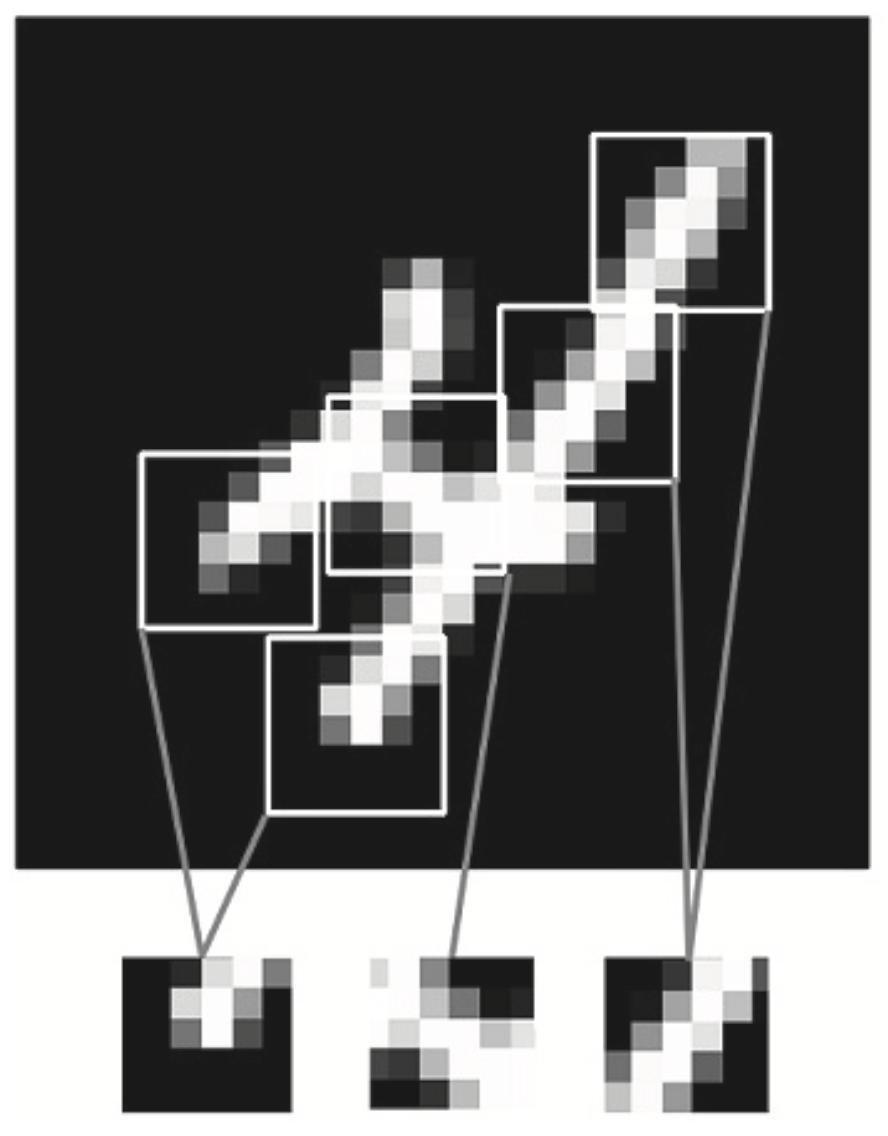
Podstawową różnicą pomiędzy warstwą gęstych połączeń a siecią splotową jest to, że warstwy dense uczą się cech parametrów globalnych w swoich wejściowych przestrzeniach (w przypadku cyfr MNIST są to wzorce związane ze wszystkimi pikselami), a warstwy konwolucyjne uczą się lokalnych wzorców (patrz Rysunek 12.1) - w przypadku obrazów wzorce są znajdowane w małych dwuwymiarowych oknach danych wejściowych. W zaprezentowanym przykładzie wszystkie te okna charakteryzowały się wymiarami 3x3.
Rysunek 12.1: Rozbicie obrazu na lokalne wzorce
Dzięki tej kluczowej charakterystyce sieci konwolucyjne mają dwie ciekawe własności:
wzorce rozpoznawane przez sieć są niezależne od przesunięcia. Sieć konwolucyjna po rozpoznaniu określonego wzoru w prawym dolnym rogu obrazu może rozpoznać go np. w lewym górnym rogu obrazu. Sieć gęsta w celu rozpoznania wzorca znajdującego się w innym miejscu musi nauczyć się go na nowo. W związku z tym sieci konwolucyjne charakteryzują się dużą wydajnością podczas przetwarzania obrazów. Sieci splotowe mogą skutecznie tworzyć uogólnienia po przetworzeniu mniejszego zbioru testowego.
sieci splotowe mogą uczyć się przestrzennej hierarchii wzorców (patrz Rysunek 12.8). Pierwsza warstwa uczy się rozpoznania położenia kluczowych obiektów przez zmianę konturów i kontrastu. Druga warstwa (pooling) redukuje najważniejsze informacje do prostszej postaci (zmniejszenie rozdzielczości). Kolejna warstwa stara się wyciągnąć kluczowe elementy (wzorce) występujące w obiekcie, jak linie proste, ukośne, okręgi, łuki, itp. Kolejne dwie warstwy ponownie redukują rozdzielczość wyciągając kluczowe elementy obrazu. Ostatecznie wartości wyjściowe z ostatniej warstwy konwolucyjnej przekazują kluczowe informacje do sieci gęstej, a ta ostatecznie zamienia je za pomocą funkcji softmax na przewidywane cyfry.
Sieci konwolucyjne działają na trójwymiarowych tensorach określanych mianem map cech, zawierających dwie przestrzenne osie definiujące wysokość i szerokość. Trzecią osią jest oś głębi, nazywana również osią kanałów. W przypadku obrazu RGB oś głębi ma trzy wymiary (po jednym dla każdego koloru). Obrazy monochromatyczne (takie jak MNIST), mają jeden wymiar głębi (kolor opisuje tylko skalę nasycenia szarości). Operacja konwolucji wyodrębnia fragmenty z wejściowej mapy cech i stosuje to samo przekształcenie do wszystkich tych fragmentów, dając wyjściową mapę cech. Ta wyjściowa mapa cech jest nadal tensorem 3D: ma szerokość i wysokość. Jej głębokość może być dowolna, ponieważ głębokość wyjściowa jest parametrem warstwy, a różne kanały w tej osi głębokości nie oznaczają już konkretnych kolorów, jak w przypadku wejścia RGB; oznaczają one raczej filtry. Filtry kodują specyficzne aspekty danych wejściowych: na wysokim poziomie pojedynczy filtr może kodować na przykład pojęcie “obecności twarzy na wejściu”.
Rysunek 12.2: Procedura filtrowania obrazu
W przykładzie MNIST, pierwsza warstwa konwolucji pobiera mapę cech o rozmiarze (28, 28, 1) i wyprowadza mapę cech o rozmiarze (26, 26, 32): oblicza 32 filtry na danych wejściowych. Każdy z tych 32 filtrów wyjściowych zawiera siatkę wartości 26 × 26, która jest mapą odpowiedzi filtra, wskazującą odpowiedź tego filtra w różnych miejscach wejścia (patrz Rysunek 12.2). To właśnie oznacza termin mapa cech: każdy wymiar na osi głębokości jest cechą (lub filtrem), a tensor 2D output[:, :, n] jest przestrzenną mapą 2D odpowiedzi tego filtra na wejście.
Konwolucje są definiowane przez dwa kluczowe parametry:
Rozmiar filtrów wyodrębnionych z wejść - są to zwykle 3 × 3 lub 5 × 5. W przykładzie były to 3 × 3, co jest częstym wyborem.
Głębokość wyjściowej mapy cech - czyli liczba filtrów obliczonych przez konwolucję. Przykład rozpoczął się z głębokością 32, a zakończył z głębokością 64.
W keras parametry te są pierwszymi argumentami przekazywanymi do warstwy: layer_conv_2d(output_depth, c(window_height, window_width)).
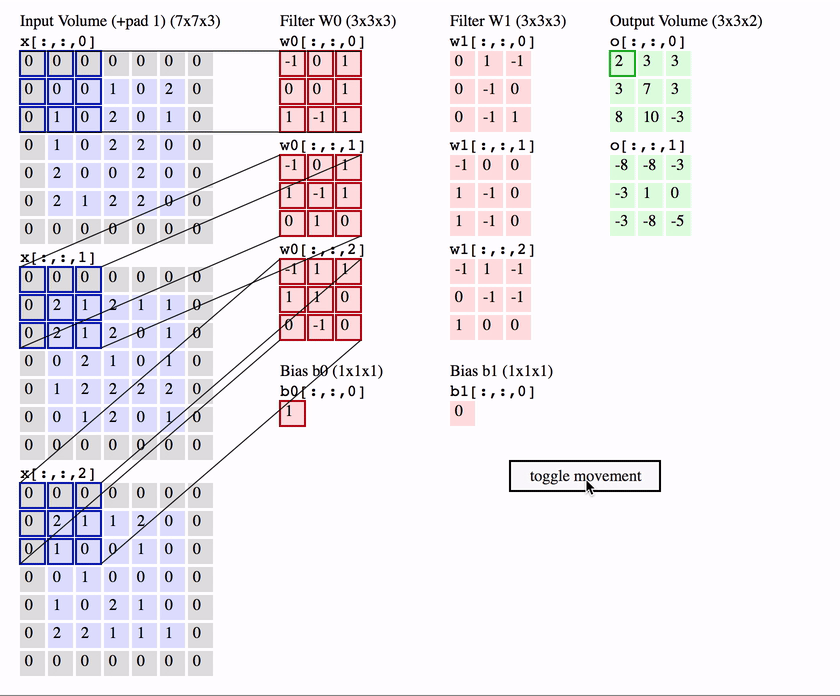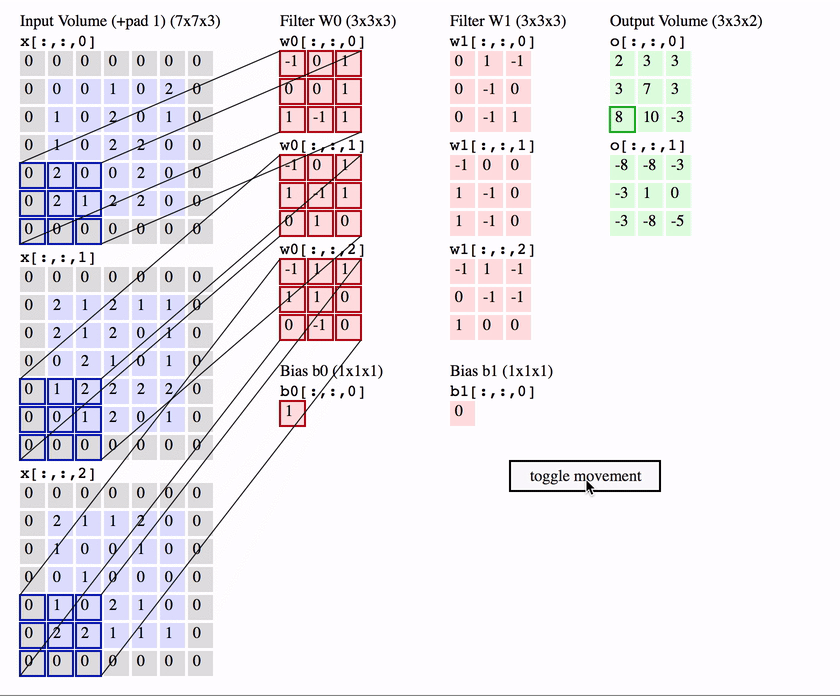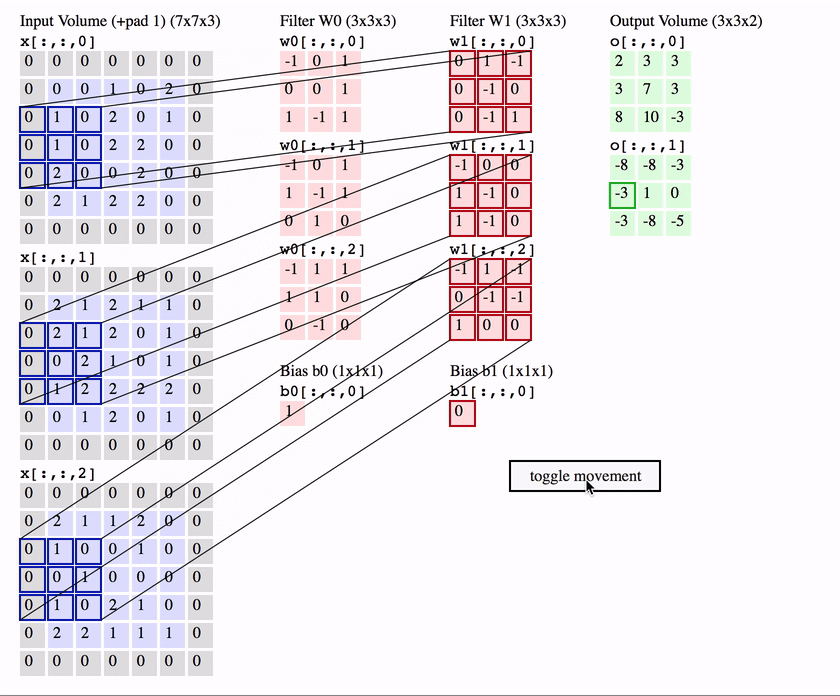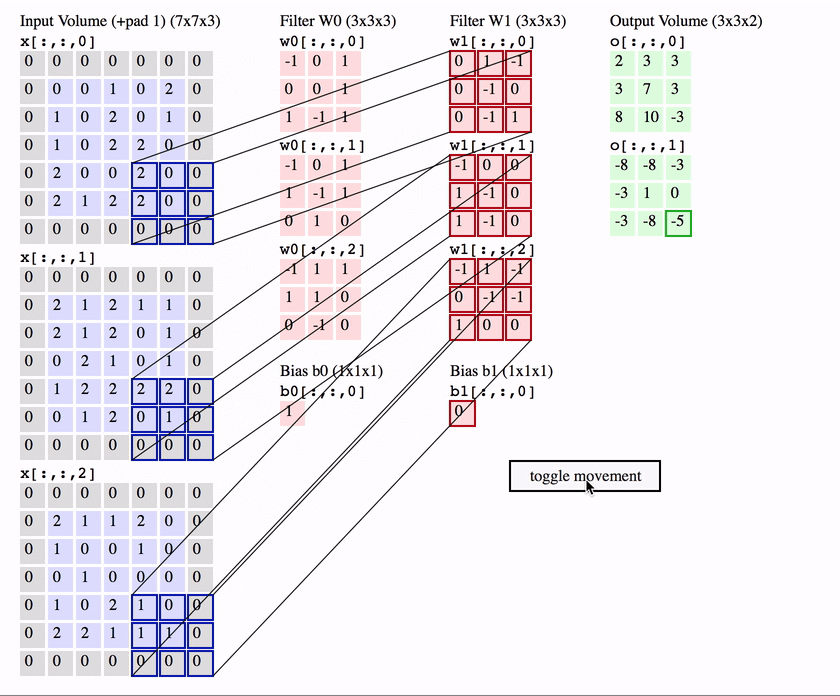
Konwolucja działa poprzez przesuwanie tych okien o rozmiarze 3 × 3 lub 5 × 5 po wejściowej mapie cech 3D, zatrzymując się w każdym możliwym miejscu, i wyodrębniając trójwymiarową łatę otaczających cech (kształt (window_height, window_width, input_depth)). Każda taka paczka 3D jest następnie przekształcana (poprzez iloczyn tensorowy z tą samą uczoną macierzą wag, zwaną jądrem konwolucji) w 1D wektor kształtu (output_depth). Wszystkie te wektory są następnie przestrzennie składane w trójwymiarową wyjściową mapę kształtu (wysokość, szerokość, głębokość wyjściowa). Każde miejsce w wyjściowej mapie cech odpowiada temu samemu miejscu w wejściowej mapie cech (na przykład prawy dolny róg wyjścia zawiera informacje o prawym dolnym rogu wejścia). Na przykład, przy oknach 3 × 3, wektor output[i, j, ] pochodzi z wejściowej mapy 3D input[i-1:i+1, j-1:j+1, ]. Pełny proces został szczegółowo przedstawiony na Rysunek 12.3.
Rysunek 12.3: Zasada działania filtrów w sieci splotowej
Zauważmy, że szerokość i wysokość wyjściowa może się różnić od szerokości i wysokości wejściowej. Mogą się one różnić z dwóch powodów:
Efekty brzegowe, którym można przeciwdziałać poprzez padding wejściowej mapy funkcji
Użycie pasków (ang. strides), które zdefiniujemy za chwilę.
12.1.1 Efekty brzegowe - padding
Rozważmy mapę cech 5 × 5 (łącznie 25 kwadratów). Jest tylko 9 kwadratów, wokół których można wyśrodkować okno 3 × 3, tworząc siatkę 3 × 3. Dlatego też wyjściowa mapa cech zmniejsza się nieco: w tym przypadku dokładnie o dwa kwadraty wzdłuż każdego wymiaru. Ten efekt brzegowy można zobaczyć w działaniu we wcześniejszym przykładzie: zaczynamy z 28 × 28 na danych wejściowych, które po pierwszej warstwie konwolucji stają się 26 × 26.
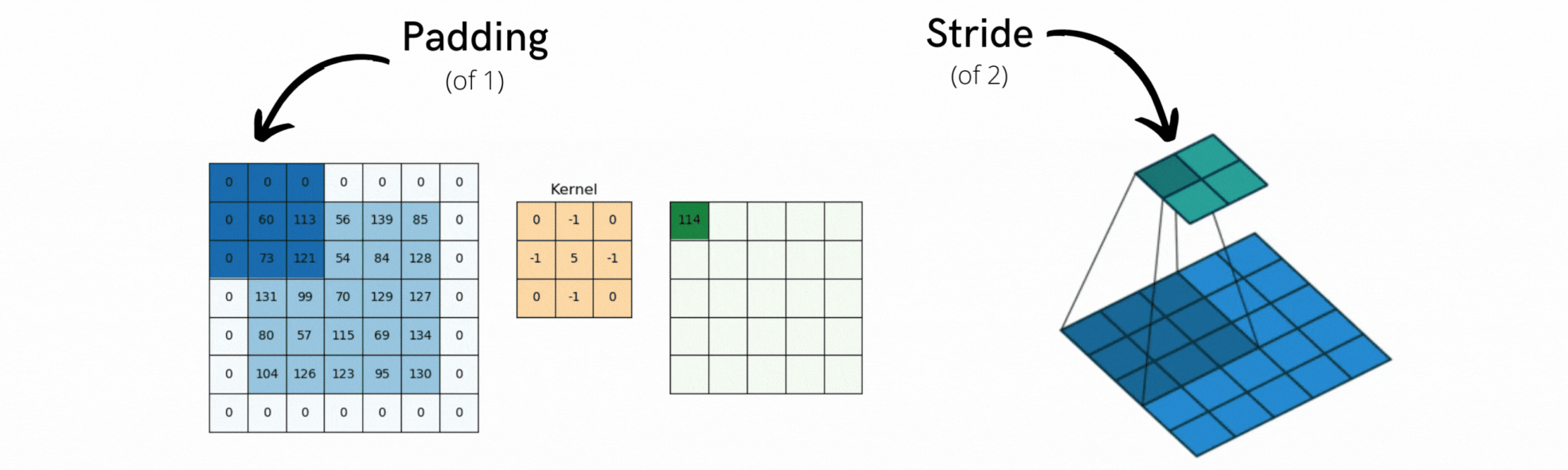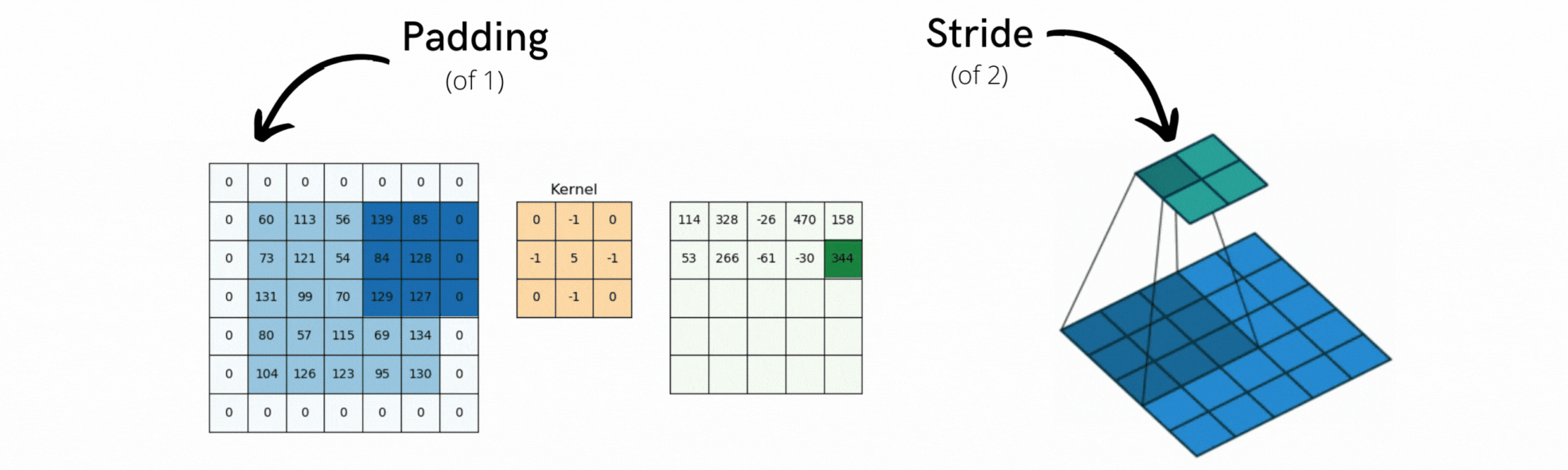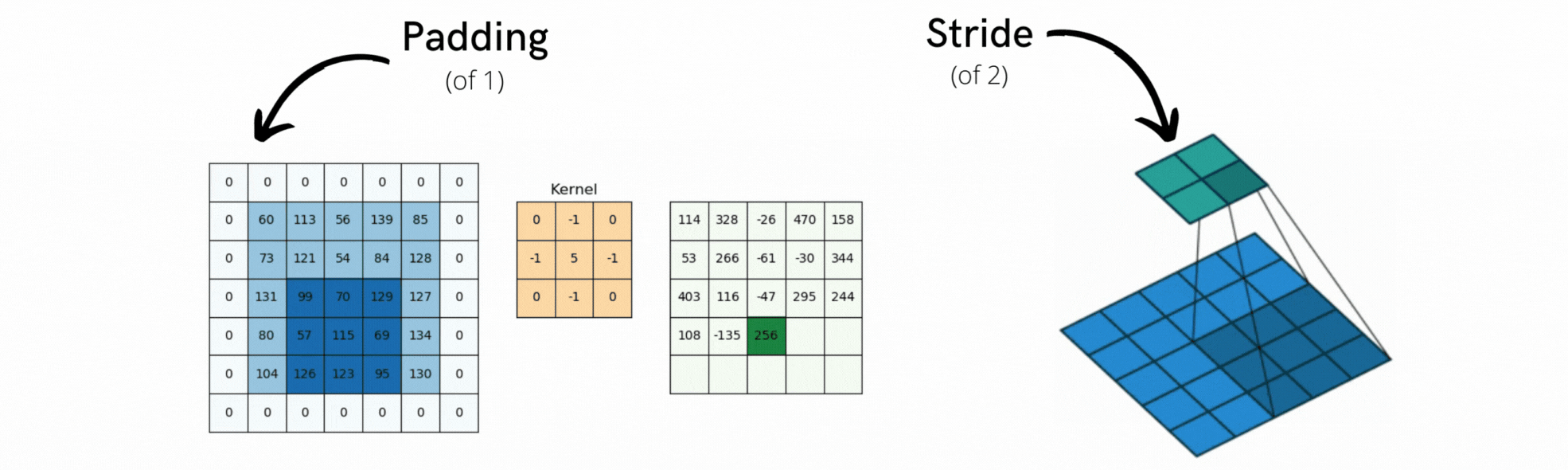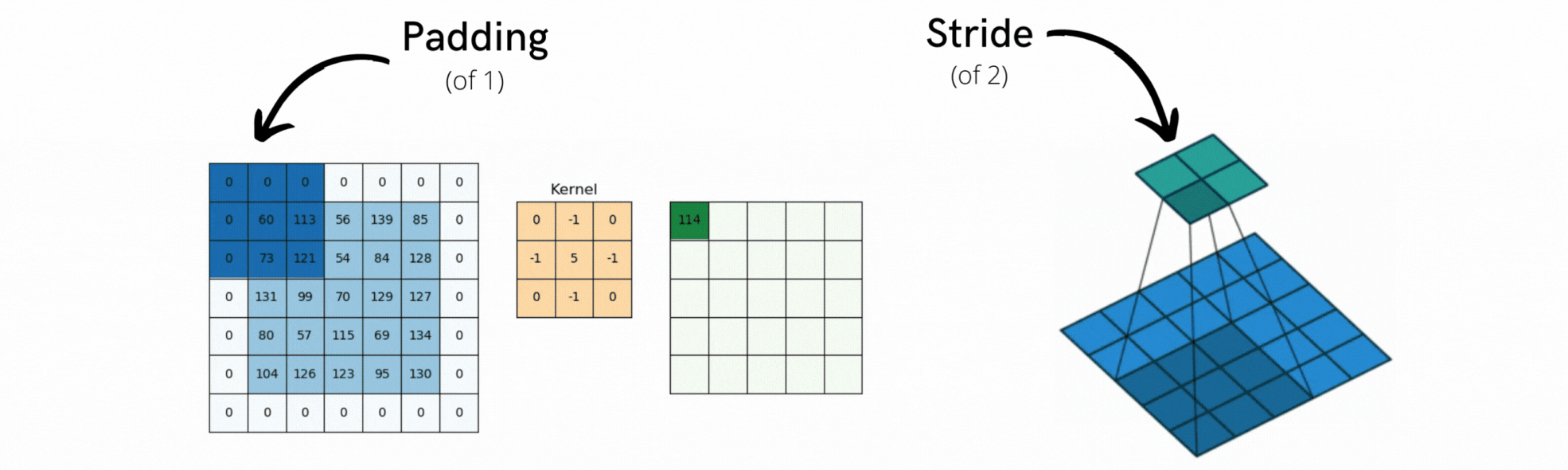
Jeśli chcemy uzyskać wyjściową mapę cech o takich samych wymiarach przestrzennych jak wejściowa, możemy użyć paddingu. Padding polega na dodaniu odpowiedniej liczby wierszy i kolumn po każdej stronie wejściowej mapy cech, tak aby umożliwić dopasowanie środkowych okien konwolucji wokół każdego kafelka wejściowego. Dla okna 3 × 3 dodamy jedną kolumnę po prawej, jedną kolumnę po lewej, jeden rząd na górze i jeden rząd na dole. Dla okna 5 × 5 dodalibyśmy dwa rzędy (patrz Rysunek 12.3).
W warstwach layer_conv_2dpadding jest konfigurowalny poprzez argument padding, który przyjmuje dwie wartości: valid, co oznacza brak paddingu (zostaną użyte tylko poprawne lokalizacje okien); oraz same, co oznacza “rozszerz wejście w taki sposób, aby mieć wyjście o takiej samej szerokości i wysokości jak wejście”. Argument padding domyślnie przyjmuje wartość valid.
Rysunek 12.4: Przykłady paddingu i konwolucji kroczącej
12.1.2 Efekty brzegowe - stirdes
Innym czynnikiem, który może wpływać na wielkość wyjścia jest pojęcie pasków (ang. strides). Dotychczasowy opis konwolucji zakładał, że wszystkie środkowe kwadraty okien konwolucji są przylegające. Jednak odległość między dwoma kolejnymi oknami jest parametrem konwolucji, zwanym jej paskiem, który domyślnie wynosi 1. Możliwe jest istnienie konwolucji paskowych: konwolucji o pasku większym niż jeden. Na Rysunek 12.4 widać części wyekstrahowane przez konwolucję 3 x 3 z paskiem 2 na wejściu 5 × 5 (bez wypełnienia). Użycie paska o szerokości 2 oznacza, że szerokość i wysokość mapy cech są pomniejszane o współczynnik 2 (oprócz zmian wywołanych przez efekty brzegowe). Konwolucje z paskami są rzadko używane w praktyce, choć mogą być przydatne w niektórych typach modeli; dobrze jest zapoznać się z tą koncepcją. Do downsamplingu map cech, zamiast kroków, używamy zwykle operacji maxpooling, którą zastosowaliśmy w sieci do przykładu MNIST. Przyjrzyjmy się jej bardziej szczegółowo.
12.2 Max pooling
W przykładzie MNIST mogliśmy zauważyć, że rozmiar map cech jest zmniejszany o połowę po każdej operacji layer_max_pooling_2d. Na przykład przed pierwszą layer_max_pooling_2d mapa cech ma rozmiar 26 × 26, ale operacja maxpoolingu zmniejsza ją o połowę do 13 × 13. Taka jest właśnie rola max poolingu: agresywne zmniejszanie próbkowania map cech, podobnie jak w przypadku konwolucji krokowych.
Operacja max pooling polega na wyodrębnieniu okien z wejściowych map cech i wyprowadzeniu maksymalnej wartości każdego filtra. Koncepcyjnie jest to podobne do konwolucji, z tą różnicą, że zamiast przekształcać lokalne łaty poprzez wyuczone przekształcenie liniowe (jądro konwolucji), są one przekształcane poprzez zakodowaną operację max tensora. Dużą różnicą w stosunku do konwolucji jest to, że max pooling jest zwykle wykonywany z oknami 2 × 2 i krokiem 2, w celu zmniejszenia próbkowania map cech o współczynnik 2. Z drugiej strony, konwolucja jest zwykle wykonywana z oknami 3 × 3 i bez kroku (stride 1).
Dlaczego obniżamy rozmiar mapy cech w ten sposób? Dlaczego nie usunąć warstw max pooling i zachować dość duże mapy funkcji przez całą sieć? Przyjrzyjmy się tej opcji. Konwolucyjna baza modelu wyglądałaby wtedy tak:
Nie sprzyja uczeniu się przestrzennej hierarchii cech. Okna 3 × 3 w trzecich warstwach będą zawierały jedynie informacje pochodzące z okien 7 × 7 wejścia początkowego. Wzorce wysokopoziomowe wyuczone przez sieć splotową będą nadal bardzo małe w stosunku do początkowego wejścia, co może nie wystarczyć do klasyfikacji cyfr (spróbujmy rozpoznać cyfrę, patrząc na nią tylko przez okna o wymiarach 7 × 7 pikseli!). Potrzebujemy, aby cechy z ostatniej warstwy konwolucji zawierały informacje o całości danych wejściowych.
Ostateczna mapa cech ma 22 * 22 * 64 = 30976 wszystkich współczynników na próbkę. Jest to ogromna ilość. Jeśli mielibyśmy ją spłaszczyć, aby dołączyć gęstą warstwę o rozmiarze 512, ta warstwa miałaby 15,8 miliona parametrów. Jest to zdecydowanie zbyt dużo dla tak małego modelu i spowodowałoby przeuczenie.
W skrócie, powodem użycia redukcji wymiaru jest zmniejszenie liczby współczynników mapy cech do przetworzenia, jak również wywołanie hierarchii filtrów przestrzennych poprzez sprawienie, że kolejne warstwy konwolucji będą patrzyły na coraz większe okna (w sensie ułamka oryginalnego wejścia, które obejmują).
Zauważmy, że max pooling nie jest jedynym sposobem, w jaki możemy osiągnąć taką redukcję wymiaru. Możemy też użyć average pooling zamiast max pooling, gdzie każdy lokalny fragment wejściowy jest przekształcany przez użycie średniej wartości każdego filtra w tym fragmencie, a nie maksimum. Mimo to, max pooling jest preferowanym rozwiązaniem ponieważ często daje lepsze rezultaty. W skrócie, powodem jest to, że cechy mają tendencję do kodowania przestrzennej obecności jakiegoś wzoru lub koncepcji w różnych kaflach mapy cech (stąd termin mapa cech), a bardziej informatywne jest spojrzenie na maksymalną obecność różnych cech niż na ich średnią obecność. Tak więc najrozsądniejszą strategią redukcji wymiaru jest najpierw wytworzenie map cech, a następnie spojrzenie na maksymalną aktywację cech w małych fragmentach, a nie patrzenie na rzadsze okna wejść lub uśrednianie fragmentów wejściowych, co może spowodować przegapienie lub rozmycie informacji o obecności cech.
Poniżej zaprezentowane są wyniki działania poszczególnych warstw sieci konwolucyjnej.
Rysunek 12.5: Wyniki filtracji pierwszą warstwą splotową (wybrano filtry 4 i 10)
Rysunek 12.6: Wyniki filtracji pierwszą warstwą splotową (wybrano filtry 4 i 10)
Rysunek 12.7: Wyniki filtracji pierwszą warstwą splotową (wybrano filtry 4 i 10)
Tak wygląda wynik pierwszej warstwy splotowej dla wybranych dwóch filtrów (kanałów), a jakby to wyglądało gdyby wyświetlić wyniki wszystkich warstw i kanałów.