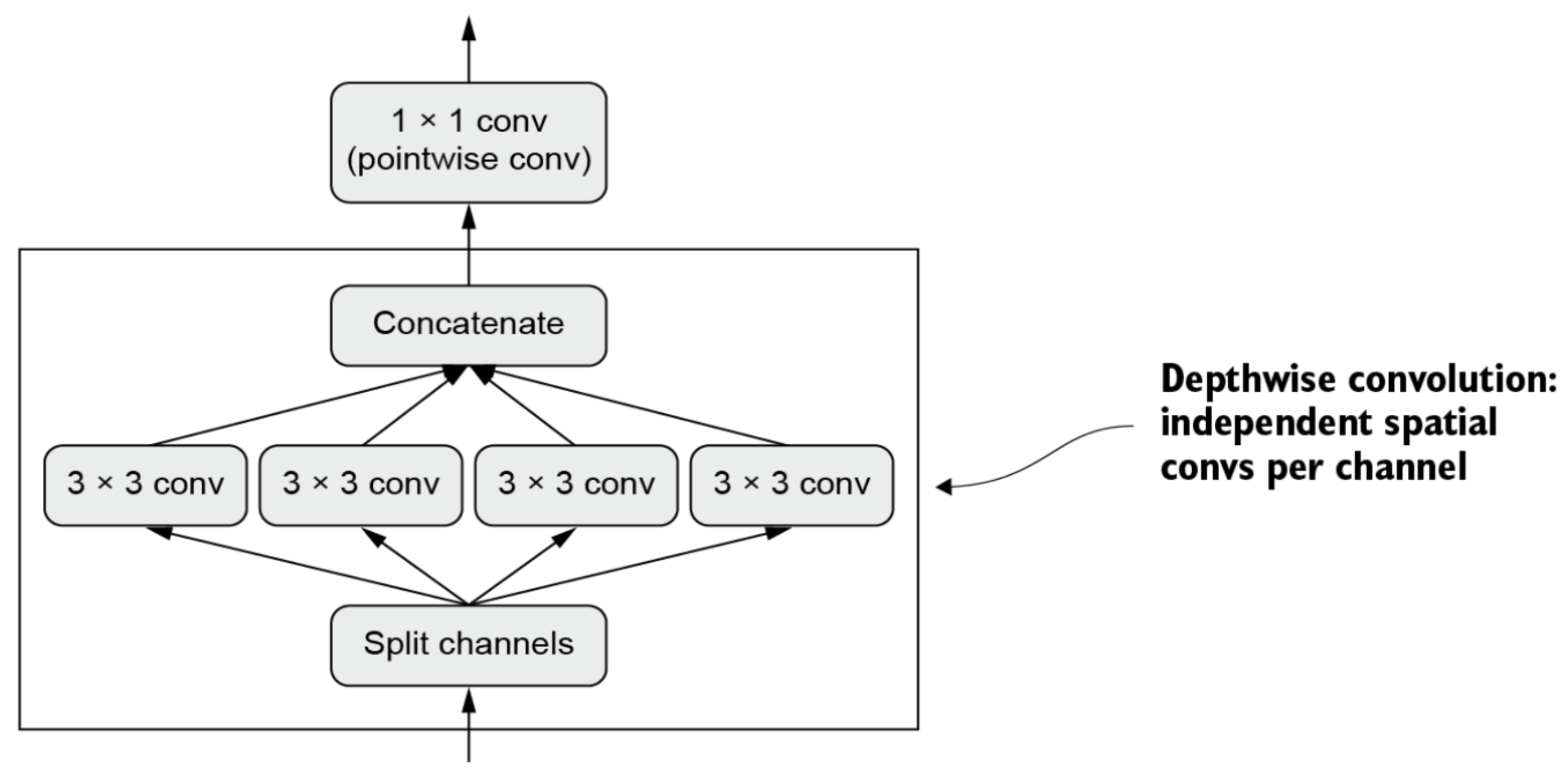
Model: "efficientnetb0"
________________________________________________________________________________
Layer (type) Output Shape Para Connected to Trainable
m #
================================================================================
input_5 (InputLay [(None, 224, 224, 0 [] Y
er) 3)]
rescaling_2 (Resc (None, 224, 224, 3 0 ['input_5[0][0]'] Y
aling) )
normalization (No (None, 224, 224, 3 7 ['rescaling_2[0][0 Y
rmalization) ) ]']
rescaling_3 (Resc (None, 224, 224, 3 0 ['normalization[0] Y
aling) ) [0]']
stem_conv_pad (Ze (None, 225, 225, 3 0 ['rescaling_3[0][0 Y
roPadding2D) ) ]']
stem_conv (Conv2D (None, 112, 112, 3 864 ['stem_conv_pad[0] Y
) 2) [0]']
stem_bn (BatchNor (None, 112, 112, 3 128 ['stem_conv[0][0]' N
malization) 2) ]
stem_activation ( (None, 112, 112, 3 0 ['stem_bn[0][0]'] Y
Activation) 2)
block1a_dwconv (D (None, 112, 112, 3 288 ['stem_activation[ Y
epthwiseConv2D) 2) 0][0]']
block1a_bn (Batch (None, 112, 112, 3 128 ['block1a_dwconv[0 N
Normalization) 2) ][0]']
block1a_activatio (None, 112, 112, 3 0 ['block1a_bn[0][0] Y
n (Activation) 2) ']
block1a_se_squeez (None, 32) 0 ['block1a_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block1a_se_reshap (None, 1, 1, 32) 0 ['block1a_se_squee Y
e (Reshape) ze[0][0]']
block1a_se_reduce (None, 1, 1, 8) 264 ['block1a_se_resha Y
(Conv2D) pe[0][0]']
block1a_se_expand (None, 1, 1, 32) 288 ['block1a_se_reduc Y
(Conv2D) e[0][0]']
block1a_se_excite (None, 112, 112, 3 0 ['block1a_activati Y
(Multiply) 2) on[0][0]',
'block1a_se_expan
d[0][0]']
block1a_project_c (None, 112, 112, 1 512 ['block1a_se_excit Y
onv (Conv2D) 6) e[0][0]']
block1a_project_b (None, 112, 112, 1 64 ['block1a_project_ N
n (BatchNormaliza 6) conv[0][0]']
tion)
block2a_expand_co (None, 112, 112, 9 1536 ['block1a_project_ Y
nv (Conv2D) 6) bn[0][0]']
block2a_expand_bn (None, 112, 112, 9 384 ['block2a_expand_c N
(BatchNormalizat 6) onv[0][0]']
ion)
block2a_expand_ac (None, 112, 112, 9 0 ['block2a_expand_b Y
tivation (Activat 6) n[0][0]']
ion)
block2a_dwconv_pa (None, 113, 113, 9 0 ['block2a_expand_a Y
d (ZeroPadding2D) 6) ctivation[0][0]']
block2a_dwconv (D (None, 56, 56, 96) 864 ['block2a_dwconv_p Y
epthwiseConv2D) ad[0][0]']
block2a_bn (Batch (None, 56, 56, 96) 384 ['block2a_dwconv[0 N
Normalization) ][0]']
block2a_activatio (None, 56, 56, 96) 0 ['block2a_bn[0][0] Y
n (Activation) ']
block2a_se_squeez (None, 96) 0 ['block2a_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block2a_se_reshap (None, 1, 1, 96) 0 ['block2a_se_squee Y
e (Reshape) ze[0][0]']
block2a_se_reduce (None, 1, 1, 4) 388 ['block2a_se_resha Y
(Conv2D) pe[0][0]']
block2a_se_expand (None, 1, 1, 96) 480 ['block2a_se_reduc Y
(Conv2D) e[0][0]']
block2a_se_excite (None, 56, 56, 96) 0 ['block2a_activati Y
(Multiply) on[0][0]',
'block2a_se_expan
d[0][0]']
block2a_project_c (None, 56, 56, 24) 2304 ['block2a_se_excit Y
onv (Conv2D) e[0][0]']
block2a_project_b (None, 56, 56, 24) 96 ['block2a_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block2b_expand_co (None, 56, 56, 144 3456 ['block2a_project_ Y
nv (Conv2D) ) bn[0][0]']
block2b_expand_bn (None, 56, 56, 144 576 ['block2b_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block2b_expand_ac (None, 56, 56, 144 0 ['block2b_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block2b_dwconv (D (None, 56, 56, 144 1296 ['block2b_expand_a Y
epthwiseConv2D) ) ctivation[0][0]']
block2b_bn (Batch (None, 56, 56, 144 576 ['block2b_dwconv[0 N
Normalization) ) ][0]']
block2b_activatio (None, 56, 56, 144 0 ['block2b_bn[0][0] Y
n (Activation) ) ']
block2b_se_squeez (None, 144) 0 ['block2b_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block2b_se_reshap (None, 1, 1, 144) 0 ['block2b_se_squee Y
e (Reshape) ze[0][0]']
block2b_se_reduce (None, 1, 1, 6) 870 ['block2b_se_resha Y
(Conv2D) pe[0][0]']
block2b_se_expand (None, 1, 1, 144) 1008 ['block2b_se_reduc Y
(Conv2D) e[0][0]']
block2b_se_excite (None, 56, 56, 144 0 ['block2b_activati Y
(Multiply) ) on[0][0]',
'block2b_se_expan
d[0][0]']
block2b_project_c (None, 56, 56, 24) 3456 ['block2b_se_excit Y
onv (Conv2D) e[0][0]']
block2b_project_b (None, 56, 56, 24) 96 ['block2b_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block2b_drop (Dro (None, 56, 56, 24) 0 ['block2b_project_ Y
pout) bn[0][0]']
block2b_add (Add) (None, 56, 56, 24) 0 ['block2b_drop[0][ Y
0]',
'block2a_project_
bn[0][0]']
block3a_expand_co (None, 56, 56, 144 3456 ['block2b_add[0][0 Y
nv (Conv2D) ) ]']
block3a_expand_bn (None, 56, 56, 144 576 ['block3a_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block3a_expand_ac (None, 56, 56, 144 0 ['block3a_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block3a_dwconv_pa (None, 59, 59, 144 0 ['block3a_expand_a Y
d (ZeroPadding2D) ) ctivation[0][0]']
block3a_dwconv (D (None, 28, 28, 144 3600 ['block3a_dwconv_p Y
epthwiseConv2D) ) ad[0][0]']
block3a_bn (Batch (None, 28, 28, 144 576 ['block3a_dwconv[0 N
Normalization) ) ][0]']
block3a_activatio (None, 28, 28, 144 0 ['block3a_bn[0][0] Y
n (Activation) ) ']
block3a_se_squeez (None, 144) 0 ['block3a_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block3a_se_reshap (None, 1, 1, 144) 0 ['block3a_se_squee Y
e (Reshape) ze[0][0]']
block3a_se_reduce (None, 1, 1, 6) 870 ['block3a_se_resha Y
(Conv2D) pe[0][0]']
block3a_se_expand (None, 1, 1, 144) 1008 ['block3a_se_reduc Y
(Conv2D) e[0][0]']
block3a_se_excite (None, 28, 28, 144 0 ['block3a_activati Y
(Multiply) ) on[0][0]',
'block3a_se_expan
d[0][0]']
block3a_project_c (None, 28, 28, 40) 5760 ['block3a_se_excit Y
onv (Conv2D) e[0][0]']
block3a_project_b (None, 28, 28, 40) 160 ['block3a_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block3b_expand_co (None, 28, 28, 240 9600 ['block3a_project_ Y
nv (Conv2D) ) bn[0][0]']
block3b_expand_bn (None, 28, 28, 240 960 ['block3b_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block3b_expand_ac (None, 28, 28, 240 0 ['block3b_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block3b_dwconv (D (None, 28, 28, 240 6000 ['block3b_expand_a Y
epthwiseConv2D) ) ctivation[0][0]']
block3b_bn (Batch (None, 28, 28, 240 960 ['block3b_dwconv[0 N
Normalization) ) ][0]']
block3b_activatio (None, 28, 28, 240 0 ['block3b_bn[0][0] Y
n (Activation) ) ']
block3b_se_squeez (None, 240) 0 ['block3b_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block3b_se_reshap (None, 1, 1, 240) 0 ['block3b_se_squee Y
e (Reshape) ze[0][0]']
block3b_se_reduce (None, 1, 1, 10) 2410 ['block3b_se_resha Y
(Conv2D) pe[0][0]']
block3b_se_expand (None, 1, 1, 240) 2640 ['block3b_se_reduc Y
(Conv2D) e[0][0]']
block3b_se_excite (None, 28, 28, 240 0 ['block3b_activati Y
(Multiply) ) on[0][0]',
'block3b_se_expan
d[0][0]']
block3b_project_c (None, 28, 28, 40) 9600 ['block3b_se_excit Y
onv (Conv2D) e[0][0]']
block3b_project_b (None, 28, 28, 40) 160 ['block3b_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block3b_drop (Dro (None, 28, 28, 40) 0 ['block3b_project_ Y
pout) bn[0][0]']
block3b_add (Add) (None, 28, 28, 40) 0 ['block3b_drop[0][ Y
0]',
'block3a_project_
bn[0][0]']
block4a_expand_co (None, 28, 28, 240 9600 ['block3b_add[0][0 Y
nv (Conv2D) ) ]']
block4a_expand_bn (None, 28, 28, 240 960 ['block4a_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block4a_expand_ac (None, 28, 28, 240 0 ['block4a_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block4a_dwconv_pa (None, 29, 29, 240 0 ['block4a_expand_a Y
d (ZeroPadding2D) ) ctivation[0][0]']
block4a_dwconv (D (None, 14, 14, 240 2160 ['block4a_dwconv_p Y
epthwiseConv2D) ) ad[0][0]']
block4a_bn (Batch (None, 14, 14, 240 960 ['block4a_dwconv[0 N
Normalization) ) ][0]']
block4a_activatio (None, 14, 14, 240 0 ['block4a_bn[0][0] Y
n (Activation) ) ']
block4a_se_squeez (None, 240) 0 ['block4a_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block4a_se_reshap (None, 1, 1, 240) 0 ['block4a_se_squee Y
e (Reshape) ze[0][0]']
block4a_se_reduce (None, 1, 1, 10) 2410 ['block4a_se_resha Y
(Conv2D) pe[0][0]']
block4a_se_expand (None, 1, 1, 240) 2640 ['block4a_se_reduc Y
(Conv2D) e[0][0]']
block4a_se_excite (None, 14, 14, 240 0 ['block4a_activati Y
(Multiply) ) on[0][0]',
'block4a_se_expan
d[0][0]']
block4a_project_c (None, 14, 14, 80) 1920 ['block4a_se_excit Y
onv (Conv2D) 0 e[0][0]']
block4a_project_b (None, 14, 14, 80) 320 ['block4a_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block4b_expand_co (None, 14, 14, 480 3840 ['block4a_project_ Y
nv (Conv2D) ) 0 bn[0][0]']
block4b_expand_bn (None, 14, 14, 480 1920 ['block4b_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block4b_expand_ac (None, 14, 14, 480 0 ['block4b_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block4b_dwconv (D (None, 14, 14, 480 4320 ['block4b_expand_a Y
epthwiseConv2D) ) ctivation[0][0]']
block4b_bn (Batch (None, 14, 14, 480 1920 ['block4b_dwconv[0 N
Normalization) ) ][0]']
block4b_activatio (None, 14, 14, 480 0 ['block4b_bn[0][0] Y
n (Activation) ) ']
block4b_se_squeez (None, 480) 0 ['block4b_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block4b_se_reshap (None, 1, 1, 480) 0 ['block4b_se_squee Y
e (Reshape) ze[0][0]']
block4b_se_reduce (None, 1, 1, 20) 9620 ['block4b_se_resha Y
(Conv2D) pe[0][0]']
block4b_se_expand (None, 1, 1, 480) 1008 ['block4b_se_reduc Y
(Conv2D) 0 e[0][0]']
block4b_se_excite (None, 14, 14, 480 0 ['block4b_activati Y
(Multiply) ) on[0][0]',
'block4b_se_expan
d[0][0]']
block4b_project_c (None, 14, 14, 80) 3840 ['block4b_se_excit Y
onv (Conv2D) 0 e[0][0]']
block4b_project_b (None, 14, 14, 80) 320 ['block4b_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block4b_drop (Dro (None, 14, 14, 80) 0 ['block4b_project_ Y
pout) bn[0][0]']
block4b_add (Add) (None, 14, 14, 80) 0 ['block4b_drop[0][ Y
0]',
'block4a_project_
bn[0][0]']
block4c_expand_co (None, 14, 14, 480 3840 ['block4b_add[0][0 Y
nv (Conv2D) ) 0 ]']
block4c_expand_bn (None, 14, 14, 480 1920 ['block4c_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block4c_expand_ac (None, 14, 14, 480 0 ['block4c_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block4c_dwconv (D (None, 14, 14, 480 4320 ['block4c_expand_a Y
epthwiseConv2D) ) ctivation[0][0]']
block4c_bn (Batch (None, 14, 14, 480 1920 ['block4c_dwconv[0 N
Normalization) ) ][0]']
block4c_activatio (None, 14, 14, 480 0 ['block4c_bn[0][0] Y
n (Activation) ) ']
block4c_se_squeez (None, 480) 0 ['block4c_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block4c_se_reshap (None, 1, 1, 480) 0 ['block4c_se_squee Y
e (Reshape) ze[0][0]']
block4c_se_reduce (None, 1, 1, 20) 9620 ['block4c_se_resha Y
(Conv2D) pe[0][0]']
block4c_se_expand (None, 1, 1, 480) 1008 ['block4c_se_reduc Y
(Conv2D) 0 e[0][0]']
block4c_se_excite (None, 14, 14, 480 0 ['block4c_activati Y
(Multiply) ) on[0][0]',
'block4c_se_expan
d[0][0]']
block4c_project_c (None, 14, 14, 80) 3840 ['block4c_se_excit Y
onv (Conv2D) 0 e[0][0]']
block4c_project_b (None, 14, 14, 80) 320 ['block4c_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block4c_drop (Dro (None, 14, 14, 80) 0 ['block4c_project_ Y
pout) bn[0][0]']
block4c_add (Add) (None, 14, 14, 80) 0 ['block4c_drop[0][ Y
0]',
'block4b_add[0][0
]']
block5a_expand_co (None, 14, 14, 480 3840 ['block4c_add[0][0 Y
nv (Conv2D) ) 0 ]']
block5a_expand_bn (None, 14, 14, 480 1920 ['block5a_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block5a_expand_ac (None, 14, 14, 480 0 ['block5a_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block5a_dwconv (D (None, 14, 14, 480 1200 ['block5a_expand_a Y
epthwiseConv2D) ) 0 ctivation[0][0]']
block5a_bn (Batch (None, 14, 14, 480 1920 ['block5a_dwconv[0 N
Normalization) ) ][0]']
block5a_activatio (None, 14, 14, 480 0 ['block5a_bn[0][0] Y
n (Activation) ) ']
block5a_se_squeez (None, 480) 0 ['block5a_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block5a_se_reshap (None, 1, 1, 480) 0 ['block5a_se_squee Y
e (Reshape) ze[0][0]']
block5a_se_reduce (None, 1, 1, 20) 9620 ['block5a_se_resha Y
(Conv2D) pe[0][0]']
block5a_se_expand (None, 1, 1, 480) 1008 ['block5a_se_reduc Y
(Conv2D) 0 e[0][0]']
block5a_se_excite (None, 14, 14, 480 0 ['block5a_activati Y
(Multiply) ) on[0][0]',
'block5a_se_expan
d[0][0]']
block5a_project_c (None, 14, 14, 112 5376 ['block5a_se_excit Y
onv (Conv2D) ) 0 e[0][0]']
block5a_project_b (None, 14, 14, 112 448 ['block5a_project_ N
n (BatchNormaliza ) conv[0][0]']
tion)
block5b_expand_co (None, 14, 14, 672 7526 ['block5a_project_ Y
nv (Conv2D) ) 4 bn[0][0]']
block5b_expand_bn (None, 14, 14, 672 2688 ['block5b_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block5b_expand_ac (None, 14, 14, 672 0 ['block5b_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block5b_dwconv (D (None, 14, 14, 672 1680 ['block5b_expand_a Y
epthwiseConv2D) ) 0 ctivation[0][0]']
block5b_bn (Batch (None, 14, 14, 672 2688 ['block5b_dwconv[0 N
Normalization) ) ][0]']
block5b_activatio (None, 14, 14, 672 0 ['block5b_bn[0][0] Y
n (Activation) ) ']
block5b_se_squeez (None, 672) 0 ['block5b_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block5b_se_reshap (None, 1, 1, 672) 0 ['block5b_se_squee Y
e (Reshape) ze[0][0]']
block5b_se_reduce (None, 1, 1, 28) 1884 ['block5b_se_resha Y
(Conv2D) 4 pe[0][0]']
block5b_se_expand (None, 1, 1, 672) 1948 ['block5b_se_reduc Y
(Conv2D) 8 e[0][0]']
block5b_se_excite (None, 14, 14, 672 0 ['block5b_activati Y
(Multiply) ) on[0][0]',
'block5b_se_expan
d[0][0]']
block5b_project_c (None, 14, 14, 112 7526 ['block5b_se_excit Y
onv (Conv2D) ) 4 e[0][0]']
block5b_project_b (None, 14, 14, 112 448 ['block5b_project_ N
n (BatchNormaliza ) conv[0][0]']
tion)
block5b_drop (Dro (None, 14, 14, 112 0 ['block5b_project_ Y
pout) ) bn[0][0]']
block5b_add (Add) (None, 14, 14, 112 0 ['block5b_drop[0][ Y
) 0]',
'block5a_project_
bn[0][0]']
block5c_expand_co (None, 14, 14, 672 7526 ['block5b_add[0][0 Y
nv (Conv2D) ) 4 ]']
block5c_expand_bn (None, 14, 14, 672 2688 ['block5c_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block5c_expand_ac (None, 14, 14, 672 0 ['block5c_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block5c_dwconv (D (None, 14, 14, 672 1680 ['block5c_expand_a Y
epthwiseConv2D) ) 0 ctivation[0][0]']
block5c_bn (Batch (None, 14, 14, 672 2688 ['block5c_dwconv[0 N
Normalization) ) ][0]']
block5c_activatio (None, 14, 14, 672 0 ['block5c_bn[0][0] Y
n (Activation) ) ']
block5c_se_squeez (None, 672) 0 ['block5c_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block5c_se_reshap (None, 1, 1, 672) 0 ['block5c_se_squee Y
e (Reshape) ze[0][0]']
block5c_se_reduce (None, 1, 1, 28) 1884 ['block5c_se_resha Y
(Conv2D) 4 pe[0][0]']
block5c_se_expand (None, 1, 1, 672) 1948 ['block5c_se_reduc Y
(Conv2D) 8 e[0][0]']
block5c_se_excite (None, 14, 14, 672 0 ['block5c_activati Y
(Multiply) ) on[0][0]',
'block5c_se_expan
d[0][0]']
block5c_project_c (None, 14, 14, 112 7526 ['block5c_se_excit Y
onv (Conv2D) ) 4 e[0][0]']
block5c_project_b (None, 14, 14, 112 448 ['block5c_project_ N
n (BatchNormaliza ) conv[0][0]']
tion)
block5c_drop (Dro (None, 14, 14, 112 0 ['block5c_project_ Y
pout) ) bn[0][0]']
block5c_add (Add) (None, 14, 14, 112 0 ['block5c_drop[0][ Y
) 0]',
'block5b_add[0][0
]']
block6a_expand_co (None, 14, 14, 672 7526 ['block5c_add[0][0 Y
nv (Conv2D) ) 4 ]']
block6a_expand_bn (None, 14, 14, 672 2688 ['block6a_expand_c N
(BatchNormalizat ) onv[0][0]']
ion)
block6a_expand_ac (None, 14, 14, 672 0 ['block6a_expand_b Y
tivation (Activat ) n[0][0]']
ion)
block6a_dwconv_pa (None, 17, 17, 672 0 ['block6a_expand_a Y
d (ZeroPadding2D) ) ctivation[0][0]']
block6a_dwconv (D (None, 7, 7, 672) 1680 ['block6a_dwconv_p Y
epthwiseConv2D) 0 ad[0][0]']
block6a_bn (Batch (None, 7, 7, 672) 2688 ['block6a_dwconv[0 N
Normalization) ][0]']
block6a_activatio (None, 7, 7, 672) 0 ['block6a_bn[0][0] Y
n (Activation) ']
block6a_se_squeez (None, 672) 0 ['block6a_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block6a_se_reshap (None, 1, 1, 672) 0 ['block6a_se_squee Y
e (Reshape) ze[0][0]']
block6a_se_reduce (None, 1, 1, 28) 1884 ['block6a_se_resha Y
(Conv2D) 4 pe[0][0]']
block6a_se_expand (None, 1, 1, 672) 1948 ['block6a_se_reduc Y
(Conv2D) 8 e[0][0]']
block6a_se_excite (None, 7, 7, 672) 0 ['block6a_activati Y
(Multiply) on[0][0]',
'block6a_se_expan
d[0][0]']
block6a_project_c (None, 7, 7, 192) 1290 ['block6a_se_excit Y
onv (Conv2D) 24 e[0][0]']
block6a_project_b (None, 7, 7, 192) 768 ['block6a_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block6b_expand_co (None, 7, 7, 1152) 2211 ['block6a_project_ Y
nv (Conv2D) 84 bn[0][0]']
block6b_expand_bn (None, 7, 7, 1152) 4608 ['block6b_expand_c N
(BatchNormalizat onv[0][0]']
ion)
block6b_expand_ac (None, 7, 7, 1152) 0 ['block6b_expand_b Y
tivation (Activat n[0][0]']
ion)
block6b_dwconv (D (None, 7, 7, 1152) 2880 ['block6b_expand_a Y
epthwiseConv2D) 0 ctivation[0][0]']
block6b_bn (Batch (None, 7, 7, 1152) 4608 ['block6b_dwconv[0 N
Normalization) ][0]']
block6b_activatio (None, 7, 7, 1152) 0 ['block6b_bn[0][0] Y
n (Activation) ']
block6b_se_squeez (None, 1152) 0 ['block6b_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block6b_se_reshap (None, 1, 1, 1152) 0 ['block6b_se_squee Y
e (Reshape) ze[0][0]']
block6b_se_reduce (None, 1, 1, 48) 5534 ['block6b_se_resha Y
(Conv2D) 4 pe[0][0]']
block6b_se_expand (None, 1, 1, 1152) 5644 ['block6b_se_reduc Y
(Conv2D) 8 e[0][0]']
block6b_se_excite (None, 7, 7, 1152) 0 ['block6b_activati Y
(Multiply) on[0][0]',
'block6b_se_expan
d[0][0]']
block6b_project_c (None, 7, 7, 192) 2211 ['block6b_se_excit Y
onv (Conv2D) 84 e[0][0]']
block6b_project_b (None, 7, 7, 192) 768 ['block6b_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block6b_drop (Dro (None, 7, 7, 192) 0 ['block6b_project_ Y
pout) bn[0][0]']
block6b_add (Add) (None, 7, 7, 192) 0 ['block6b_drop[0][ Y
0]',
'block6a_project_
bn[0][0]']
block6c_expand_co (None, 7, 7, 1152) 2211 ['block6b_add[0][0 Y
nv (Conv2D) 84 ]']
block6c_expand_bn (None, 7, 7, 1152) 4608 ['block6c_expand_c N
(BatchNormalizat onv[0][0]']
ion)
block6c_expand_ac (None, 7, 7, 1152) 0 ['block6c_expand_b Y
tivation (Activat n[0][0]']
ion)
block6c_dwconv (D (None, 7, 7, 1152) 2880 ['block6c_expand_a Y
epthwiseConv2D) 0 ctivation[0][0]']
block6c_bn (Batch (None, 7, 7, 1152) 4608 ['block6c_dwconv[0 N
Normalization) ][0]']
block6c_activatio (None, 7, 7, 1152) 0 ['block6c_bn[0][0] Y
n (Activation) ']
block6c_se_squeez (None, 1152) 0 ['block6c_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block6c_se_reshap (None, 1, 1, 1152) 0 ['block6c_se_squee Y
e (Reshape) ze[0][0]']
block6c_se_reduce (None, 1, 1, 48) 5534 ['block6c_se_resha Y
(Conv2D) 4 pe[0][0]']
block6c_se_expand (None, 1, 1, 1152) 5644 ['block6c_se_reduc Y
(Conv2D) 8 e[0][0]']
block6c_se_excite (None, 7, 7, 1152) 0 ['block6c_activati Y
(Multiply) on[0][0]',
'block6c_se_expan
d[0][0]']
block6c_project_c (None, 7, 7, 192) 2211 ['block6c_se_excit Y
onv (Conv2D) 84 e[0][0]']
block6c_project_b (None, 7, 7, 192) 768 ['block6c_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block6c_drop (Dro (None, 7, 7, 192) 0 ['block6c_project_ Y
pout) bn[0][0]']
block6c_add (Add) (None, 7, 7, 192) 0 ['block6c_drop[0][ Y
0]',
'block6b_add[0][0
]']
block6d_expand_co (None, 7, 7, 1152) 2211 ['block6c_add[0][0 Y
nv (Conv2D) 84 ]']
block6d_expand_bn (None, 7, 7, 1152) 4608 ['block6d_expand_c N
(BatchNormalizat onv[0][0]']
ion)
block6d_expand_ac (None, 7, 7, 1152) 0 ['block6d_expand_b Y
tivation (Activat n[0][0]']
ion)
block6d_dwconv (D (None, 7, 7, 1152) 2880 ['block6d_expand_a Y
epthwiseConv2D) 0 ctivation[0][0]']
block6d_bn (Batch (None, 7, 7, 1152) 4608 ['block6d_dwconv[0 N
Normalization) ][0]']
block6d_activatio (None, 7, 7, 1152) 0 ['block6d_bn[0][0] Y
n (Activation) ']
block6d_se_squeez (None, 1152) 0 ['block6d_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block6d_se_reshap (None, 1, 1, 1152) 0 ['block6d_se_squee Y
e (Reshape) ze[0][0]']
block6d_se_reduce (None, 1, 1, 48) 5534 ['block6d_se_resha Y
(Conv2D) 4 pe[0][0]']
block6d_se_expand (None, 1, 1, 1152) 5644 ['block6d_se_reduc Y
(Conv2D) 8 e[0][0]']
block6d_se_excite (None, 7, 7, 1152) 0 ['block6d_activati Y
(Multiply) on[0][0]',
'block6d_se_expan
d[0][0]']
block6d_project_c (None, 7, 7, 192) 2211 ['block6d_se_excit Y
onv (Conv2D) 84 e[0][0]']
block6d_project_b (None, 7, 7, 192) 768 ['block6d_project_ N
n (BatchNormaliza conv[0][0]']
tion)
block6d_drop (Dro (None, 7, 7, 192) 0 ['block6d_project_ Y
pout) bn[0][0]']
block6d_add (Add) (None, 7, 7, 192) 0 ['block6d_drop[0][ Y
0]',
'block6c_add[0][0
]']
block7a_expand_co (None, 7, 7, 1152) 2211 ['block6d_add[0][0 Y
nv (Conv2D) 84 ]']
block7a_expand_bn (None, 7, 7, 1152) 4608 ['block7a_expand_c N
(BatchNormalizat onv[0][0]']
ion)
block7a_expand_ac (None, 7, 7, 1152) 0 ['block7a_expand_b Y
tivation (Activat n[0][0]']
ion)
block7a_dwconv (D (None, 7, 7, 1152) 1036 ['block7a_expand_a Y
epthwiseConv2D) 8 ctivation[0][0]']
block7a_bn (Batch (None, 7, 7, 1152) 4608 ['block7a_dwconv[0 N
Normalization) ][0]']
block7a_activatio (None, 7, 7, 1152) 0 ['block7a_bn[0][0] Y
n (Activation) ']
block7a_se_squeez (None, 1152) 0 ['block7a_activati Y
e (GlobalAverageP on[0][0]']
ooling2D)
block7a_se_reshap (None, 1, 1, 1152) 0 ['block7a_se_squee Y
e (Reshape) ze[0][0]']
block7a_se_reduce (None, 1, 1, 48) 5534 ['block7a_se_resha Y
(Conv2D) 4 pe[0][0]']
block7a_se_expand (None, 1, 1, 1152) 5644 ['block7a_se_reduc Y
(Conv2D) 8 e[0][0]']
block7a_se_excite (None, 7, 7, 1152) 0 ['block7a_activati Y
(Multiply) on[0][0]',
'block7a_se_expan
d[0][0]']
block7a_project_c (None, 7, 7, 320) 3686 ['block7a_se_excit Y
onv (Conv2D) 40 e[0][0]']
block7a_project_b (None, 7, 7, 320) 1280 ['block7a_project_ N
n (BatchNormaliza conv[0][0]']
tion)
top_conv (Conv2D) (None, 7, 7, 1280) 4096 ['block7a_project_ Y
00 bn[0][0]']
top_bn (BatchNorm (None, 7, 7, 1280) 5120 ['top_conv[0][0]'] N
alization)
top_activation (A (None, 7, 7, 1280) 0 ['top_bn[0][0]'] Y
ctivation)
avg_pool (GlobalA (None, 1280) 0 ['top_activation[0 Y
veragePooling2D) ][0]']
top_dropout (Drop (None, 1280) 0 ['avg_pool[0][0]'] Y
out)
predictions (Dens (None, 1000) 1281 ['top_dropout[0][0 Y
e) 000 ]']
================================================================================
Total params: 5330571 (20.33 MB)
Trainable params: 5246532 (20.01 MB)
Non-trainable params: 84039 (328.28 KB)
________________________________________________________________________________