Kod
Image. Width: 3024 pix Height: 4032 pix Depth: 1 Colour channels: 3 Obrazy w formie cyfrowej są obecnie powszechnie obowiązującym standardem przechowywania, wyświetlania i modyfikowania obrazów. Należy jednak wspomnieć, że jeszcze niedawno, bo na przełomie wieków aparaty i kamery cyfrowe były rzadkością i na rynku fotograficznym dominowały klasyczne obrazy wykonane na kliszy czy taśmie (w przypadku wideo). Fotografia analogowa, bo tak ją należy nazywać powstała w XIX wieku, jako efekt połączenia wielu wcześniejszych odkryć, takich jak:
wykorzystanie chlorku srebra przez Georga Fabricusa w 1556 r., który pod wpływem promieni słonecznych się zaczerniał,
światłoczułość azotanu srebra, którą zaobserwował Johann Heinrich Schulze (1724 r.),
Johann Heinrich Schulze uzyskał pierwsze odwzorowanie obrazu na emulsji światłoczułej sporządzonej z chlorku srebra na podkładzie z białej kredy (1725 r.),
pierwsza fotografia, stworzona przez Francuza Josepha-Nicéphore’a Niepce’a na wypolerowanej płycie metalowej (1826 r.),
1839 – rok uznawany za właściwą datę wynalezienia fotografii. Francuz Louis Jacques Daguerre zademonstrował Akademii Francuskiej zdjęcie fotograficzne otrzymane na warstewce jodku srebra, powstałej w wyniku działania pary jodu na wypolerowaną płytę miedzianą pokrytą srebrem,
w tym samym czasie nad otrzymywaniem obrazów tworzonych przez światło pracował angielski uczony William Henry Fox Talbot,
1861 – fizykowi Jamesowi Clerkowi Maxwellowi udało się uzyskać pierwszą trwałą fotografię barwną,
1907 – bracia Lumière wprowadzili na rynek pierwsze szklane kolorowe płyty światłoczułe do fotografii barwnej (Autochrome). Były one produkowane na bazie barwionej skrobi ziemniaczanej. Autochromy pomimo nowatorskiego użycia koloru miały swoje wady, to znaczy małą czułość, duże ziarno i konieczność używania statywu w przeciwieństwie do materiałów czarno-białych,
1935 – wprowadzono do sprzedaży pierwszy współczesny trójwarstwowy film barwny – Kodachrome,
większość współczesnych filmów barwnych, oprócz Kodachrome, wykorzystuje technologię stworzoną dla filmu Agfacolor w 1936 roku,
Od 1963 – dostępny jest film kolorowy firmy Polaroid Corporation pozwalający na niemal natychmiastowe odtworzenie sceny uchwyconej aparatem,
najpowszechniej stosowanym formatem zapisu analogowego obrazu wideo były taśmy VHS (ang. Video Home System) wprowadzone w 1976 roku przez firmę JVC. Nośnikiem używanym do zapisu zarówno obrazu, jak i dźwięku była taśma magnetyczna. Wcześniej tego rodzaju taśmy były wykorzystywane tylko do zapisywania dźwięku. Rozdzielczość pozioma obrazu w formacie VHS wynosi około 240 linii (dla obrazu kolorowego) i wynika z ograniczonego pasma dla sygnału koloru. Pod koniec lat 80 wprowadzono „ulepszoną” wersję VHS HQ, przy czym poprawiono w tej wersji głównie odczyt poprzez wprowadzenie systemu redukcji zakłóceń związanych z błędami odczytu taśmy (ang. dropout’s). Pozostałe parametry obrazu pozostały bez zmian. W formacie VHS fonia zapisywana jest wzdłuż taśmy przy krawędzi – przy przesuwie 2,239 cm/sek uzyskuje pasmo 80 Hz–10 kHz.
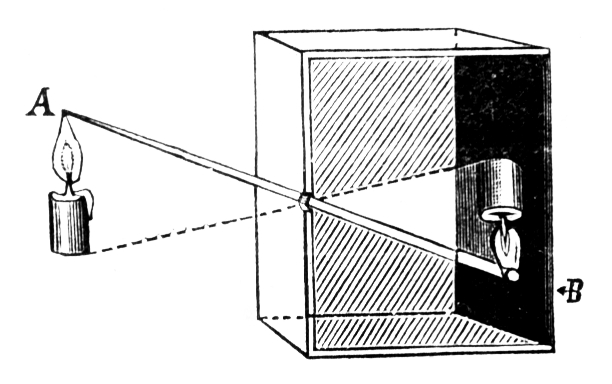
Chociaż prosta geometria kamery szczelinowej sprawia, że jest ona przydatna do zrozumienia podstawowych zasad tworzenia się obrazu, nigdy nie jest tak naprawdę wykorzystywana w praktyce. Jednym z problemów z kamerą szczelinową jest to, że wymaga ona bardzo małego otworu, aby uzyskać ostry obraz. To z kolei zmniejsza ilość przepuszczanego światła i prowadzi do ekstremalnie długich czasów naświetlania. W rzeczywistości stosuje się szklane soczewki lub systemy soczewek optycznych, których właściwości optyczne są znacznie lepsze w wielu aspektach, ale oczywiście są też znacznie bardziej złożone. W modelu (patrz Rysunek 3.1 (b)) zakłada się, że soczewka jest symetryczna i tak cienka, tak że wszystkie przechodzące przez nią promienie świetlne przecinają wirtualną płaszczyznę w środku soczewki. Wynikowa geometria obrazu jest taka sama jak w przypadku kamery szczelinowej. Model ten nie jest wystarczająco złożony, aby objąć fizyczne cechy rzeczywistych układów soczewek, takie jak zniekształcenia geometryczne i różne właściwości załamania światła w różnych kolorach. Tak więc, choć ten prosty model wystarcza do naszych celów (tj. zrozumienia mechaniki pozyskiwania obrazu), w literaturze można znaleźć znacznie bardziej szczegółowe modele uwzględniające te dodatkowe złożoności.
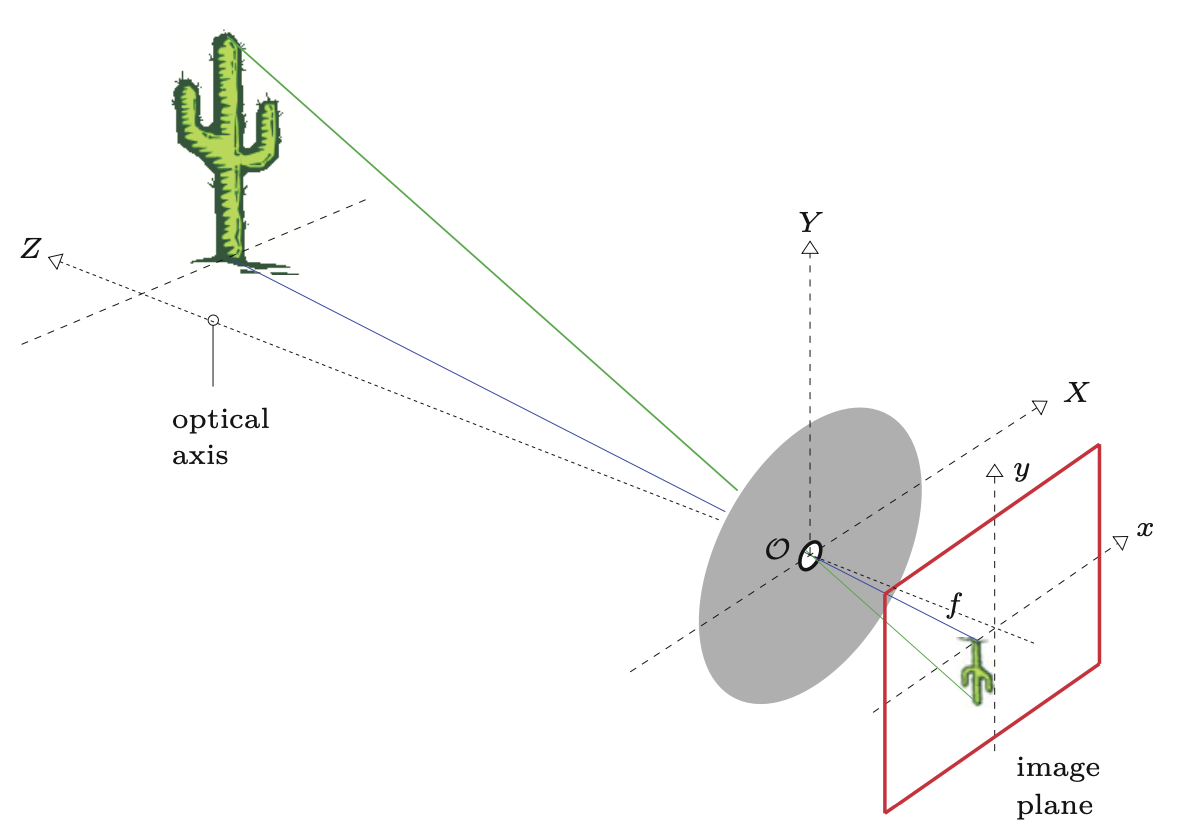
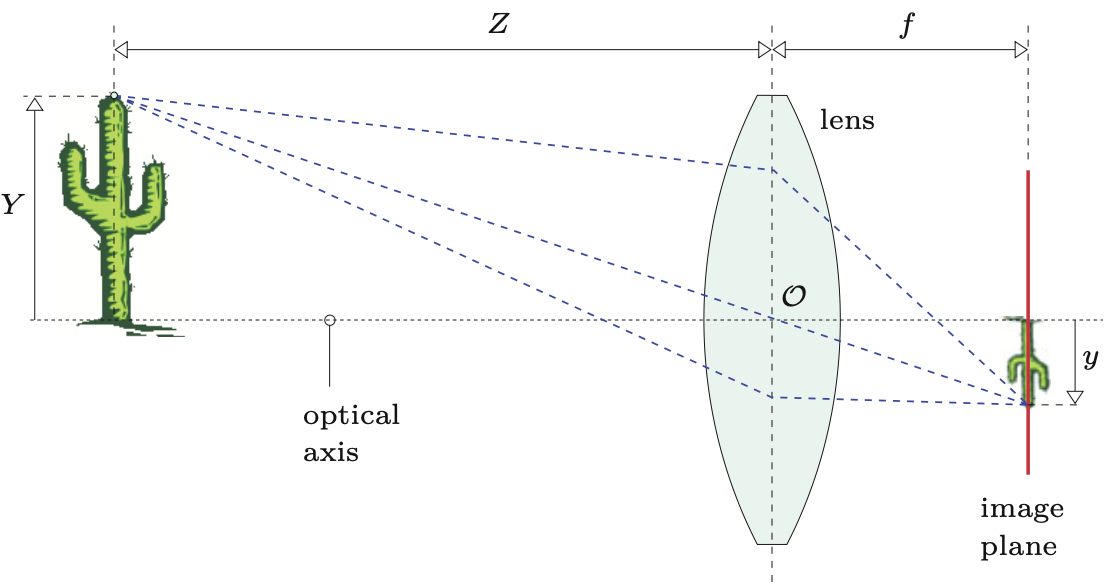
W przeciwieństwie do fotografii analogowej, fotografia cyfrowa nie wykorzystuje substancji chemicznej do utrwalenia obrazu ale zapisuje energię świetlną dostarczaną przez obiektyw do matrycy światłoczułej. Aby przekształcić ten obraz w obraz cyfrowy na naszym komputerze, konieczne są następujące trzy główne kroki:
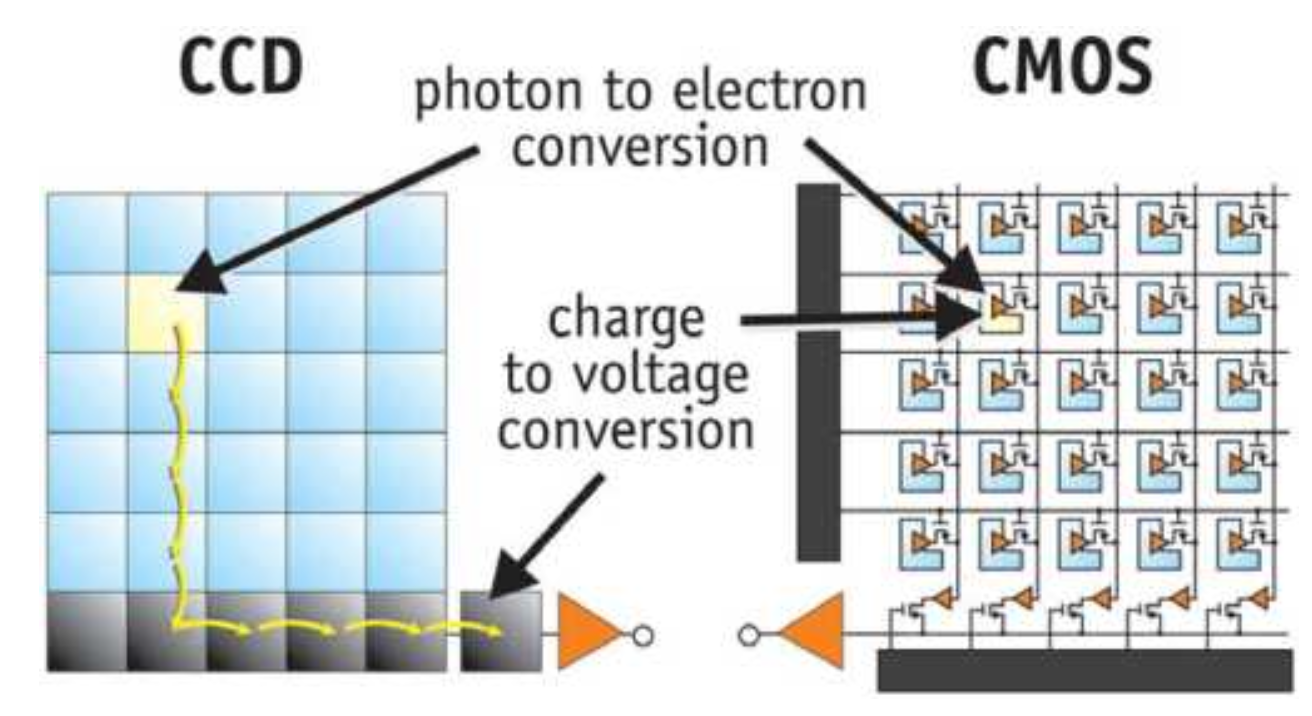
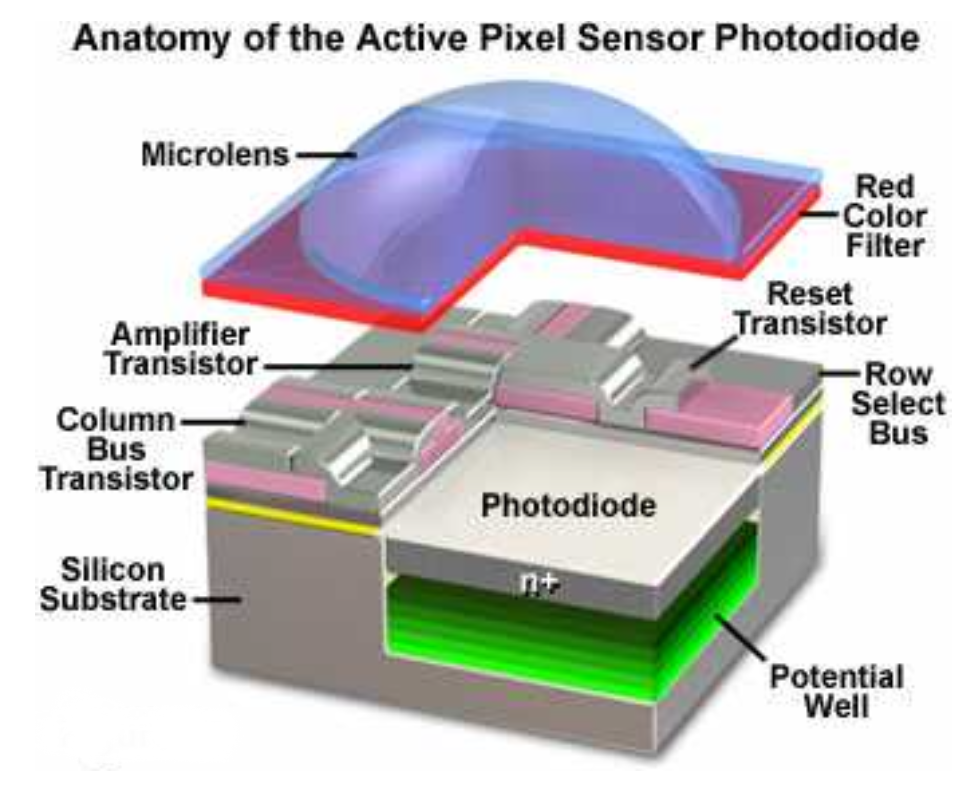
Próbkowanie przestrzenne obrazu (czyli zamiana sygnału ciągłego na jego reprezentację dyskretną) zależy od geometrii elementów sensorycznych urządzenia akwizycyjnego (np. kamery cyfrowej lub wideo). Poszczególne elementy czujnika są ułożone w uporządkowanych rzędach, prawie zawsze pod kątem prostym do siebie, wzdłuż płaszczyzny czujnika (Rysunek 3.2). Aparaty cyfrowe rejestrują obraz za pomocą matrycy CCD (ang. Charge-Coupled Device) lub CMOS (ang.Complementary Metal-Oxide-Semiconductor), która przetwarza światło na sygnał cyfrowy.
Próbkowanie czasowe odbywa się poprzez pomiar w regularnych odstępach czasu ilości światła padającego na każdy pojedynczy element czujnika. CCD w aparacie cyfrowym robi to poprzez wyzwolenie procesu ładowania, a następnie zmierzenie ilości ładunku elektrycznego, który nagromadził się w określonym czasie, w którym CCD była oświetlona.
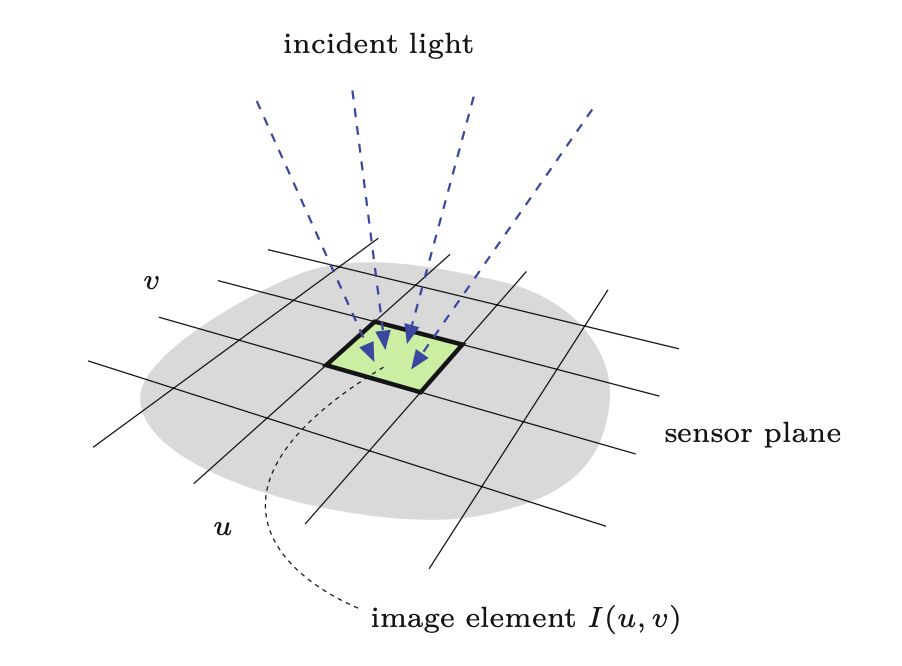
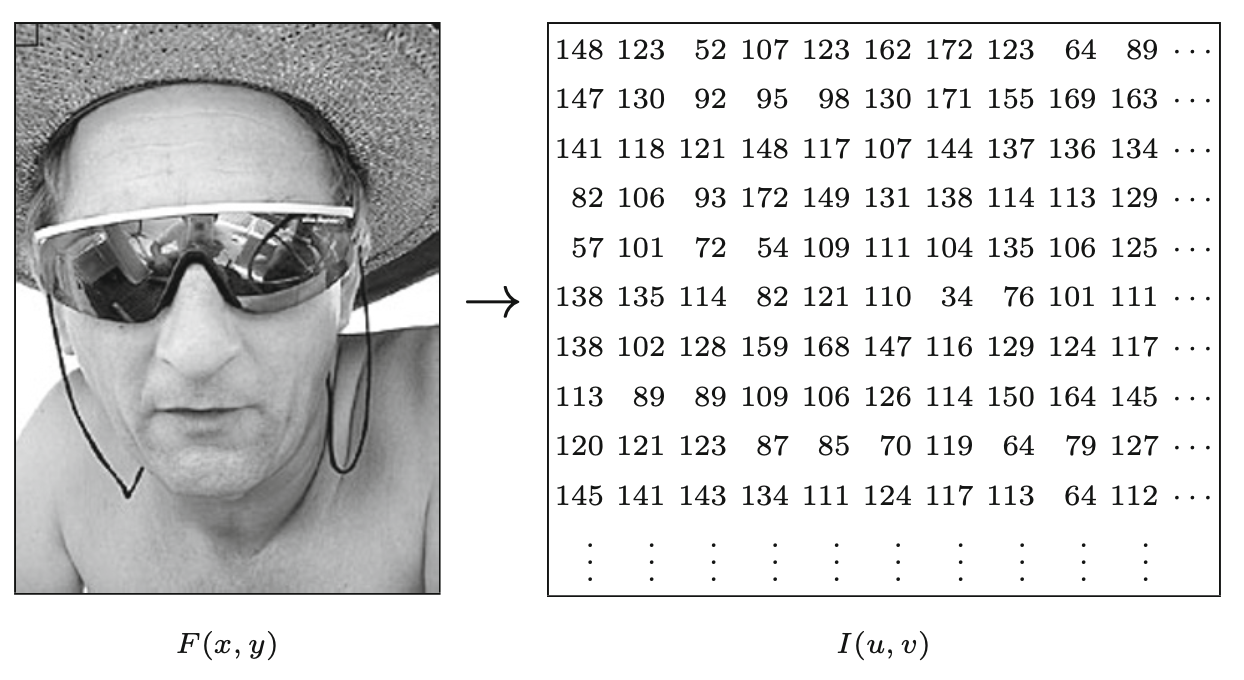
W celu przechowywania i przetwarzania wartości obrazu w komputerze są one powszechnie konwertowane do skali liczb całkowitych (np. \(256 = 2^8\) lub \(4096 = 2^{12}\)). Sporadycznie w zastosowaniach profesjonalnych, takich jak obrazowanie medyczne, stosuje się wartości zmiennoprzecinkowe. Konwersja odbywa się za pomocą konwertera analogowo-cyfrowego, który jest zazwyczaj wbudowanym bezpośrednio w elektronikę czujnikiem, tak że konwersja następuje podczas rejestracji obrazu lub jest wykonywana przez specjalny interfejs.
Matryce CMOS są tańsze w produkcji, bardziej energooszczędne i mogą być łatwiej integrowane z innymi elementami elektronicznymi w aparacie, takimi jak procesor obrazu, a także z innymi funkcjami, takimi jak GPS, WiFi czy Bluetooth. Matryce CCD są bardziej wrażliwe na światło i mają lepszą jakość obrazu, zwłaszcza w warunkach słabego oświetlenia. Natomiast matryce CMOS są lepsze do zastosowań, w których ważna jest wysoka przepustowość i szybkość rejestracji obrazów oraz niskie zużycie energii.
Najpowszechniej stosowany podział obrazów cyfrowych zapisanych na nośniku, to grafika rastrowa i grafika wektorowa. Grafika rastrowa (ang. raster image), zwana też grafiką bitmapową, to rodzaj grafiki, w której obraz jest składany z pojedynczych pikseli. Każdy piksel jest jakiegoś koloru i jest zapisany jako indywidualna jednostka danych. Obrazy rastrowe są zwykle zapisywane w formatach takich jak JPEG, PNG lub GIF.
Grafika wektorowa (ang. vector image) to rodzaj grafiki, w której obraz jest składany z kształtów geometrycznych takich jak linie, koła i trójkąty. Każdy kształt jest opisany matematycznie i jest zapisany jako indywidualna jednostka danych. Obrazy wektorowe są zwykle zapisywane w formatach takich jak SVG, PDF, AI lub EPS.

Główna różnica między grafiką rastrową a wektorową polega na tym, że obrazy rastrowe składają się z indywidualnych pikseli, podczas gdy obrazy wektorowe składają się z matematycznie opisanych kształtów. Obrazy rastrowe tracą jakość po powiększeniu, ponieważ piksele są widoczne, podczas gdy obrazy wektorowe zachowują jakość po powiększeniu, ponieważ są składane z kształtów matematycznych rysowanych na bierząco. Obie techniki, grafika rastrowa i wektorowa, mają swoje własne zalety i wady, i nie ma jednej techniki, która jest ogólnie uważana za bardziej dokładną.
Grafika rastrowa jest bardziej odpowiednia do przedstawiania szczegółowych i skomplikowanych obrazów, takich jak zdjęcia lub malarstwo. Są one bardziej naturalne i realistyczne. Jednak, kiedy obrazy te są powiększane, ich jakość traci, ponieważ piksele są widoczne.
Grafika wektorowa jest lepsza do tworzenia prostych i precyzyjnych kształtów, takich jak loga, ikony i ilustracje. Są one bardziej elastyczne i skalowalne, ponieważ składają się z matematycznie opisanych kształtów, co pozwala na powiększanie bez utraty jakości. Jednakże, nie są one tak naturalne i realistyczne jak obrazy rastrowe.
W ramach tego przedmiotu głównie będziemy się zajmować grafiką rastrową.
Rozdzielczość jest jednym z najważniejszych czynników wpływających na jakość obrazu. Im więcej pikseli ma obraz, tym więcej szczegółów jest widocznych. Rozdzielczość obrazu określa wymiary przestrzenne obrazu w świecie rzeczywistym i jest podawana jako liczba elementów obrazu na jednostkę pola; na przykład w punktach na cal (dpi) lub liniach na cal (lpi) w przypadku produkcji poligraficznej lub w pikselach na kilometr w przypadku zdjęć satelitarnych. Jednocześnie, im więcej pikseli ma obraz, tym większy jest jego rozmiar pliku i tym więcej pamięci jest potrzebne do jego przechowywania. Wymiary obrazu przedstawiane są za pomocą liczby pikseli poziomo i pionowo, np. 1920 x 1080 pikseli.
Innym ważnym czynnikiem wpływającym na wielkość obrazu jest format pliku w jakim jest zapisany. Niektóre formaty są kompresowane co pozwala na zmniejszenie wielkości pliku przy zachowaniu jakości obrazu, inne natomiast nie pozwalają na kompresję i zwiększają rozmiar pliku.
Skala szarości - dane obrazu w skali szarości składają się z pojedynczego kanału (ang. channel), który reprezentuje intensywność, jasność lub gęstość obrazu. W większości przypadków sens mają tylko wartości dodatnie, ponieważ liczby reprezentują natężenie energii świetlnej lub gęstość filmu, a więc nie mogą być ujemne, więc zwykle używa się całych liczb całkowitych z zakresu \(0, \ldots , 2^{k - 1}\) są używane. Na przykład typowy obraz w skali szarości wykorzystuje \(k = 8\) bitów (1 bajt) na piksel i wartości intensywności z zakresu \(0,\ldots,255\), gdzie wartość 0 oznacza minimalną jasność (czerń), a 255 maksymalną jasność (biel). W wielu zastosowaniach profesjonalnej fotografii i druku, a także w medycynie i astronomii, 8 bitów na piksel nie jest wystarczające. W tych dziedzinach często spotyka się głębię obrazu 12, 14, a nawet 16 bitów.1
Obrazy binarne (ang. binary images) - to specjalny rodzaj obrazu, w którym piksele mogą przyjmować tylko jedną z dwóch wartości, czarną lub białą. Wartości te są zwykle kodowane przy użyciu pojedynczego bitu (0/1) na piksel. Obrazy binarne są często wykorzystywane do reprezentowania grafiki liniowej, archiwizacji dokumentów, kodowania transmisji faksowych i oczywiście w druku elektronicznym.
Obrazy kolorowe (ang. color images) - większość kolorowych obrazów opiera się na kolorach podstawowych: czerwonym, zielonym i niebieskim (RGB), zwykle wykorzystując 8 bitów dla każdego kanału. W tego rodzaju obrazach kolorowych, każdy piksel wymaga 3×8 = 24 bity do zakodowania wszystkich trzech składowych, a zakres każdej indywidualnej składowej koloru wynosi [0, 255]. Podobnie jak w przypadku obrazów w skali szarości, kolorowe obrazy z 30, 36 i 42 bitami na piksel są powszechnie używane w profesjonalnych aplikacjach. Wreszcie, podczas gdy większość obrazów kolorowych zawiera trzy składowe, obrazy z czterema lub więcej składowymi koloru są powszechne w druku, zwykle oparte na modelu koloru CMYK (Cyan-Magenta-Yellow- Black). Główna różnica między tymi dwiema paletami polega na tym, że RGB ma więcej możliwości kolorów, ponieważ jest w stanie wygenerować więcej odcieni niż CMYK, ale kolory wyświetlane przez RGB nie są takie same jak te, które otrzymujemy przy druku z CMYK. Kolory drukowane z CMYK mogą również różnić się od tych wyświetlanych na ekranie.
Obrazy specjalne - są wymagane, jeżeli żaden z powyższych formatów standardowych nie jest wystarczający do przedstawienia wartości obrazu. Dwa popularne przykłady obrazów specjalnych to obrazy z wartościami ujemnymi oraz obrazy z wartościami zmiennoprzecinkowymi. Obrazy z wartościami ujemnymi powstają podczas etapów przetwarzania obrazu, takich jak filtrowanie w celu wykrywania krawędzi, a obrazy z wartościami zmiennoprzecinkowymi są często spotykane w zastosowaniach medycznych, biologicznych lub astronomicznych, gdzie wymagany jest zwiększony zakres liczbowy i precyzja. Te specjalne formaty są w większości przypadków specyficzne dla danego zastosowania i dlatego mogą być trudne do wykorzystania przez standardowe narzędzia do przetwarzania obrazów.
1 Zauważ, że głębia bitowa zwykle odnosi się do liczby bitów używanych do reprezentowania jednego składnika koloru, a nie liczby bitów potrzebnych do reprezentowania koloru piksela. Na przykład, zakodowany w RGB kolorowy obraz z 8-bitową głębią wymagałby 8 bitów dla każdego kanału, co daje w sumie 24 bity, podczas gdy ten sam obraz z 12-bitową głębią wymagałby w sumie 36 bitów.
TIFF (ang. Tagged Image File Format) jest formatem pliku, który jest używany do przechowywania i wymiany obrazów cyfrowych. Jest to format bezstratnej kompresji, co oznacza, że po zapisaniu i odczytaniu obrazu jego jakość pozostaje taka sama. TIFF jest obsługiwany przez wiele programów do edycji obrazów i może być używany do przechowywania różnych rodzajów obrazów, w tym obrazów w skali szarości, kolorowych oraz map bitowych. Format TIFF jest często używany przez profesjonalnych fotografów i grafików, ponieważ pozwala na zachowanie wysokiej jakości obrazu i jest kompatybilny z wieloma programami i urządzeniami.
GIF (ang. Graphics Interchange Format) jest formatem pliku graficznego, który jest używany do przechowywania i wymiany obrazów w internecie. GIF jest formatem bezstratnym, ale jest kompresowany, co pozwala na zmniejszenie rozmiaru pliku i przyspieszenie jego przesyłania. Co ważne, GIF jest formatem obsługującym animacje, co oznacza, że może on przechowywać kilka klatek jako jeden plik, co pozwala na tworzenie animowanych obrazów, często używanych jako emotikony, ikony lub małe animacje na stronach internetowych. GIF jest również ograniczony do 256 kolorów, co oznacza, że nie jest on dobrym rozwiązaniem do przechowywania zdjęć o wysokiej jakości.
PNG (ang. Portable Network Graphics) jest bezstratnym formatem pliku graficznego, który jest używany do przechowywania i wymiany obrazów w internecie. Podobnie jak GIF może być kompresowany w celu zmniejszenia rozmiaru pliku. Co ważne, format PNG jest formatem obsługującym przezroczystość, co oznacza, że może on przechowywać kanał alfa, który jest odpowiedzialny za przezroczystość obrazu, co pozwala na zastosowanie efektu przezroczystości na obrazie bez konieczności dodatkowego tworzenia specjalnego tła. PNG jest również w stanie przechowywać więcej kolorów niż GIF, co oznacza, że jest to lepsze rozwiązanie dla obrazów o wysokiej jakości 2.
PNG-8: Jest to najbardziej podstawowy typ PNG, który może przechowywać maksymalnie 256 kolorów (8-bitowa głębia kolorów). Jest idealny dla obrazów o ograniczonej liczbie kolorów, takich jak ikony, grafiki o dużej ilości powtarzających się kolorów lub obrazy z przezroczystością.
PNG-24: Ten typ PNG może przechowywać do 16,7 miliona kolorów (24-bitowa głębia kolorów). Wykorzystuje trzy kanały RGB (po 8 bitów na kanał) do reprezentacji pełnej gamy kolorów. Jest bardziej odpowiedni do zdjęć, grafiki z gradientami i obrazów złożonych.
PNG-32: Ten typ PNG jest rozszerzeniem PNG-24, który dodaje dodatkowy kanał alfa (8 bitów) dla obsługi przezroczystości. Oznacza to, że może przechowywać do 16,7 miliona kolorów plus informacje o przezroczystości.
JPEG (ang. Joint Photographic Experts Group) to popularny format zapisu obrazów cyfrowych, który jest szczególnie przydatny do przechowywania zdjęć. Format ten pozwala na kompresję pliku (stratną), dzięki czemu pliki JPEG są mniejsze niż pliki niekompresowane. Format JPEG obsługuje pełny zakres kolorów, co oznacza, że jest odpowiedni dla fotografii i innych obrazów, które wykorzystują szeroką gamę kolorów. Użytkownik może wybrać poziom kompresji, który wpływa na rozmiar pliku i jakość obrazu. Działa dobrze dla obrazów, które zawierają fotograficzne szczegóły, gradienty kolorów i inne elementy charakterystyczne dla fotografii. Wyższy poziom kompresji skutkuje mniejszym rozmiarem pliku, ale może prowadzić do większej utraty jakości. Format JPEG nie obsługuje warstw przezroczystości. Tło obrazu jest zazwyczaj zapisane jako kolor stały (np. biały), co może ograniczać zastosowanie JPEG w przypadku obrazów z przezroczystością.
EXIF (ang. Exchangeable Image File Format) to format danych, który jest zapisywany w pliku obrazu cyfrowego, takim jak JPEG lub TIFF. Informacje EXIF zawierają szczegółowe dane dotyczące zdjęcia, takie jak data i godzina utworzenia zdjęcia, parametry aparatu fotograficznego (np. przysłona, czas naświetlania, ISO), dane dotyczące obiektywu, a także współrzędne GPS, jeśli zdjęcie zostało zrobione z użyciem aparatu z GPS. EXIF jest przydatny dla fotografów i programów do obróbki zdjęć, ponieważ pozwala na łatwe odczytanie i wykorzystanie tych danych.
BMP (ang. Bitmap) to format pliku obrazu, który jest przeznaczony do przechowywania obrazów rastrowych, takich jak zdjęcia, grafiki i mapy bitowe. BMP jest formatem pliku natywnym dla systemów operacyjnych Windows, co oznacza, że pliki tego formatu są bezpośrednio obsługiwane przez system Windows i nie wymagają dodatkowego oprogramowania do odczytu.
BMP jest formatem bezstratnym, co oznacza, że po zapisie obrazu w tym formacie, jego jakość pozostaje taka sama jak przed zapisem. Pliki BMP są jednak dość duże, ponieważ nie są skompresowane, co oznacza, że zajmują więcej miejsca na dysku niż pliki skompresowane innymi formatami. BMP jest często używany do przechowywania obrazów w celach archiwizacyjnych, ponieważ zachowuje pełną jakość obrazu. Format BMP obsługuje różne głębokości kolorów, od 1-bitowego (czarno-biały) do 32-bitowego (kolor z przezroczystością). Najczęściej spotykane głębokości kolorów to 8-bitowe (256 kolorów) oraz 24-bitowe (16,7 miliona kolorów).

Istnieje wiele zewnętrznych (w stosunku do środowiska R) profesjonalnych narzędzi do obróbki zdjęć. Wśród nich z pewnością należy wymienić: Adobe Photoshop, CorelDRAW, Gimp, PIXLR, FIji (ImageJ) i wiele innych. Część z nich jest komercyjna, a część darmowa. Osobiście do przetwarzania obrazów pochodzących z badań biologicznych, medycznych, czy inżynierskich polecam darmowy program Fiji, będący rozszerzeniem swojego pierwowzoru, czyli ImageJ.
Również w samym środowisku R istnieje szereg bibliotek do obsługi obrazów:
imager - pozwala na szybkie przetwarzanie obrazów w maksymalnie 4 wymiarach (dwa wymiary przestrzenne, jeden wymiar czasowy/głębokościowy, jeden wymiar koloru). Udostępnia większość tradycyjnych narzędzi do przetwarzania obrazów (filtrowanie, morfologia, transformacje, itp.), jak również różne funkcje do łatwej analizy danych obrazowych przy użyciu R (Barthelme 2023).imagerExtra - poszerzenie zestawu funkcji pakietu imager(Ochi 2019).magick - dostarcza nowoczesnego i prostego zestawu narzędzi do przetwarzania obrazów w R. Obejmuje on ImageMagick STL, który jest najbardziej wszechstronną biblioteką przetwarzania obrazów typu open-source dostępną obecnie (Ooms 2023).imageseg - pakiet ogólnego przeznaczenia do segmentacji obrazów z wykorzystaniem modeli TensorFlow opartych na architekturze U-Net autorstwa Ronneberger, Fischer, i Brox (2015) oraz architekturze U-Net++ autorstwa Zhou i in. (2018). Dostarcza wstępnie wytrenowane modele do oceny gęstości łanu i gęstości roślinności podszytu na podstawie zdjęć roślinności. Ponadto pakiet zapewnia workflow do łatwego tworzenia wejściowych modeli i architektur modeli dla segmentacji obrazów ogólnego przeznaczenia na podstawie obrazów w skali szarości lub kolorowych, zarówno dla segmentacji obrazów binarnych, jak i wieloklasowych (Niedballa i Axtner 2022).pliman - jest pakietem do analizy obrazów, ze szczególnym uwzględnieniem obrazów roślin. Jest użytecznym narzędziem do uzyskania informacji ilościowej dla obiektów docelowych. W kontekście obrazów roślin, ilościowe określanie powierzchni liści, nasilenia chorób, liczby zmian chorobowych, liczenie liczby ziaren, uzyskiwanie statystyk ziaren (np. długość i szerokość) można wykonać stosując pakiet pliman(Olivoto 2021).Rvision - to rozwijająca się biblioteka wizji komputerowej dla R. Jest ona oparta na potężnej bibliotece OpenCV dla C/C++, najnowocześniejszej bibliotece wizji komputerowej w świecie open source (Garnier i Muschelli 2022).Przykład 3.1 W tym przykładzie przedstawiona zostanie procedura importu i eksportu obrazów do różnych formatów. Najpierw wczytamy zdjęcie wykonane telefonem (IPhone 12) zapisane w formacie TIFF, a następnie zapiszemy to zdjęcie w kilku innych formatach, by na końcu wczytać je wszystkie i porównać.
Image. Width: 3024 pix Height: 4032 pix Depth: 1 Colour channels: 3 Jak widać obraz w formacie TIFF zajmuje bardzo dużo miejsca na dysku (36,6MB).
# eksport do GIF
save.image(img_orig, "images/img.gif")
# eksport do PNG
save.image(img_orig, "images/img.png")
# eksport do JPEG z jakością 100%
save.image(img_orig, "images/img.jpeg", quality = 1)
# eksport do JPEG z jakością 75%
save.image(img_orig, "images/img2.jpeg", quality = .75)
# eksport do JPEG z jakością 50%
save.image(img_orig, "images/img3.jpeg",quality = .50)
# eksport do JPEG z jakością 25%
save.image(img_orig, "images/img4.jpeg", quality = .25)Po zapisie do innych formatów pliki znacznie zmniejszyły swoją wielkość.
img_gif <- load.image("images/img.gif")
img_png <- load.image("images/img.png")
img_jpeg1 <- load.image("images/img.jpeg")
img_jpeg2 <- load.image("images/img2.jpeg")
img_jpeg3 <- load.image("images/img3.jpeg")
img_jpeg4 <- load.image("images/img4.jpeg")
map_df(c("images/IMG_3966.tiff", "images/img.gif", "images/img.png",
"images/img.jpeg", "images/img2.jpeg", "images/img3.jpeg",
"images/img4.jpeg"), ~iminfo(.x)) |>
gt()| name | format | width | height | size |
|---|---|---|---|---|
| IMG_3966.tiff | TIFF | 3024 | 4032 | 36.614MB |
| img.gif | GIF | 3024 | 4032 | 5.43653MB |
| img.png | PNG | 3024 | 4032 | 12.1091MB |
| img.jpeg | JPEG | 3024 | 4032 | 6.63342MB |
| img2.jpeg | JPEG | 3024 | 4032 | 1.5405MB |
| img3.jpeg | JPEG | 3024 | 4032 | 1.05409MB |
| img4.jpeg | JPEG | 3024 | 4032 | 730010B |
Pomimo znacznej różnicy w wielkości obrazów (w sensie miejsca zajmowanego na dysku) nie różnią się one znacznie jakością (przynajmniej na pierwszy rzut oka)
img_orig
img_jpeg1
img_gif
img_png
img_jpeg2
img_jpeg3
img_jpeg4






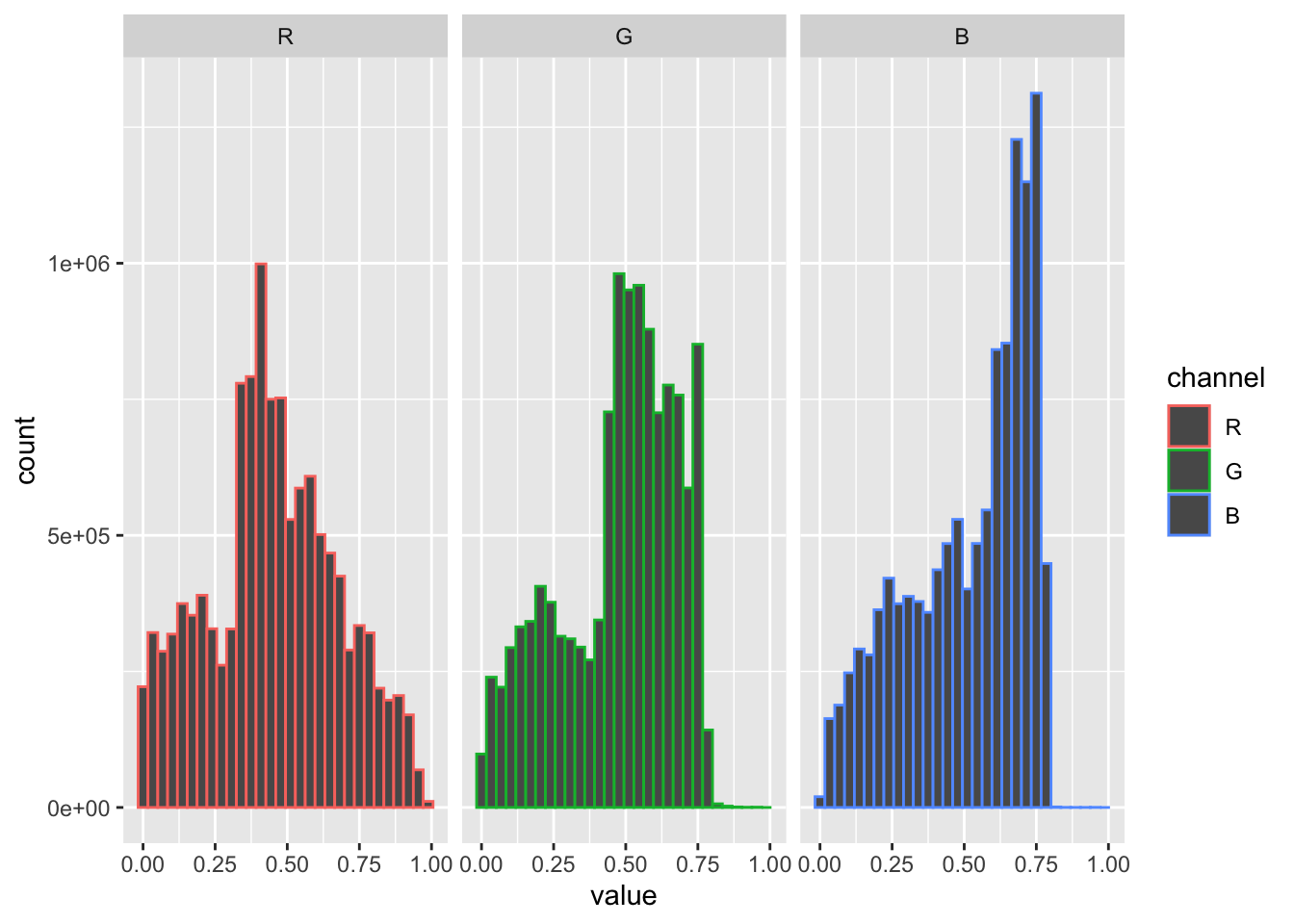
img_orig |>
as.data.frame() |>
mutate(channel = factor(cc,labels=c('R','G','B'))) |>
ggplot(aes(value,col=channel))+
geom_histogram()+
facet_wrap(~ channel)
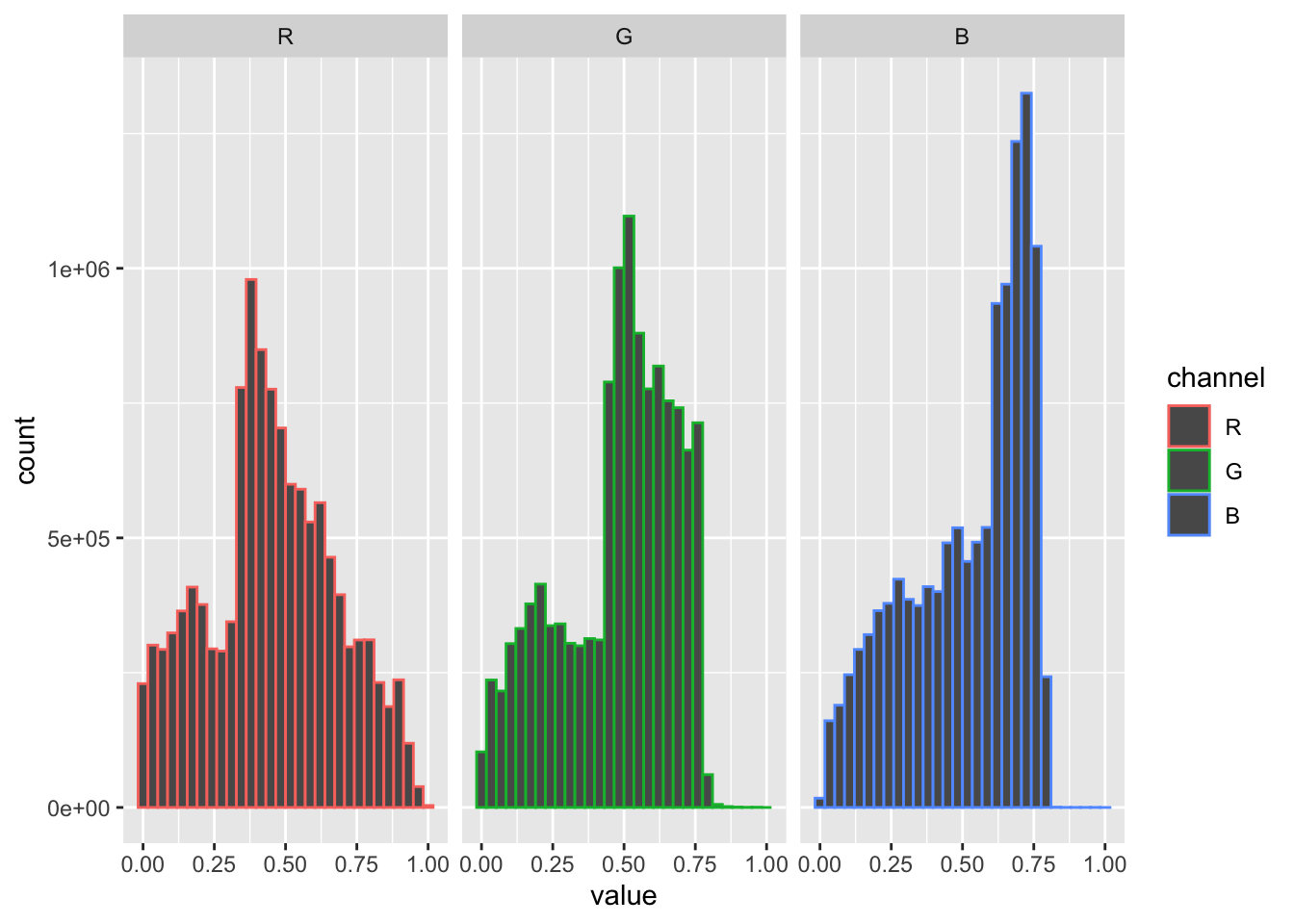
img_jpeg1 |>
as.data.frame() |>
mutate(channel = factor(cc,labels=c('R','G','B'))) |>
ggplot(aes(value,col=channel))+
geom_histogram()+
facet_wrap(~ channel)
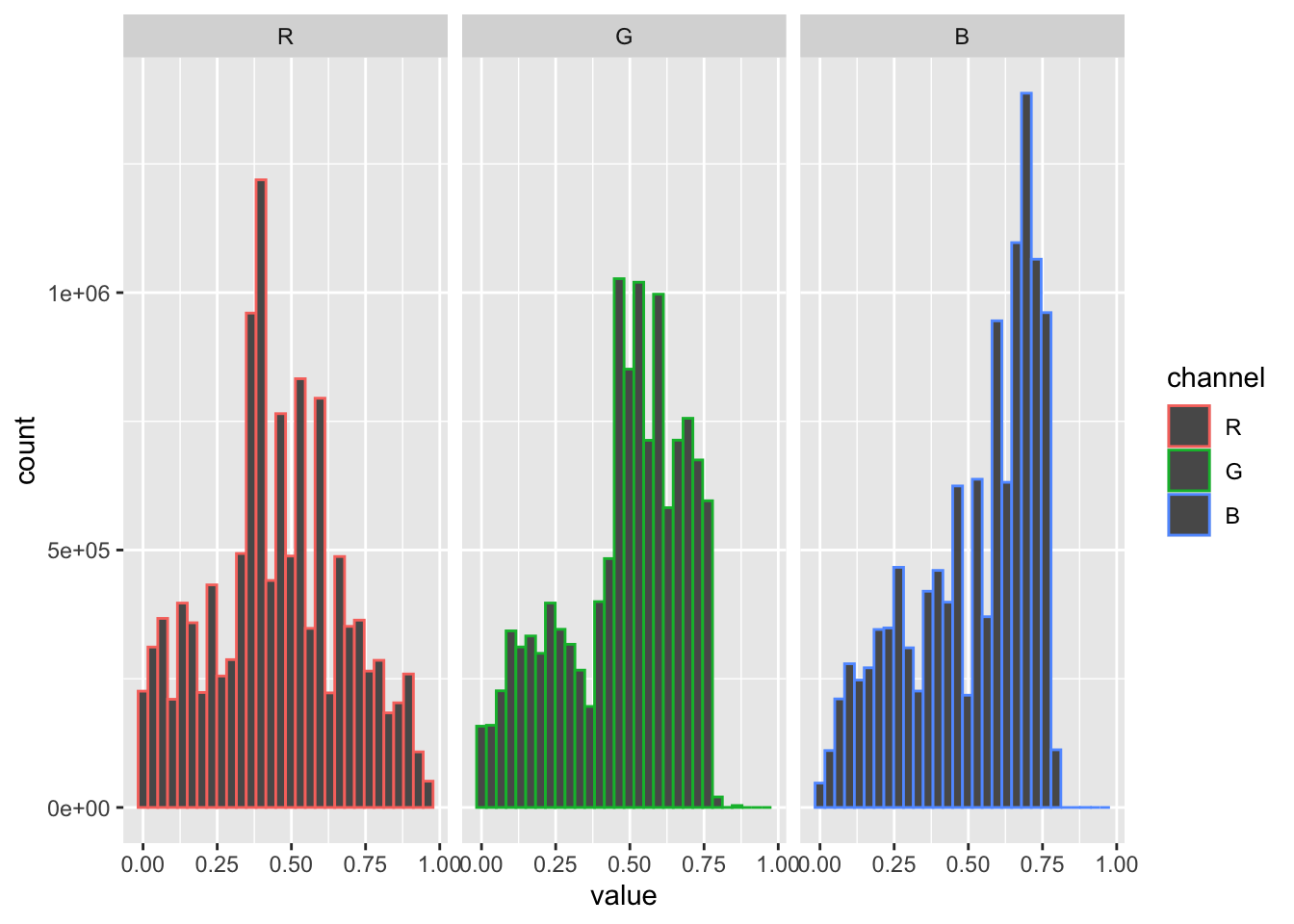
img_gif |>
as.data.frame() |>
mutate(channel = factor(cc,labels=c('R','G','B'))) |>
ggplot(aes(value,col=channel))+
geom_histogram()+
facet_wrap(~ channel)
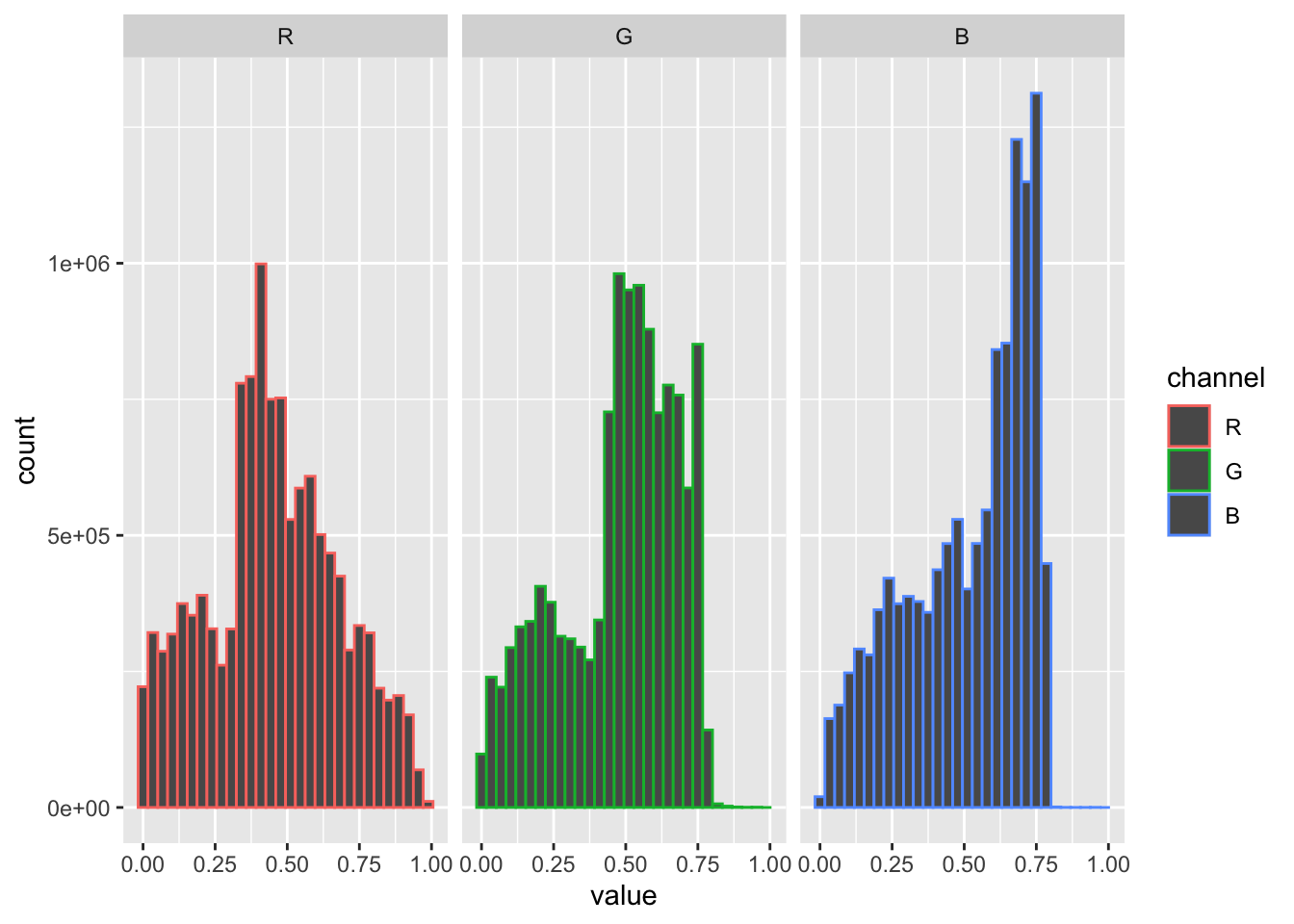
img_png |>
as.data.frame() |>
mutate(channel = factor(cc,labels=c('R','G','B'))) |>
ggplot(aes(value,col=channel))+
geom_histogram()+
facet_wrap(~ channel)