Zanim przystąpimy do uczenia jakiejkolwiek sieci głębokiego uczenia trzeba poznać najważniejsze elementy niemal każdej sieci neuronowej. Zaczniemy od kluczowego nazewnictwa, którego będziemy używać w dalszej części książki.
próbka lub wejście (ang. sample/input) - jedna obserwacja wchodząca do sieci;
predykcja lub wyjście (ang. prediction/output) - to co z sieci wychodzi;
cel (ang. target) - cel, to co twój model powinien przewidzieć;
błąd predykcji lub strata (ang. prediction error/loss value) - miara błędu kwantyfikująca różnicę pomiędzy celem i predykcją;
klasy (ang. classes) - zbiór możliwych wartości (etykiet) zmiennej wynikowej;
etykieta (ang. label) - etykieta pojedynczej instancji, przykładowo obserwacja nr 1498 ma etykietę “kot”;
klasyfikacja dwustanowa (ang. binary classification) - zadanie w którym zmienna wynikowa ma dokładnie dwie wykluczające się klasy;
klasyfikacja wielostanowa (ang. multiclass classification) - zadanie w którym zmienna wynikowa ma więcej niż dwie wykluczające się klasy;
klasyfikacja wieloetykietowa (ang. multilabel classification) - zadanie w którym jednej próbce można przypisać wiele klas wykluczających się, np. gdy na zdjęciu widać zarówno kot, jak i psa, to wyjście z sieci powinno dawać dwie etykiety: “kot”, “pies”;
regresja skalarna (ang. scalar regression) - zadanie w którym wartość docelowa ma charakter ciągłej wartości skalarnej . Przykładowo jeśli przewidujemy cenę nieruchomości;
regresja wektorowa (ang. vector regression) - zadanie, w którym celem jest zestaw ciągłych wartości (np. ciągły wektor). Przykład, gdy celem twojej predykcji są współrzędne wierzchołków prostokąta obejmującego obiekt na zdjęciu;
partia lub wsad (ang. batch/mini-batch) - mały zestaw probek, zwykle składający się z od 8 do 128 próbek przetwarzanych jednocześnie przez model. Najczęściej wielkość partii jest potęga 2 (ma to ułatwić ładowanie próbek do pamięci procesora graficznego). Partia jest używana do jednej aktualizacji wag modelu.
W uczeniu maszynowym, celem jest osiągnięcie modeli, które generalizują, czyli dobrze radzą sobie z nigdy wcześniej nie widzianymi danymi, a overfitting jest główną przeszkodą. Możesz kontrolować tylko to, co możesz zaobserwować, więc bardzo ważne jest, aby móc wiarygodnie zmierzyć zdolność generalizacji twojego modelu. W kolejnych rozdziałach omówione są strategie łagodzenia overfitting i maksymalizacji generalizacji. W tym rozdziale skupimy się na tym, jak mierzyć generalizację, czyli jak oceniać modele uczenia maszynowego.
11.1 Podział na zbiór uczący, walidacyjny i testowy
Ocena modelu zawsze sprowadza się do podzielenia dostępnych danych na trzy zestawy: treningowy, walidacyjny i testowy. Trenujesz na danych treningowych i oceniasz swój model na danych walidacyjnych. Kiedy model jest już gotowy do użycia, testujesz go po raz ostatni na danych testowych.
Możesz zapytać, dlaczego nie mieć dwóch zestawów: treningowego i testowego? Trenowałbyś na danych treningowych i oceniałbyś na danych testowych. To przecież o wiele prostsze!
Powodem jest to, że opracowanie modelu zawsze wiąże się z dostrojeniem jego konfiguracji: na przykład wyborem liczby warstw lub rozmiaru warstw (zwanych hiperparametrami modelu, aby odróżnić je od parametrów, które są wagami sieci). Tuningu tego dokonasz, wykorzystując jako sygnał zwrotny wydajność modelu na danych walidacyjnych1. W istocie, to strojenie jest formą uczenia się: poszukiwaniem dobrej konfiguracji w pewnej przestrzeni parametrów. W rezultacie, dostrajanie hiperparametrów modelu na podstawie jego wydajności na zbiorze walidacyjnym może szybko doprowadzić do przeuczenia do zbioru walidacyjnego, nawet jeśli twój model nigdy nie jest bezpośrednio trenowany na nim.
1 mierzoną najczęściej funkcją straty
Centralnym punktem tego fenomenu jest pojęcie wycieku informacji. Za każdym razem, gdy dostrajasz hiperparametr swojego modelu w oparciu o jego wydajność na zbiorze walidacyjnym, niektóre informacje o danych walidacyjnych wyciekają do modelu. Jeśli zrobisz to tylko raz, dla jednego parametru, wtedy bardzo niewiele bitów informacji wycieknie, a twój zbiór walidacyjny pozostanie wiarygodny do oceny modelu. Ale jeśli powtórzysz to wiele razy - przeprowadzając jeden eksperyment, oceniając go na zbiorze walidacyjnym i modyfikując w rezultacie swój model - wtedy wycieknie coraz większa ilość informacji o zbiorze walidacyjnym do modelu.
Ostatecznie, skończysz z modelem, który działa podejrzanie dobrze na danych walidacyjnych, ponieważ właśnie po to go zoptymalizowałeś. Zależy Ci na wydajności na zupełnie nowych danych, a nie na danych walidacyjnych, więc musisz użyć zupełnie innego, nigdy wcześniej niewidzianego zbioru danych do oceny modelu: testowego zbioru danych. Twój model nie powinien mieć dostępu do żadnych informacji o zbiorze testowym, nawet pośrednio. Jeśli cokolwiek w modelu zostało dostrojone w oparciu o wydajność zbioru testowego, to Twoja miara uogólnienia będzie błędna.
Podział danych na zbiory treningowe, walidacyjne i testowe może wydawać się prosty, ale istnieje kilka zaawansowanych sposobów, które mogą się przydać, gdy dostępnych jest niewiele danych. Przyjrzyjmy się trzem klasycznym przepisom oceny: zwykłej walidacji hold-out, walidacji krzyżowej k-krotnej oraz iterowanej krzyżowej walidacji k-krotnej z losowaniem2.
2 zwanej także k-krotną walidacja krzyżową z powtórzeniami
11.1.1 Hold-out
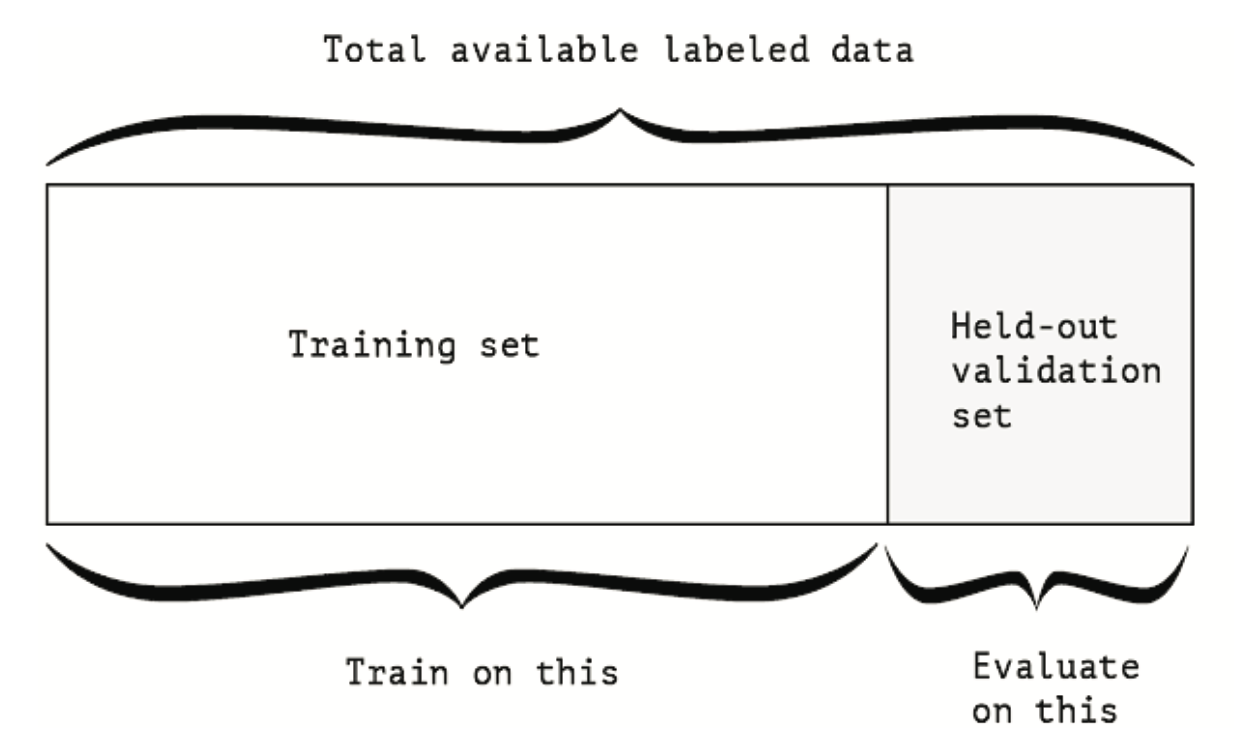
Wyodrębniamy pewną część danych jako zbiór testowy. Trenujemy na pozostałych danych i oceniamy na zbiorze testowym. Jak widzieliśmy w poprzednich rozdziałach, aby zapobiec wyciekowi informacji, nie powinniśmy dostrajać swojego modelu na podstawie zbioru testowego, dlatego powinniśmy również zarezerwować zbiór walidacyjny.
Rysunek 11.1: Walidacja hold-out
Schematycznie, walidacja hold-out wygląda jak na Rysunek 11.1. Poniższy listing pokazuje prostą implementację.
Kod
indices <-sample(1:nrow(data), size =0.80*nrow(data))evaluation_data <- data[-indices, ]training_data <- data[indices, ]model <-get_model()model %>%train(training_data)validation_score <- model %>%evaluate(validation_data)model <-get_model()model %>%train(data)test_score <- model %>%evaluate(test_data)
1
wylosuj indeksy zbioru uczącego;
2
zdefiniuj zbiór walidacyjny;
3
zdefiniuj zbiór uczący;
4
ucz model na zbiorze uczący i sprawdzaj dopasowanie na walidacyjnym;
5
naucz model na pełnym zestawie danych uczących (na połączonym zbiorze uczącym i walidacyjnym).
Jest to najprostszy protokół oceny, ale ma jedną wadę: jeśli dostępnych danych jest mało, wtedy twoje zestawy walidacyjne i testowe mogą zawierać zbyt mało próbek, aby być statystycznie reprezentatywne dla danych. Łatwo to rozpoznać: jeśli różne losowe rundy tasowania danych przed podziałem kończą się uzyskaniem bardzo różnych miar wydajności modelu, to masz ten problem.
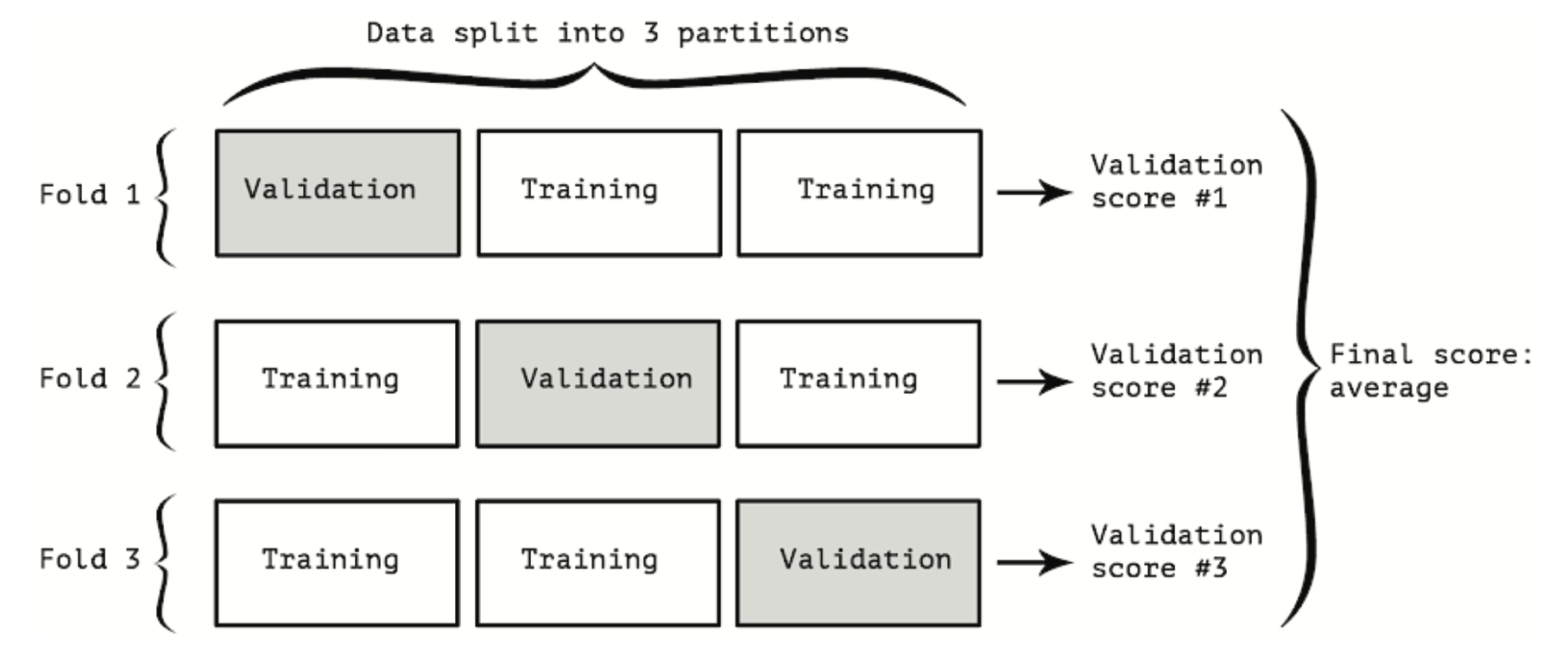
11.1.2 Walidacja krzyżowa k-krotna
W tym podejściu dzielimy dane na k podzbiorów (foldów) o (w miarę) równym rozmiarze. Trenuj swój model na k-1 foldach, a na jednym pozostałym foldzie oceń jego jakość. Twój ostateczny wynik jest średnią z k uzyskanych wyników. Podobnie jak w przypadku walidacji typu hold-out, metoda ta nie zwalnia z używania odrębnego zbioru walidacyjnego do kalibracji modelu.
Rysunek 11.2: Walidacja krzyżowa K-krotna
Schematycznie, k-krotna walidacja krzyżowa wygląda jak na Rysunek 11.2. Oto prosta implementacja pseudokodu w R.
Kod
k <-4indices <-sample(1:nrow(data))folds <-cut(indices, breaks = k, labels =FALSE)validation_scores <-c()for (i in1:k) { validation_indices <-which(folds == i, arr.ind =TRUE) validation_data <- data[validation_indices,] training_data <- data[-validation_indices,] model <-get_model() model %>%train(training_data) results <- model %>%evaluate(validation_data) validation_scores <-c(validation_scores, results$accuracy)}validation_score <-mean(validation_scores)model <-get_model()model %>%train(data) results <- model %>%evaluate(test_data)
1
wybierz obserwacje do zbioru walidacyjnego;
2
użyj pozostałych danych jako zbioru uczącego (fold);
3
stwórz model i ucz go na zbiorze uczącym (foldzie);
4
oceń dopasowanie na zbiorze walidacyjnym (uśrednione z foldów);
5
ucz model na pełnym zestawie uczącym.
11.1.3 Iterowana metoda walidacji krzyżowej z losowaniem
Przeznaczona jest dla sytuacji, w których masz stosunkowo mało dostępnych danych i musisz jak najdokładniej ocenić swój model. Polega ona na wielokrotnym zastosowaniu k-krotnej walidacji, tasując dane za każdym razem przed podzieleniem ich na k sposobów. Końcowy wynik jest średnią z wyników uzyskanych w każdym przebiegu k-krotnej walidacji. Zauważ, że kończysz szkolenie i ocenę P * k modeli (gdzie P to liczba iteracji, których używasz), co może być bardzo kosztowne.
W literaturze tematu metoda ta występuje również pod nazwą k-krotnego sprawdzianu krzyżowego z powtórzeniami.
11.1.4 Uwagi do resamplingu
Reprezentatywność danych - chcemy, aby zarówno zbiór treningowy, jak i testowy były reprezentatywne dla danych. Na przykład, jeśli próbujemy sklasyfikować obrazy cyfr i zaczynamy od tablicy próbek, gdzie próbki są uporządkowane według ich klasy, to biorąc pierwsze 80% tablicy jako zbiór treningowy, a pozostałe 20% jako testowy, nasz zbiór treningowy będzie zawierał tylko klasy 0-7, podczas gdy zbiór testowy zawiera tylko klasy 8-9. Wydaje się to niedorzecznym błędem, ale jest zaskakująco powszechne. Z tego powodu, zazwyczaj powinniśmy losowo przetasować swoje dane przed podzieleniem ich na zestawy treningowe i testowe.
Oś czasu - jeśli próbujemy przewidzieć przyszłe wartości biorąc pod uwagę przeszłość (na przykład, pogoda jutro, zmiany cen akcji, i tak dalej), nie powinniśmy losowo tasować swoich danych przed ich podziałem, ponieważ robiąc to, stworzymy czasowy wyciek danych: nasz model będzie skutecznie trenowany na danych z przyszłości. W takich sytuacjach zawsze powinniśmy upewnić się, że wszystkie dane w naszym zestawie testowym są potomne w stosunku do danych w zestawie treningowym.
Redundancja w danych - jeśli niektóre obserwacje pojawiają się dwukrotnie (co jest dość powszechne w przypadku danych ze świata rzeczywistego), to przetasowanie danych i podzielenie ich na zbiór treningowy i walidacyjny spowoduje redundancję pomiędzy zbiorem treningowym i walidacyjnym. W efekcie, będziemy testowali na części danych treningowych, co jest najgorszą rzeczą jaką możesz zrobić! Upewnijmy się, że nasz zestaw treningowy i zestaw walidacyjny są rozłączne.
11.2 Przygotowanie danych
Wiele technik wstępnego przetwarzania danych i inżynierii cech jest specyficznych dla danej dziedziny (np. specyficznych dla danych tekstowych lub danych obrazowych); omówimy je w kolejnych rozdziałach, gdy napotkamy je w praktycznych przykładach. Na razie zajmiemy się podstawami, które są wspólne dla wszystkich domen danych. Skupimy się na najważniejszych.
11.2.1 Wektoryzacja
Wszystkie wejścia i cele w sieci neuronowej muszą być tensorami danych zmiennoprzecinkowych (lub, w szczególnych przypadkach, tensorami liczb całkowitych). Jakiekolwiek dane, które chcemy przetworzyć - dźwięk, obraz, tekst - musimy najpierw zamienić na tensory, co nazywamy wektoryzacją danych. Na przykład, jeśli zajmujemy się automatyczna analizą tekstu, to konieczna jest transformacja wyrazów metodą one-hot encoding, która zamieni nam wyrazy na zestaw zmiennych zmiennoprzecinkowych. W przykładach klasyfikacji cyfr dane były już w postaci wektorowej, więc można było pominąć ten krok.
11.2.2 Normalizacja
W przykładzie klasyfikacji cyfr, zaczęliśmy od danych obrazu zakodowanych jako liczby całkowite z zakresu 0-255, kodujące wartości w skali szarości. Zanim wprowadzimy te dane do sieci, musieliśmy podzielić je przez 255, aby uzyskać wartości zmiennoprzecinkowe z zakresu 0-1. Podobnie, przy przewidywaniu cen domów, zaczęliśmy od cech, które miały różne zakresy - niektóre cechy miały małe wartości zmiennoprzecinkowe, inne miały dość duże wartości całkowite. Zanim wprowadziliśmy te dane do swojej sieci, musieliśmy znormalizować każdą cechę niezależnie, tak aby jej odchylenie standardowe wynosiło 1, a średnia 0.
Ogólnie rzecz biorąc, nie jest bezpiecznie podawać do sieci neuronowej danych, które przyjmują stosunkowo duże wartości (na przykład wielocyfrowe liczby całkowite, które są znacznie większe niż wartości początkowe przyjmowane przez wagi sieci) lub dane, które są niejednorodne (na przykład dane, w których jedna cecha jest w zakresie 0-1, a inna w zakresie 100-200). Takie postępowanie może wywołać duże aktualizacje gradientu, które uniemożliwią sieci osiągnięcie zbieżności. Aby ułatwić uczenie się sieci, nasze dane powinny mieć następujące cechy:
Przyjmują małe wartości - większość wartości powinna być w zakresie 0-1.
Zachowują jednorodność - to znaczy, że wszystkie cechy powinny przyjmować wartości w mniej więcej tym samym zakresie.
Zazwyczaj będziemy normalizować cechy zarówno w danych treningowych, jak i testowych. W tym przypadku będziemy chcieli obliczyć średnią i odchylenie standardowe tylko na danych treningowych, a następnie zastosować je zarówno do danych treningowych, jak i testowych.
Kod
mean <-apply(train_data, 2, mean)std <-apply(train_data, 2, sd)train_data <-scale(train_data, center = mean, scale = std)test_data <-scale(test_data, center = mean, scale = std)
1
oblicz średnią i odchylenie standardowe na zbiorze uczącym;
2
zastosuj obliczone parametry do zbioru uczącego i testowego.
11.2.3 Usuń braki danych
Czasami w danych mogą pojawić się brakujące wartości. Generalnie, w sieciach neuronowych bezpiecznie jest zastępować brakujące wartości przez 0, pod warunkiem, że 0 nie jest już wartością znaczącą. Sieć nauczy się z ekspozycji na dane, że wartość 0 oznacza brakujące dane i zacznie ignorować tę wartość.
Zauważmy, że jeśli spodziewamy się brakujących wartości w danych testowych, ale sieć była trenowana na danych bez żadnych brakujących wartości, to sieć nie nauczy się ignorować brakujących wartości! W tej sytuacji powinniśmy sztucznie wygenerować próbki treningowe z brakującymi wpisami: skopiować kilka próbek treningowych kilka razy i opuścić niektóre cechy, które spodziewamy się, że prawdopodobnie będą wybrakowane w danych testowych.
11.3 Nadmierne dopasowanie i niedopasowanie
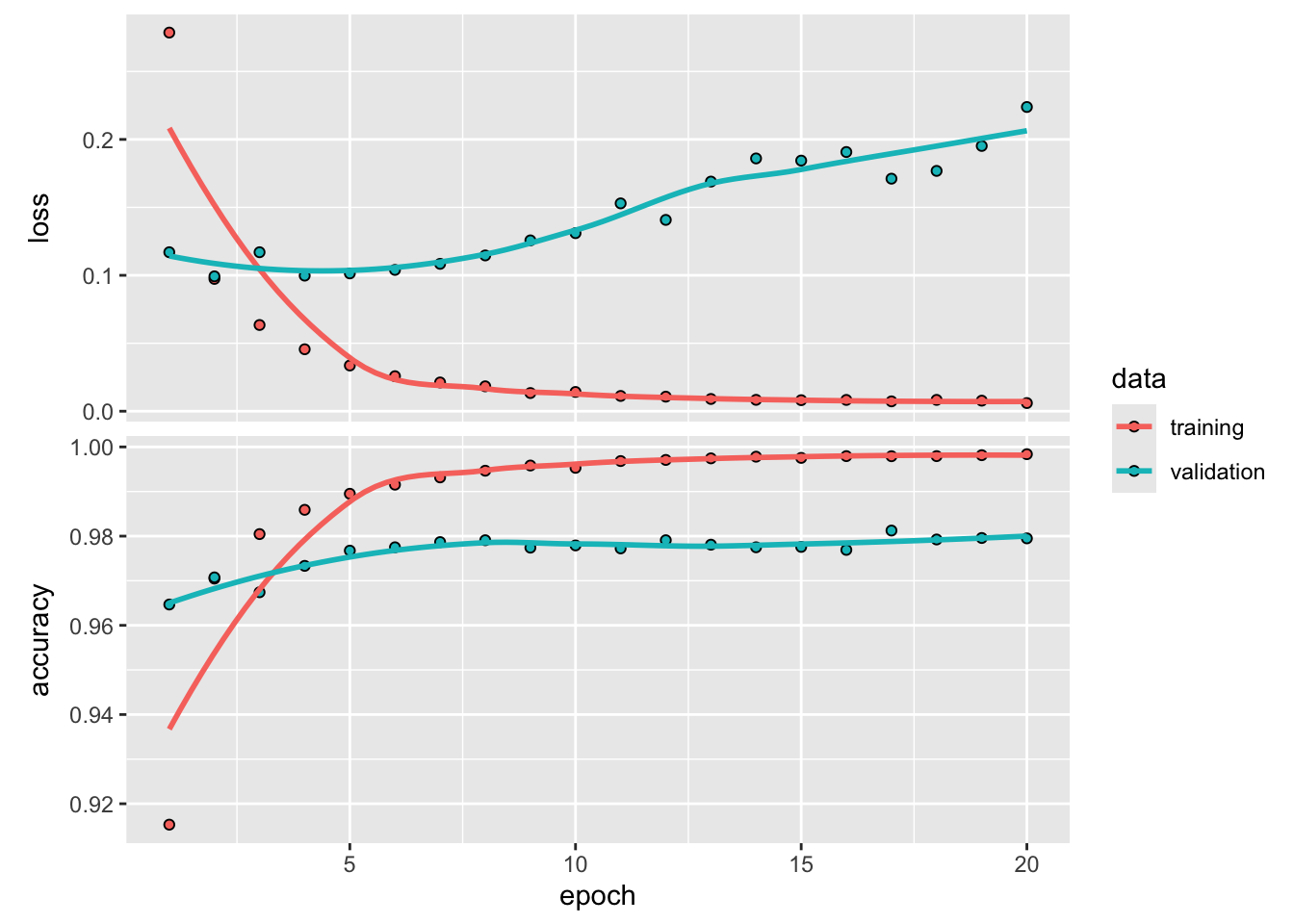
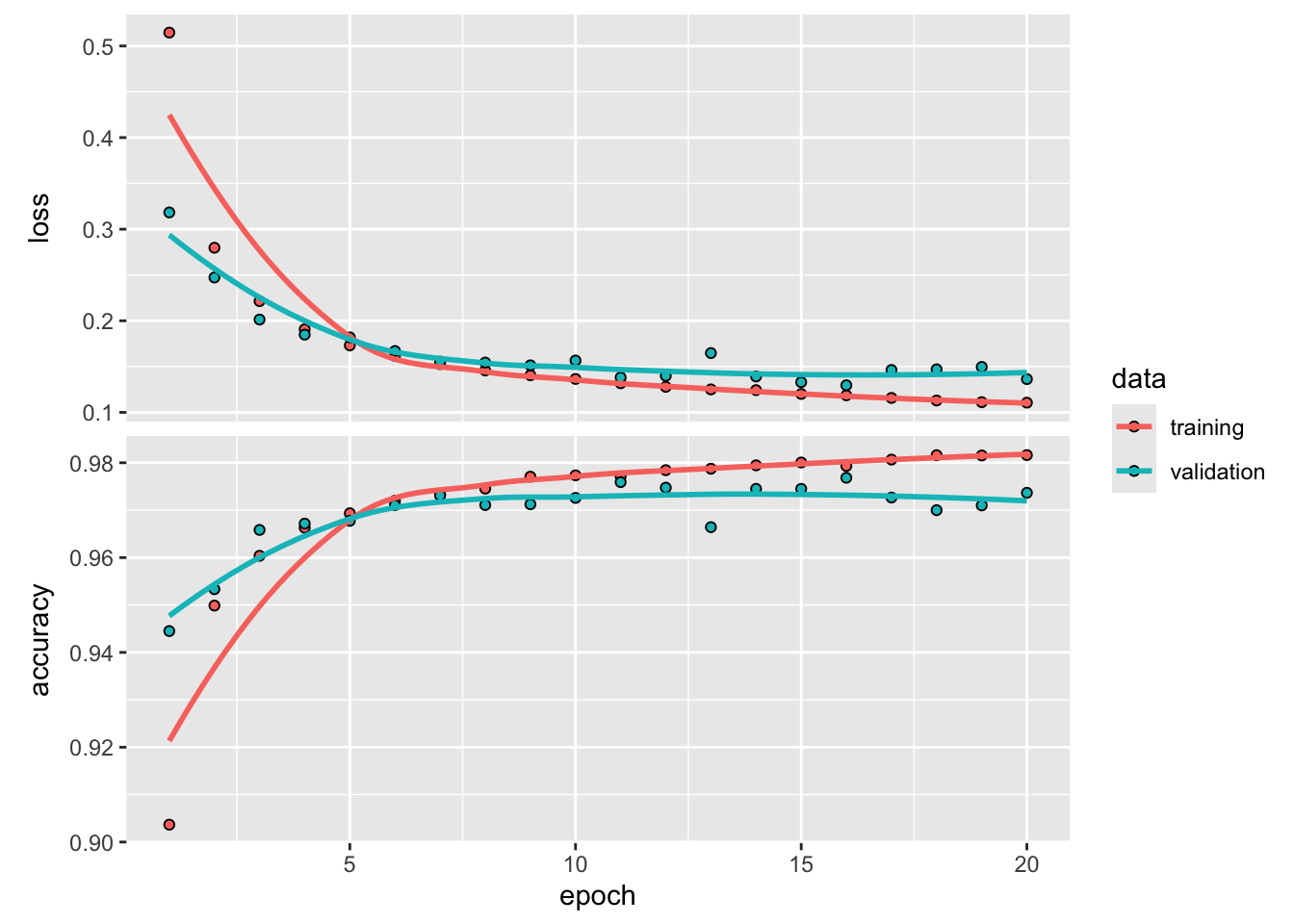
Zacznijmy od nauczenia sieci neuronowej do rozpoznawania cyfr na podstawie obrazów prezentowany wcześniej.
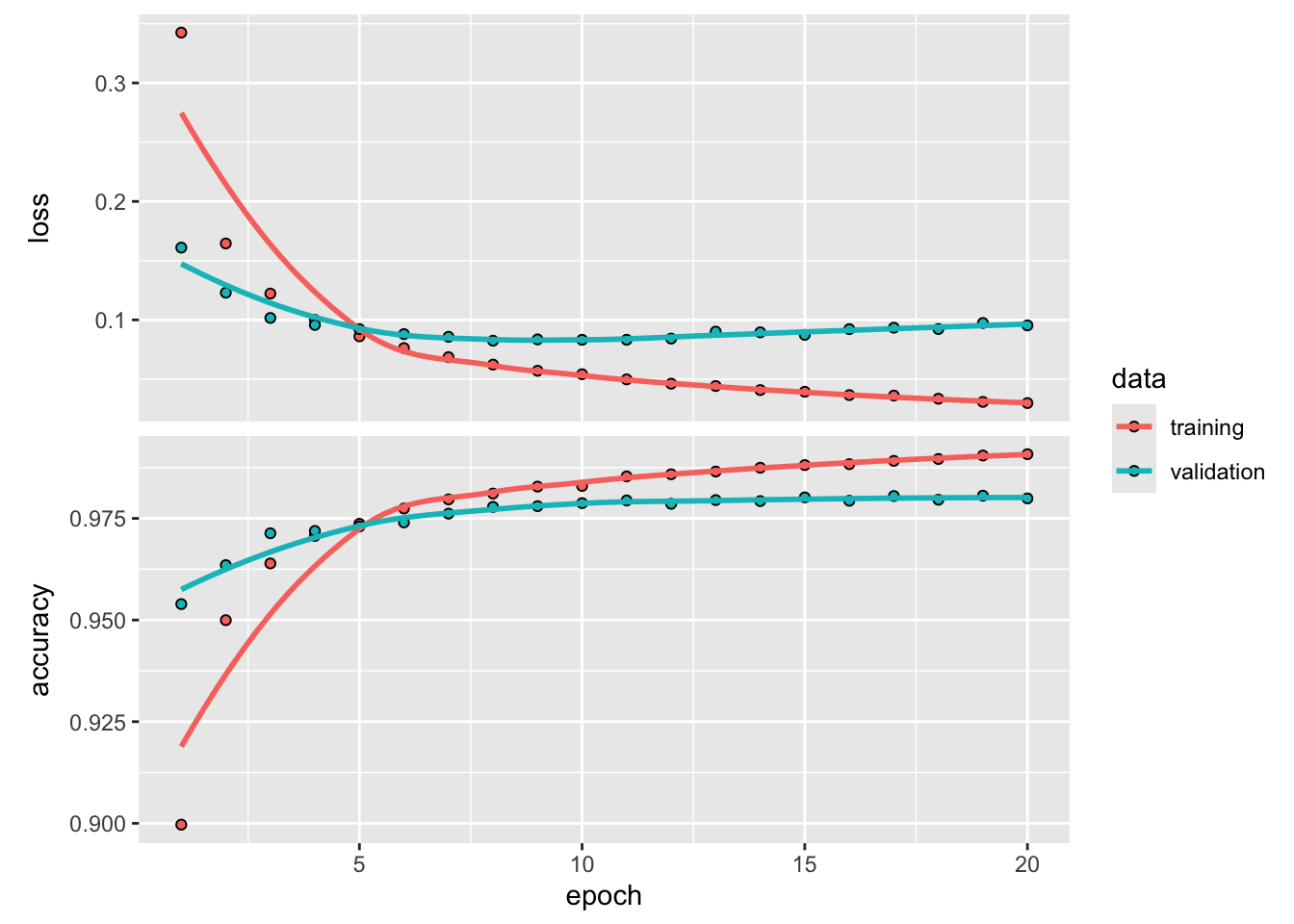
Na podstawie powyższego modelu możemy stwierdzić, że wydajność modelu na odłożonych danych walidacyjnych zawsze osiągała szczyt po kilku epokach, a następnie zaczynała się pogarszać. Overfitting zdarza się w każdym problemie uczenia maszynowego. Nauka radzenia sobie z nadmiernym dopasowaniem jest niezbędna do opanowania uczenia maszynowego.
Podstawowym problemem w uczeniu maszynowym jest konflikt pomiędzy optymalizacją a generalizacją. Optymalizacja odnosi się do procesu dostosowywania modelu w celu uzyskania jak najlepszej wydajności na danych treningowych, podczas gdy generalizacja odnosi się do tego, jak dobrze wyszkolony model radzi sobie na danych, których nigdy wcześniej nie widział.
Na początku treningu optymalizacja i generalizacja są zbieżne: im mniejsza strata na danych treningowych, tym mniejsza strata na danych testowych. Gdy tak się dzieje, mówi się, że twój model jest niedopasowany: wciąż jest miejsce na postęp w zakresie dopasowania; sieć nie jest nauczona jeszcze wszystkich istotnych wzorców w danych treningowych. Jednak po pewnej liczbie iteracji na danych treningowych, generalizacja przestaje się poprawiać, a metryki dla zbioru walidacyjnego nie poprawiają się, a nawet zaczynają się pogarszać: model zaczyna być nadmiernie dopasowany. Oznacza to, że model zaczyna się uczyć wzorców, które są specyficzne dla danych treningowych, ale które są mylące lub nieistotne, gdy chodzi o nowe dane.
Aby zapobiec uczeniu się przez model błędnych lub nieistotnych wzorców występujących w danych treningowych, najlepszym rozwiązaniem jest uzyskanie większej ilości danych treningowych. Model wytrenowany na większej ilości danych będzie naturalnie lepiej generalizował. Jeśli nie jest to możliwe, innym rozwiązaniem jest modulowanie ilości informacji, które model może przechowywać, lub dodanie ograniczeń na informacje, które może przechowywać. Jeśli sieć może sobie pozwolić na zapamiętanie tylko niewielkiej liczby wzorców, proces optymalizacji zmusi ją do skupienia się na najbardziej widocznych wzorcach, które mają większą szansę na dobrą generalizację.
Proces walki z overfittingiem w ten sposób nazywany jest regularyzacją. Zapoznajmy się z kilkoma najpopularniejszymi technikami regularyzacji i zastosujmy je w praktyce, aby poprawić model klasyfikacji.
11.3.1 Redukcja wielkości sieci
Najprostszym sposobem zapobiegania overfittingowi jest zmniejszenie rozmiaru modelu: czyli liczby możliwych do nauczenia się parametrów w modelu (która jest określona przez liczbę warstw i liczbę neuronów na warstwę). W uczeniu głębokim liczba możliwych do nauczenia się parametrów w modelu jest często określana jako pojemność modelu. Intuicyjnie, model z większą liczbą parametrów ma większą zdolność zapamiętywania i dlatego może łatwo nauczyć się idealnego odwzorowania między próbkami treningowymi a ich celami - odwzorowania bez żadnej mocy generalizacji. Na przykład, model z 500000 parametrów binarnych mógłby z łatwością nauczyć się każdej cyfry w zbiorze treningowym MNIST: potrzebowalibyśmy tylko 10 parametrów binarnych dla każdej z 50000 cyfr. Ale taki model byłby bezużyteczny do klasyfikowania nowych próbek. Zawsze należy o tym pamiętać: modele głębokiego uczenia mają tendencję do dobrego dopasowania do danych treningowych, ale prawdziwym wyzwaniem jest generalizacja, a nie dopasowanie.
Z drugiej strony, jeśli sieć ma ograniczone zasoby pamięci, nie będzie w stanie nauczyć się tego odwzorowania tak łatwo; dlatego, aby zminimalizować straty, będzie musiała uciec się do uczenia skompresowanych reprezentacji, które mają moc predykcyjną w odniesieniu do celów - dokładnie ten typ reprezentacji nas interesuje. Jednocześnie pamiętajmy, że powinniśmy używać modeli, które mają wystarczająco dużo parametrów, aby nie były niedopasowane: nasz model nie powinien być ograniczany ze względu na zasoby pamięciowe. Trzeba znaleźć kompromis między zbyt dużą pojemnością a niewystarczającą.
Niestety, nie ma magicznej formuły, aby określić właściwą liczbę warstw lub właściwy rozmiar dla każdej warstwy. Musimy ocenić szereg różnych architektur (oczywiście na zbiorze walidacyjnym, nie na zbiorze testowym), aby znaleźć właściwy rozmiar modelu dla twoich danych. Ogólny tok postępowania w celu znalezienia odpowiedniego rozmiaru modelu polega na rozpoczęciu od stosunkowo niewielkiej liczby warstw i parametrów, a następnie zwiększaniu rozmiaru warstw lub dodawaniu nowych warstw, dopóki nie zobaczymy zjawiska przeuczenia na zbiorze walidacyjnym.
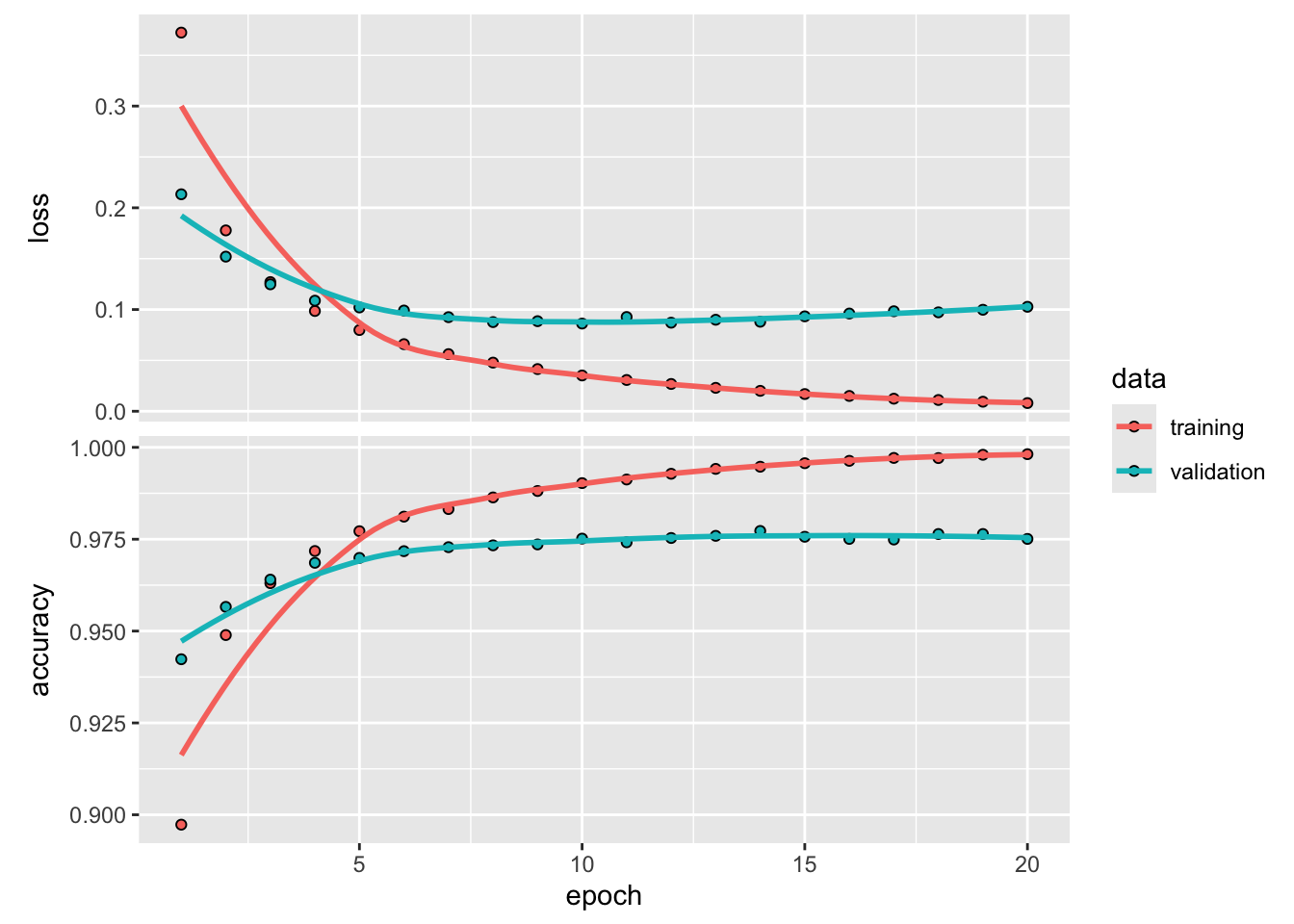
Jak widać z powyższej symulacji dla prostszej sieci zjawisko overffitingu pojawia się później i nie ma tak wyraźnego charakteru.
11.3.2 Regularyzacja za pomocą kar
Podobnie jak w modelach liniowych prostsze modele są mniej podatne na overfitting, również i sieci głębokiego uczenia również podlegają tej zasadzie - jak się mogliśmy przekonać na podstawie powyższego przykładu. Powyższy przykład, ową prostotę modelu realizował poprzez prostą strukturę sieci (uboższy model) ale można go “upraszczać” również inaczej.
Prosty model to model, w którym rozkład wartości parametrów ma mniejszą entropię (lub model z mniejszą liczbą parametrów, jak widzieliśmy w poprzedniej sekcji). Dlatego powszechnym sposobem łagodzenia overfittingu jest nałożenie ograniczeń na złożoność sieci poprzez zmuszenie jej wag do przyjmowania tylko małych wartości, co czyni rozkład wartości wag bardziej regularnym. Nazywa się to regularyzacją wag i odbywa się poprzez dodanie do funkcji straty sieci kosztu związanego z posiadaniem dużych wag. Koszt ten występuje w dwóch postaciach:
L1 - dodany koszt jest proporcjonalny do wartości bezwzględnej współczynników wagowych (norma L1 wag).
L2 - koszt dodany jest proporcjonalny do kwadratu wartości współczynników wagowych (norma L2 wag).
W keras, regularyzacja wagowa jest dodawana poprzez dodanie instancji regularyzatora wagowego do warstw. Należy pamiętać, że regularyzacja jest stosowana do sieci tylko na etapie uczenia, dlatego na zbiorze testowym strata będzie mniejsza niż na treningowym.
Jak widać z powyższego wykresu przez zastosowanie regularyzacji L2 otrzymaliśmy większą zbieżność na obu próbach.
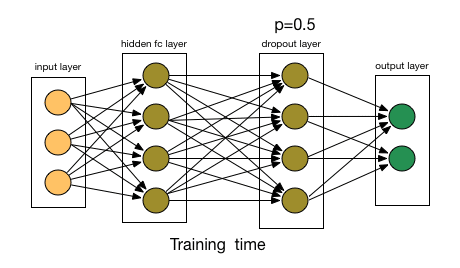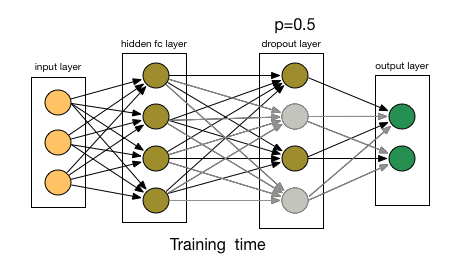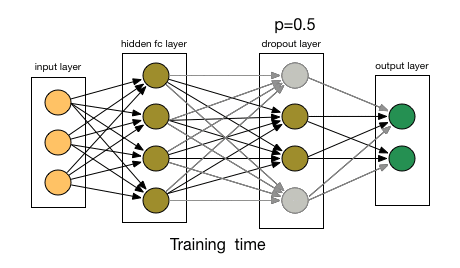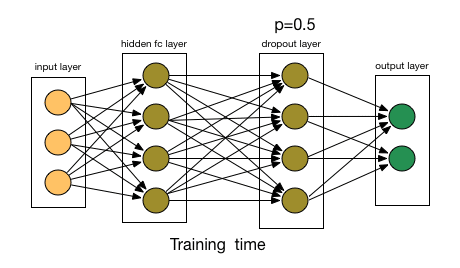
11.3.3 Dropout
Dropout to jedna z najskuteczniejszych i najczęściej stosowanych technik regularizacji sieci neuronowych, opracowana przez Geoffa Hintona i jego studentów z Uniwersytetu w Toronto. Dropout, zastosowany do warstwy, polega na losowym wyrzuceniu (ustawieniu na zero) pewnej liczby cech wyjściowych warstwy podczas treningu. Powiedzmy, że dana warstwa normalnie zwróciłaby podczas treningu wektor [0.2, 0.5, 1.3, 0.8, 1.1] dla danej próbki wejściowej. Po zastosowaniu dropoutu, wektor ten będzie miał kilka zerowych wpisów rozmieszczonych losowo: na przykład [0, 0.5, 1.3, 0, 1.1].
Współczynnik dropoutu to frakcja cech, które mają być wyzerowane; zwykle jest ustawiony między 0,2 a 0,5. W czasie ewaluacji modelu na zbiorze testowym żadne jednostki nie są usuwane; zamiast tego wartości wyjściowe warstwy są skalowane w dół o czynnik równy współczynnikowi usuwania, aby zrównoważyć fakt, że więcej jednostek jest aktywnych niż w czasie treningu. Czyli przykładowo jeśli warstwa miała współczynnik dropout 0,25, to w czasie ewaluacji na zbiorze testowym wartości wyjściowe tej warstwy są mnożone przez 0,75.
Rysunek 11.3: Zasada działania dropout
Ta technika może wydawać się dziwna i przypadkowa. Dlaczego miałoby to pomóc w redukcji overfitting? Hinton mówi, że zainspirował go między innymi mechanizm zapobiegania oszustwom stosowany przez banki. Mówiąc jego własnymi słowami: “Poszedłem do swojego banku. Kasjerzy ciągle się zmieniali i zapytałem jednego z nich, dlaczego. Powiedział, że nie wie, ale są często przenoszeni. Uznałem, że musi to być spowodowane tym, że skuteczne oszukanie banku wymagałoby współpracy między pracownikami. To uświadomiło mi, że losowe usuwanie różnych podzbiorów neuronów na każdym przykładzie zapobiegnie spiskom, a tym samym zmniejszy overfitting.” Główna idea polega na tym, że wprowadzenie szumu do wartości wyjściowych warstwy może rozbić przypadkowe wzorce, które nie są istotne (co Hinton określa jako spiski), które sieć zacznie zapamiętywać, jeśli nie będzie w niej szumu.
W tym rozdziale przedstawimy uniwersalny schemat, który można wykorzystać do rozwiązania każdego problemu uczenia maszynowego. Dyskusja łączy koncepcje, które poznaliśmy w tym rozdziale: definicję problemu, ocenę, inżynierię cech i walkę z overfittingiem.
11.4.1 Definiowanie problemu i przygotowanie zbioru danych
Po pierwsze, musimy zdefiniować problem:
Jakie będą nasze dane wejściowe? Co próbujemy przewidzieć? Możemy nauczyć się przewidywać coś tylko wtedy, gdy mamy dostępne dane treningowe: na przykład, możemy nauczyć się klasyfikować sentyment3 recenzji filmowych tylko wtedy, gdy mamy dostępne zarówno recenzje filmów, jak i adnotacje sentymentu. W związku z tym, dostępność danych jest zwykle czynnikiem ograniczającym na tym etapie (chyba, że mamy środki, aby zapłacić ludziom, aby ci zebrali więcej danych).
Z jakim typem problemu mamy do czynienia? Czy jest to klasyfikacja binarna? Klasyfikacja wieloklasowa? Regresja skalarna? Regresja wektorowa? Klasyfikacja wieloklasowa, wieloetykietowa? Coś innego, jak klastrowanie, generowanie lub uczenie wzmacniające4? Określenie typu problemu pozwoli nam na wybór architektury modelu, funkcji straty i tak dalej.
3 nastawienie
4 ang. reinforcement learning
Nie możemy przejść do następnego etapu, dopóki nie wiemy, jakie są nasze wejścia i wyjścia oraz z jakich danych będziemy korzystać. Bądźmy świadomi hipotez, które stawiamy. Dopóki nie mamy działającego modelu, są to jedynie hipotezy, czekające na potwierdzenie lub unieważnienie. Nie wszystkie problemy można rozwiązać; tylko dlatego, że zebraliśmy przykłady wejść X i celów Y, nie oznacza to bowiem, że X zawiera wystarczająco dużo informacji, aby przewidzieć Y. Na przykład, jeśli próbujemy przewidzieć ruchy akcji na giełdzie, biorąc pod uwagę jej niedawną historię cenową, raczej nam się to nie uda, ponieważ historia cenowa nie zawiera zbyt wielu informacji prognostycznych.
Jedną z klas nierozwiązywalnych problemów, o których powinniśmy wiedzieć, są problemy niestacjonarne. Załóżmy, że próbujemy zbudować silnik rekomendacji do sprzedaży ubrań, trenujemy go na jednym miesiącu danych (sierpień) i chcemy zacząć generować rekomendacje w zimie. Jednym z poważnych problemów jest to, że rodzaje ubrań, które ludzie kupują, zmieniają się z sezonu na sezon: kupowanie ubrań jest zjawiskiem niestacjonarnym w skali kilku miesięcy. To, co próbujemy modelować, zmienia się w czasie. W tym przypadku, właściwym posunięciem jest ciągłe doszkalanie modelu na danych z niedawnej przeszłości lub zbieranie danych w skali czasowej, w której problem jest stacjonarny. Dla problemu cyklicznego, takiego jak kupowanie ubrań, wystarczy kilka lat danych, aby uchwycić sezonową zmienność - ale pamiętaj, aby czas roku był wejściem do modelu!
Pamiętajmy, że uczenie maszynowe może być użyte tylko do zapamiętania wzorców, które są obecne w danych treningowych. Możemy rozpoznać tylko to, co wcześniej widzieliśmy. Używając uczenia maszynowego wyszkolonego na danych z przeszłości do przewidywania przyszłości, przyjmujemy założenie, że przyszłość będzie zachowywać się jak przeszłość, co nie zawsze jest prawdą.
11.4.2 Określenie miary do oceny jakości dopasowania modelu
Aby coś kontrolować, musimy być w stanie to obserwować. Aby osiągnąć sukces, musimy zdefiniować, co rozumiemy przez sukces: dokładność? Nasza miara sukcesu będzie kierowała wyborem funkcji straty: czyli tego, co nasz model będzie optymalizował.
Dla problemów klasyfikacji zrównoważonej, gdzie każda klasa jest mniej więcej równie prawdopodobna, dokładność5 i obszar pod krzywą ROC są powszechnie stosowanymi metrykami. W przypadku problemów związanych z niezbalansowaną klasyfikacją, można użyć precision-recall. Dla problemów rankingowych lub klasyfikacji wieloznakowej, można użyć średniej średniej precyzji6. Nierzadko trzeba też zdefiniować własną, niestandardową metrykę, za pomocą której mierzy się sukces. Aby uzyskać poczucie różnorodności metryk dopasowania uczenia maszynowego i jak odnoszą się one do różnych domen problemowych, warto przejrzeć konkursy na Kaggle (kaggle.com); pokazują one szeroki zakres problemów i metryk.
5accuracy
6mean average precision
11.4.3 Określenie techniki oceny wydajności modelu
Kiedy już wiemy, do czego dążymy, musimy ustalić, jak będziemy mierzyć nasze bieżące postępy. Wcześniej omówiliśmy trzy popularne protokoły oceny:
Utrzymywanie zbioru walidacyjnego typu hold-out - dobry sposób, gdy mamy dużo danych;
Przeprowadzanie k-krotnej walidacji krzyżowej - właściwy wybór, gdy mamy zbyt mało próbek, aby walidacja była wiarygodna.
Przeprowadzanie iterowanej walidacji k-krotnej z losowaniem - bardzo dokładna oceny modelu, gdy dostępnych jest niewiele danych.
W większości przypadków pierwsza będzie działać wystarczająco dobrze.
11.4.4 Przygotuj dane
Kiedy już wiemy, na czym trenujemy, co optymalizujemy i jak oceniamy nasze rozwiązanie, jesteśmy prawie gotowi do rozpoczęcia treningu modeli. Najpierw jednak należy sformatować dane w taki sposób, aby można je było wprowadzić do modelu uczenia maszynowego - tutaj założymy głęboką sieć neuronową:
Jak widzieliśmy wcześniej, nasze dane powinny być sformatowane jako tensory.
Wartości przyjmowane przez te tensory powinny być zazwyczaj skalowane do małych wartości: na przykład w zakresie [-1, 1] lub [0, 1].
Jeśli różne cechy przyjmują wartości w różnych zakresach (dane heterogeniczne), to dane powinny być znormalizowane.
Możesz dokonać inżynierii cech, szczególnie dla problemów z małą liczbą danych.
Gdy tensory danych wejściowych i danych docelowych są gotowe, możemy rozpocząć trenowanie modeli.
11.4.5 Porównanie modelu z modelem bazowym
Naszym celem na tym etapie jest osiągnięcie mocy statystycznej: to znaczy opracowanie małego modelu, który jest w stanie pokonać model bazowy. W przykładzie klasyfikacji cyfr MNIST, wszystko co osiąga dokładność większą niż 0,17 można powiedzieć, że ma moc statystyczną.
7 zwykła heurystyka polegająca na wylosowaniu wynikowej cyfry ma prawdopodobieństwo powodzenia właśnie równe 0,1
Zauważmy, że nie zawsze jest możliwe osiągnięcie takiej mocy statystycznej. Jeśli nie możemy pokonać przyjętej linii bazowej po wypróbowaniu wielu rozsądnych architektur, może się okazać, że odpowiedź na pytanie, które zadajemy, nie jest dostępna na podstawie danych wejściowych. Pamiętajmy, że stawiamy dwie hipotezy:
zmienną wynikową można przewidzieć, na postawie danych wejściowych;
dane zawierają wystarczająco dużo informacji, aby poznać związek pomiędzy wejściami i wyjściami.
Może się okazać, że te hipotezy są fałszywe. Zakładając, że wszystko idzie dobrze, musimy dokonać trzech kluczowych wyborów, aby zbudować swój pierwszy działający model:
funkcja aktywacji ostatniej warstwy - ustanawia ona praktyczne ograniczenia na wyjściu sieci. Na przykład w sieci ze zmienną wynikową dwuwartościową (dwie kategorie) powinniśmy ustawić aktywację sigmoid.
funkcja straty - powinna odpowiadać rodzajowi problemu, który próbujemy rozwiązać. Na przykład w przykładzie MNIST użyto categorical_crossentropy.
konfiguracja procedury optymalizacji - jakiego optymalizatora użyjemy? Jaki będzie jego współczynnik szybkości uczenia? W większości przypadków bezpiecznie jest użyć rmsprop lub adam i jego domyślnego współczynnika uczenia.
Jeżeli chodzi o wybór funkcji straty, zauważmy, że nie zawsze jest możliwa bezpośrednia optymalizacja dla metryki, która mierzy dopasowanie w danym problemie. Czasami nie ma łatwego sposobu na przekształcenie metryki w funkcję straty; w końcu funkcje straty, muszą być obliczalne biorąc pod uwagę tylko partię danych (idealnie, funkcja straty powinna być obliczalna dla zaledwie jednego punktu danych) i musi być różniczkowalna (w przeciwnym razie nie można użyć wstecznej propagacji do trenowania sieci). Na przykład, szeroko stosowana metryka klasyfikacyjna ROC AUC nie może być bezpośrednio optymalizowana. Dlatego w zadaniach klasyfikacyjnych w jej miejsce używa się entropii krzyżowej (ang. cross-entropy). Można mieć nadzieję, że im niższa będzie entropia krzyżowa, tym wyższy będzie ROC-AUC.
11.4.6 Skalowanie w górę
Kiedy już uzyskamy model, który ma moc statystyczną, pojawia się pytanie, czy nasz model jest wystarczająco skuteczny? Czy ma on wystarczająco dużo warstw i parametrów, aby prawidłowo modelować dany problem? Na przykład, sieć z pojedynczą warstwą ukrytą z dwoma neuronami miałaby moc statystyczną dla zbioru MNIST, ale nie byłaby wystarczająca do dobrego rozwiązania problemu. Pamiętajmy jednak, że w uczeniu maszynowym stale występuje “walka” między optymalizacją a generalizacją; idealny model to model pomiędzy niedostatecznym dopasowaniem a nadmiernym dopasowaniem. Aby dowiedzieć się, gdzie leży ta granica, najpierw trzeba ją przekroczyć 😎.
Aby dowiedzieć się, jak duży model będzie potrzebny, musimy opracować model, który jest nadmiernie dopasowany. Można to łatwo osiągnąć, realizując następujące kroki:
Dodajmy warstwy.
Sprawmy, by warstwy były większe (więcej neuronów).
Dłużej trenujmy sieć (więcej epok).
Zawsze monitorujmy stratę na zbiorze treningowym i walidacyjnym, jak również wartości wszystkich metryk, na których nam zależy. Kiedy widzimy, że wydajność modelu na danych walidacyjnych zaczyna się pogarszać, osiągnęliśmy nadmierne dopasowanie. Następnym etapem jest rozpoczęcie regularyzacji i dostrajania modelu, aby zbliżyć się jak najbardziej do idealnego modelu, który nie jest ani niedopasowany, ani nadmiernie dopasowany.
11.4.7 Regularyzacja modelu
Ten krok zajmie najwięcej czasu: będziemy wielokrotnie modyfikowali nasz model, trenowali go, oceniali na danych walidacyjnych (w tym momencie nie na danych testowych), ponownie go modyfikowali i powtarzali tą procedurę, aż model będzie tak dobry, jak to tylko możliwe. Oto kilka rzeczy, które powinniśmy wypróbować:
dodaj warstwy dropout;
spróbujmy różnych architektur - dodajmy lub usuńmy warstwy;
dodajmy regularyzację L1 i/lub L2.
wypróbujmy różne hiperparametry (takie jak liczba jednostek na warstwę lub szybkość uczenia optymalizatora), aby znaleźć optymalną konfigurację;
opcjonalnie, wykonajmy inżynierię cech - dodajmy nowe cechy lub usuńmy cechy, które nie wydają się być informacyjne.
Należy pamiętać o tym, że za każdym razem, gdy używamy informacji zwrotnej z procesu walidacji do dostrojenia modelu, do modelu wyciekają informacje o procesie walidacji. Powtarzając to tylko kilka razy, nie jest to wielki problem; ale robiąc to systematycznie przez wiele iteracji, w końcu spowoduje to, że nasz model będzie nadmiernie dopasowany do walidacji (nawet jeśli żaden model nie jest trenowany bezpośrednio na żadnych danych walidacyjnych). To sprawia, że proces oceny jest mniej wiarygodny.
Po opracowaniu wystarczająco dobrej konfiguracji modelu, możemy wytrenować nasz ostateczny model na wszystkich dostępnych danych (treningowych i walidacyjnych) i ocenić go po raz ostatni na zbiorze testowym. Jeśli okaże się, że wydajność na zestawie testowym jest znacznie gorsza niż wydajność zmierzona na danych walidacyjnych, może to oznaczać, że albo nasza procedura walidacji nie była wiarygodna, albo wcześniej pojawiło się zjawisko nadmiernego dopasowania do danych walidacyjnych podczas dostrajania parametrów modelu. W tym przypadku możemy zmienić procedurę oceny modelu na bardziej wiarygodną (jak np. iterowana walidacja k-krotna).