2 Historia wizji komputerowej
Naukowcy zajmujący się widzeniem komputerowym równolegle rozwijają matematyczne techniki odzyskiwania trójwymiarowego kształtu i wyglądu obiektów na obrazach. Postęp w tej dziedzinie w ciągu ostatnich dwóch dekad był błyskawiczny. Obecnie dysponujemy niezawodnymi technikami dokładnego obliczania trójwymiarowego modelu otoczenia z tysięcy częściowo nakładających się na siebie zdjęć. Biorąc pod uwagę wystarczająco duży zestaw obrazów danego obiektu lub fasady, możemy stworzyć dokładne, gęste modele 3D powierzchni przy użyciu dopasowania stereo. Możemy nawet, z umiarkowanym sukcesem, wyznaczyć większość osób i obiektów na fotografii. Jednak mimo tych wszystkich postępów marzenie o tym, by komputer objaśniał obraz na tym samym poziomie szczegółowości i przyczynowości co dwuletnie dziecko, pozostaje nieosiągalne.
Dlaczego widzenie jest tak trudne? Po części dlatego, że jest to problem odwrotny, w którym staramy się odzyskać pewne niewiadome, mając za mało informacji, by w pełni określić rozwiązanie. Musimy więc uciekać się do modeli opartych na fizyce i probabilistyce lub do uczenia maszynowego na dużych zbiorach przykładów, aby wyróżnić potencjalne rozwiązania. Jednak modelowanie świata wizualnego w całej jego bogatej złożoności jest o wiele trudniejsze niż, powiedzmy, modelowanie dźwięku, który wytwarzamy podczas mówienia.
Modele naprzód (ang. forward), których używamy w wizji komputerowej, są zwykle opracowywane w fizyce (radiometria, optyka i projektowanie czujników) oraz w grafice komputerowej. Obie te dziedziny modelują poruszanie się obiektów, jak światło odbija się od ich powierzchni, jak jest rozpraszane przez atmosferę, załamywane przez soczewki kamery (lub ludzkie oczy) i wreszcie rzutowane na płaską (lub zakrzywioną) płaszczyznę obrazu. Chociaż grafika komputerowa nie jest jeszcze doskonała, w wielu dziedzinach, takich jak renderowanie nieruchomej sceny złożonej z przedmiotów codziennego użytku lub animowanie wymarłych stworzeń, takich jak dinozaury, iluzja rzeczywistości jest w zasadzie zapewniona.
W wizji komputerowej staramy się zrobić coś odwrotnego, tzn. opisać świat, który widzimy na jednym lub kilku obrazach i zrekonstruować jego właściwości, takie jak kształt, oświetlenie i rozkład kolorów. Zadziwiające jest, że ludzie i zwierzęta robią to tak bez wysiłku, podczas gdy algorytmy widzenia komputerowego są tak podatne na błędy. Ludzie, którzy nie zajmowali się tą dziedziną, często nie doceniają trudności problemu. To błędne przekonanie, że widzenie powinno być łatwe, sięga początków sztucznej inteligencji, kiedy to początkowo uważano, że kognitywne (logiczne dowodzenie i planowanie) części inteligencji są z natury trudniejsze niż komponenty percepcyjne („Mind as Machine: A History of Cognitive Science” 2007).
Dobrą wiadomością jest to, że widzenie komputerowe jest dziś wykorzystywane w wielu różnych zastosowaniach w świecie rzeczywistym, które obejmują:
- Optyczne rozpoznawanie znaków (OCR): odczytywanie odręcznych kodów pocztowych na listach oraz automatyczne rozpoznawanie tablic rejestracyjnych (ANPR);
- Kontrola maszyn: szybka kontrola części w celu zapewnienia jakości przy użyciu wizji stereoskopowej ze specjalistycznym oświetleniem do pomiaru tolerancji na skrzydłach samolotów lub częściach karoserii samochodowej lub szukanie defektów w odlewach stalowych przy użyciu wizji rentgenowskiej;
- Handel detaliczny: rozpoznawanie obiektów dla zautomatyzowanych stanowisk kasowych i w pełni zautomatyzowanych sklepów;
- Logistyka magazynowa: autonomiczne dostawy paczek i “napędy” przenoszące palety oraz kompletacja części przez manipulatory robotyczne;
- Obrazowanie medyczne: rejestrowanie obrazów przedoperacyjnych i śródoperacyjnych lub wykonywanie długoterminowych badań morfologii mózgu ludzi w miarę ich starzenia się;
- Pojazdy samojezdne: zdolne do jazdy od punktu do punktu, jak również do autonomicznego lotu;
- Budowa modeli 3D (fotogrametria): w pełni zautomatyzowana budowa modeli 3D ze zdjęć lotniczych i z drona;
- Łączenie ruchu: łączenie obrazów generowanych komputerowo (CGI) z materiałem filmowym z życia wziętym poprzez śledzenie punktów charakterystycznych w źródłowym materiale wideo w celu oszacowania ruchu kamery 3D i kształtu otoczenia. Takie techniki są szeroko stosowane w Hollywood, np. w filmach takich jak Jurassic Park; wymagają one również zastosowania precyzyjnego matchowania w celu wstawienia nowych elementów pomiędzy elementy pierwszego planu i tła;
- Śledzenie ruchu: wykorzystywanie znaczników retro-refleksyjnych oglądanych z wielu kamer lub innych technik opartych na wizji w celu uchwycenia aktorów na potrzeby animacji komputerowej;
- Nadzór: monitorowanie intruzów, analizowanie ruchu na drogach i monitorowanie basenów pod kątem ofiar utonięć;
- Rozpoznawanie odcisków palców i biometria: do automatycznego uwierzytelniania dostępu oraz do zastosowań kryminalistycznych.
Oprócz tych wszystkich zastosowań przemysłowych, istnieją niezliczone zastosowania na poziomie konsumenckim, które można zrobić z własnymi zdjęciami i wideo. Należą do nich:
- Zszywanie (ang. stitching): przekształcanie nakładających się na siebie zdjęć w jedną, płynnie zszytą panoramę;
- Exposure bracketing: łączenie wielu ekspozycji wykonanych w trudnych warunkach oświetleniowych (silne światło słoneczne i cienie) w jedno doskonale naświetlone zdjęcie;
- Morphing: przekształcanie zdjęcia jednego z przyjaciół w inne, przy użyciu płynnego przejścia morficznego (np. nałożenie tworzy przyjaciela na pysk lwa);
- Modelowanie 3D: przekształcanie jednego lub więcej ujęć w model 3D fotografowanego obiektu lub osoby;
- Ruch i stabilizacja dopasowania wideo: wstawianie obrazów 2D lub modeli 3D do filmów poprzez automatyczne śledzenie pobliskich punktów odniesienia lub wykorzystanie oszacowania ruchu w celu usunięcia drgań z filmów;
- Spacer po zdjęciach: poruszanie się po dużej kolekcji zdjęć, np. po wnętrzu domu, poprzez przelatywanie pomiędzy różnymi zdjęciami w 3D.
2.1 Lata ’70
Kiedy wizja komputerowa po raz pierwszy pojawiła się na początku lat siedemdziesiątych, była postrzegana jako wizualny komponent percepcji ambitnego programu naśladowania ludzkiej inteligencji i obdarzenia robotów inteligentnym zachowaniem. W tym czasie niektórzy z pionierów sztucznej inteligencji i robotyki (w miejscach takich jak MIT, Stanford) wierzyli, że rozwiązanie problemu “wejścia wizualnego” będzie łatwym krokiem na drodze do rozwiązania trudniejszych problemów, takich jak rozumowanie na wyższym poziomie i planowanie. Według jednej ze znanych historii, w 1966 roku Marvin Minsky z MIT poprosił swojego studenta Geralda Jay Sussmana o “spędzenie lata na podłączeniu kamery do komputera i nakłonieniu komputera do opisania tego, co widział”. Obecnie wiemy, że problem jest nieco trudniejszy niż wówczas się wydawało.
Tym, co odróżniało widzenie komputerowe od istniejącej już dziedziny cyfrowej obróbki obrazów, była chęć odzyskania trójwymiarowej struktury świata z obrazów i wykorzystania tego jako kroku w kierunku pełnego zrozumienia prezentowanej sceny. Winston (1976) oraz Hanson (1978) dostarczają dwóch zbiorów klasycznych prac z tego wczesnego okresu. Wczesne próby zrozumienia sceny polegały na wyodrębnieniu krawędzi, a następnie wnioskowaniu o strukturze 3D obiektu lub bloków z topologicznej struktury linii 2D Roberts (1980).
Jakościowe podejście do rozumienia intensywności i zmienności cieniowania oraz wyjaśniania ich przez efekty zjawisk formowania się obrazu, takich jak orientacja powierzchni i cienie, zostało spopularyzowane przez Barrow i Tenenbaum (1981) w ich pracy na temat obrazów wewnętrznych. W tym czasie opracowano również bardziej ilościowe podejścia do wizji komputerowej, w tym pierwszy z wielu opartych na cechach algorytmów korespondencji stereo (Dev 1975; „Cooperative Computation of Stereo Disparity | Science”, b.d.; Barnard i Fischler 1982).
2.2 Lata ’80
W latach ’80 ubiegłego wieku wiele uwagi poświęcono bardziej wyrafinowanym technikom matematycznym służącym do przeprowadzania ilościowej analizy obrazów i scen. Piramidy obrazów zaczęły być powszechnie stosowane do wykonywania zadań takich jak mieszanie obrazów i wyszukiwanie korespondencji coarse-to-fine. Wykorzystanie stereo jako ilościowej wskazówki kształtu zostało rozszerzone o szeroką gamę technik shape-from-X, w tym shape from shading (Horn, b.d.; Blake, Zisserman, i Knowles 1985).

W tym okresie prowadzono również badania nad lepszym wykrywaniem krawędzi i konturów (Canny 1986; Nalwa i Binford 1986), stereografii fotometrycznej (Woodham 1981) oraz kształty z tekstur (Witkin 1981), w tym wprowadzono dynamicznie ewoluujące trackery konturów, takie jak węże, a także trójwymiarowe modele oparte na fizyce. Naukowcy zauważyli, że wiele algorytmów detekcji stereoskopowej, przepływu, shape-from-X i krawędzi może być zunifikowanych lub przynajmniej opisanych przy użyciu tych samych ram matematycznych, jeśli zostaną one postawione jako problemy optymalizacji wariacyjnej i uodpornione (dobrze postawione) przy użyciu regularyzacji.
Nieco później wprowadzono warianty on-line algorytmów MRF (ang. Markov Random Field), które modelowały i aktualizowały niepewności za pomocą filtru Kalmana. Podjęto również próby odwzorowania zarówno algorytmów regularyzowanych jak i MRF na sprzęt zrównoleglony (ang. parallel). Książka (Fischler i Firschein 1987) zawiera zbiór artykułów skupiających się na wszystkich tych tematach (stereo, przepływ, regularność, MRF, a nawet widzenie wyższego poziomu).
2.3 Lata ’90
Podczas gdy wiele z wcześniej wymienionych tematów było nadal eksplorowanych, kilka z nich stało się znacznie bardziej aktywnych. Nagły wzrost aktywności w zakresie wykorzystania niezmienników projekcyjnych do celów rozpoznania ruchu (Mundy i Zisserman 1992) przerodził się w skoordynowane wysiłki zmierzające do rozwiązania problemu structure from motion. Wiele początkowych działań skierowanych było na rekonstrukcje rzutowe, które nie wymagają kalibracji kamery. Równolegle, techniki faktoryzacji zostały opracowane w celu efektywnego rozwiązywania problemów, dla których miały zastosowanie przybliżenia ortograficzne kamery, a następnie rozszerzone na przypadek perspektywiczny.
W końcu zaczęto stosować pełną optymalizację globalną, która później została uznana za tożsamą z technikami dopasowania wiązki, tradycyjnie stosowanymi w fotogrametrii. W pełni zautomatyzowane systemy modelowania 3D zostały zbudowane przy użyciu tych technik.
Prace rozpoczęte w latach 80-tych nad wykorzystaniem szczegółowych pomiarów barwy i natężenia światła w połączeniu z dokładnymi modelami fizycznymi transportu promieniowania i tworzenia kolorowych obrazów stworzyły własną dziedzinę znaną jako widzenie oparte na fizyce. Algorytmy stereo na podstawie wielu obrazów, które tworzą kompletne powierzchnie 3D były również aktywnym tematem badań, który jest aktualny do dziś.
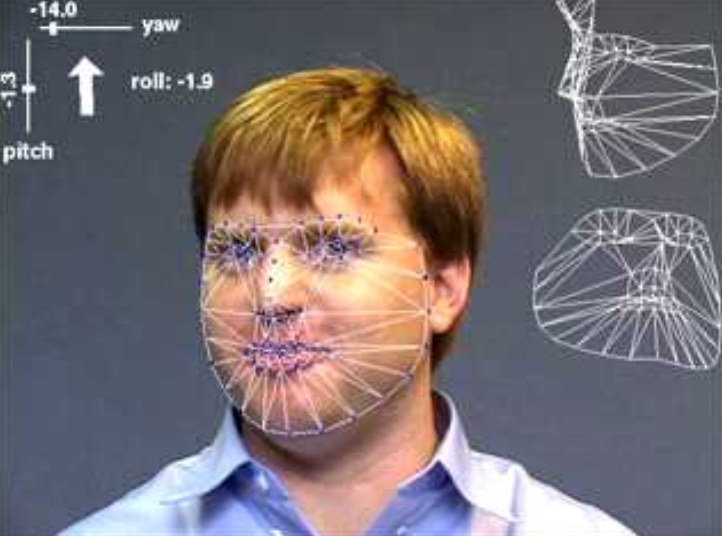
Algorytmy śledzenia również uległy dużej poprawie, w tym śledzenie konturów z wykorzystaniem aktywnych konturów, takich jak węże (Kass, Witkin, i Terzopoulos 1988), filtry cząsteczkowe (Blake i Isard 2012) i zbiorów poziomicowych (ang. level set) (Malladi, Sethian, i Vemuri 1995), a także techniki oparte na intensywności (bezpośrednie), często stosowane do śledzenia twarzy.
Segmentacja obrazów, temat, który jest aktywny od początku wizji komputerowej, był również aktywnym tematem badań, produkując techniki oparte na minimalnej energii i minimalnej długości opisu, znormalizowanych cięciach i średnim przesunięciu.
Zaczęły pojawiać się techniki uczenia statystycznego, najpierw w zastosowaniu analizy składowych głównych, eigenface do rozpoznawania twarzy oraz liniowych systemów dynamicznych do śledzenia krzywych.
Być może najbardziej zauważalnym rozwojem w dziedzinie widzenia komputerowego w tej dekadzie była zwiększona interakcja z grafiką komputerową, zwłaszcza w interdyscyplinarnym obszarze modelowania i renderowania opartego na obrazach. Pomysł manipulowania obrazami świata rzeczywistego bezpośrednio w celu tworzenia nowych animacji po raz pierwszy stał się znany dzięki technikom morfingu obrazu.
2.4 Lata ’00
Ta dekada kontynuowała pogłębianie interakcji pomiędzy dziedzinami wizji i grafiki, ale co ważniejsze, przyjęła podejścia oparte na danych i uczeniu się jako kluczowe komponenty wizji. Wiele z tematów wprowadzonych w rubryce renderingu opartego na obrazie, takich jak zszywanie obrazów, przechwytywanie i renderowanie pola świetlnego oraz przechwytywanie obrazów o wysokim zakresie dynamicznym (HDR) poprzez bracketing ekspozycji, zostało ponownie ochrzczonych mianem fotografii obliczeniowej, aby potwierdzić zwiększone wykorzystanie takich technik w codziennej fotografii cyfrowej. Na przykład, szybkie przyjęcie bracketingu ekspozycji do tworzenia obrazów o wysokim zakresie dynamicznym wymagało opracowania algorytmów kompresji dynamiki, aby przekształcić takie obrazy z powrotem do wyników możliwych do wyświetlenia. Oprócz łączenia wielu ekspozycji, opracowano techniki łączenia obrazów z lampą błyskową z ich odpowiednikami bez lampy błyskowej.

Drugim wartym uwagi trendem w tej dekadzie było pojawienie się technik opartych na ekstrakcji cech (połączonych z uczeniem) do rozpoznawania obiektów. Niektóre z godnych uwagi prac w tej dziedzinie obejmują model konstelacji (Ponce i in. 2007; Fergus, Perona, i Zisserman 2007) oraz struktury obrazowe (Felzenszwalb i Huttenlocher 2005). Techniki oparte na cechach dominują również w innych zadaniach rozpoznawania, takich jak rozpoznawanie scen, panoram i lokalizacji. I chociaż cechy oparte na punktach kluczowych (patch-based) dominują w obecnych badaniach, niektóre grupy zajmują się rozpoznawaniem na podstawie konturów i segmentacji regionów.
Innym istotnym trendem tej dekady było opracowanie bardziej wydajnych algorytmów dla złożonych problemów optymalizacji globalnej. Chociaż trend ten rozpoczął się od prac nad cięciami grafów, duży postęp dokonał się również w algorytmach przekazywania informacji, takich jak loopy belief propagation (LBP).
Najbardziej zauważalnym trendem tej dekady, który do tej pory całkowicie opanował rozpoznawanie obrazu i większość innych aspektów widzenia komputerowego, było zastosowanie zaawansowanych technik uczenia maszynowego do problemów widzenia komputerowego. Trend ten zbiegł się w czasie ze zwiększoną dostępnością ogromnych ilości częściowo oznakowanych danych w Internecie, a także ze znacznym wzrostem mocy obliczeniowej, co sprawiło, że uczenie się kategorii obiektów bez użycia starannego nadzoru człowieka stało się bardziej realne.
2.5 Lata ’10
Trend do wykorzystywania dużych etykietowanych zbiorów danych do rozwoju algorytmów uczenia maszynowego stał się falą, która całkowicie zrewolucjonizowała rozwój algorytmów rozpoznawania obrazów, a także innych aplikacji, takich jak denoising i przepływ optyczny, które wcześniej wykorzystywały techniki Bayesa i optymalizacji globalnej. Tendencję tę umożliwił rozwój wysokiej jakości wielkoskalowych anotowanych zbiorów danych, takich jak ImageNet, Microsoft COCO i LVIS. Te zbiory danych dostarczyły nie tylko wiarygodnych metryk do śledzenia postępów algorytmów rozpoznawania i segmentacji semantycznej, ale co ważniejsze, wystarczającej ilości etykietowanych danych do opracowania kompletnych rozwiązań opartych na uczeniu maszynowym.
Innym ważnym trendem był dramatyczny wzrost mocy obliczeniowej dostępny dzięki rozwojowi algorytmów ogólnego przeznaczenia (data-parallel) na jednostkach przetwarzania graficznego (GPU). Przełomowa głęboka sieć neuronowa SuperVision (“AlexNet”), która jako pierwsza wygrała coroczne zawody w rozpoznawaniu obrazów na dużą skalę ImageNet, opierała się na treningu na GPU, a także na szeregu usprawnień technicznych, które przyczyniły się dramatycznie do wzrostu jej wydajności. Po opublikowaniu tej pracy postęp w wykorzystaniu głębokich architektur konwolucyjnych gwałtownie przyspieszył, do tego stopnia, że obecnie są one jedyną architekturą braną pod uwagę w zadaniach rozpoznawania i segmentacji semantycznej, a także preferowaną architekturą w wielu innych zadaniach wizyjnych, w tym w zadaniach przepływu optycznego, denoisingu i wnioskowania o głębi monokularnej (LeCun, Bengio, i Hinton 2015).
Duże zbiory danych i architektury GPU, w połączeniu z szybkim upowszechnianiem nowych idei z tego zakresu poprzez pojawiające się w odpowiednim czasie publikacje na arXiv, a także rozwój języków głębokiego uczenia i otwarty dostęp do modeli sieci neuronowych, przyczyniły się do gwałtownego rozwoju tej dziedziny, zarówno pod względem szybkich postępów i możliwości, jak i samej liczby publikacji i badaczy zajmujących się obecnie tymi tematami. Umożliwiły one również rozszerzenie podejść do rozpoznawania obrazów na zadania związane z rozumieniem wideo, takie jak rozpoznawanie akcji, a także zadania regresji strukturalnej, takie jak estymacja w czasie rzeczywistym wieloosobowej pozy ciała.
Specjalistyczne czujniki i sprzęt do zadań związanych z widzeniem komputerowym również stale się rozwijały. Wprowadzona w 2010 r. kamera głębi Microsoft Kinect szybko stała się podstawowym elementem wielu systemów modelowania 3D i śledzenia osób. W ciągu dekady systemy modelowania i śledzenia kształtu ciała 3D nadal się rozwijały, do tego stopnia, że obecnie możliwe jest wnioskowanie o modelu 3D osoby wraz z gestami i ekspresją na podstawie jednego obrazu.