Po zbudowaniu dwóch lub więcej modeli, kolejnym krokiem jest ich porównanie, aby zrozumieć, który z nich jest najlepszy. W niektórych przypadkach, porównania mogą dotyczyć modelu, gdzie ten sam model może być oceniany z różnymi cechami lub metodami wstępnego przetwarzania. Alternatywnie, porównania między modelami, takie jak porównanie modeli regresji liniowej i lasu losowego, są bardziej powszechnym scenariuszem.
W każdym przypadku wynikiem jest zbiór próbkowanych statystyk zbiorczych (np. RMSE, dokładność itp.) dla każdego modelu. W tym rozdziale zademonstrujemy najpierw, jak można wykorzystać zbiory przepływów pracy do dopasowania wielu modeli. Następnie omówimy ważne aspekty statystyki resamplingu. Na koniec przyjrzymy się, jak formalnie porównać modele (używając testowania hipotez lub podejścia bayesowskiego).
8.1 Tworzenie przepływów pracy do porównania modeli
Do porównania zbudujemy trzy modele regresji liniowej ale z innymi procedurami przygotowania danych.
Zauważmy, że kolumny option i result są teraz wypełnione. Pierwsza zawiera opcje do fit_resamples(), które zostały podane (dla odtwarzalności), a druga kolumna zawiera wyniki uzyskane przez fit_resamples().
Istnieje kilka wygodnych funkcji przeznaczonych do zestawów przepływów pracy, w tym collect_metrics() do zestawiania statystyk wydajności. Możemy też filtrować() dowolną konkretną metrykę, która nas interesuje:
# A tibble: 3 × 9
wflow_id .config preproc model .metric .estimator mean n std_err
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <int> <dbl>
1 basic_lm Preprocesso… recipe line… rmse standard 0.0788 10 0.00241
2 interact_lm Preprocesso… recipe line… rmse standard 0.0784 10 0.00239
3 splines_lm Preprocesso… recipe line… rmse standard 0.0776 10 0.00317
A co z modelem lasu losowego z poprzedniego rozdziału? Możemy go dodać do zestawu, najpierw konwertując go do własnego zestawu przepływów pracy, a następnie wiążąc wiersze. Wymaga to, aby podczas ponownego próbkowania modelu w funkcji sterującej ustawiona była opcja save_workflow = TRUE.
Kod
rf_model<-rand_forest(trees =1000)|>set_engine("ranger")|>set_mode("regression")rf_wflow<-workflow()|>add_formula(Sale_Price~Neighborhood+Gr_Liv_Area+Year_Built+Bldg_Type+Latitude+Longitude)|>add_model(rf_model)rf_res<-rf_wflow|>fit_resamples(resamples =ames_folds, control =keep_pred)four_models<-as_workflow_set(random_forest =rf_res)%>%bind_rows(lm_models)four_models
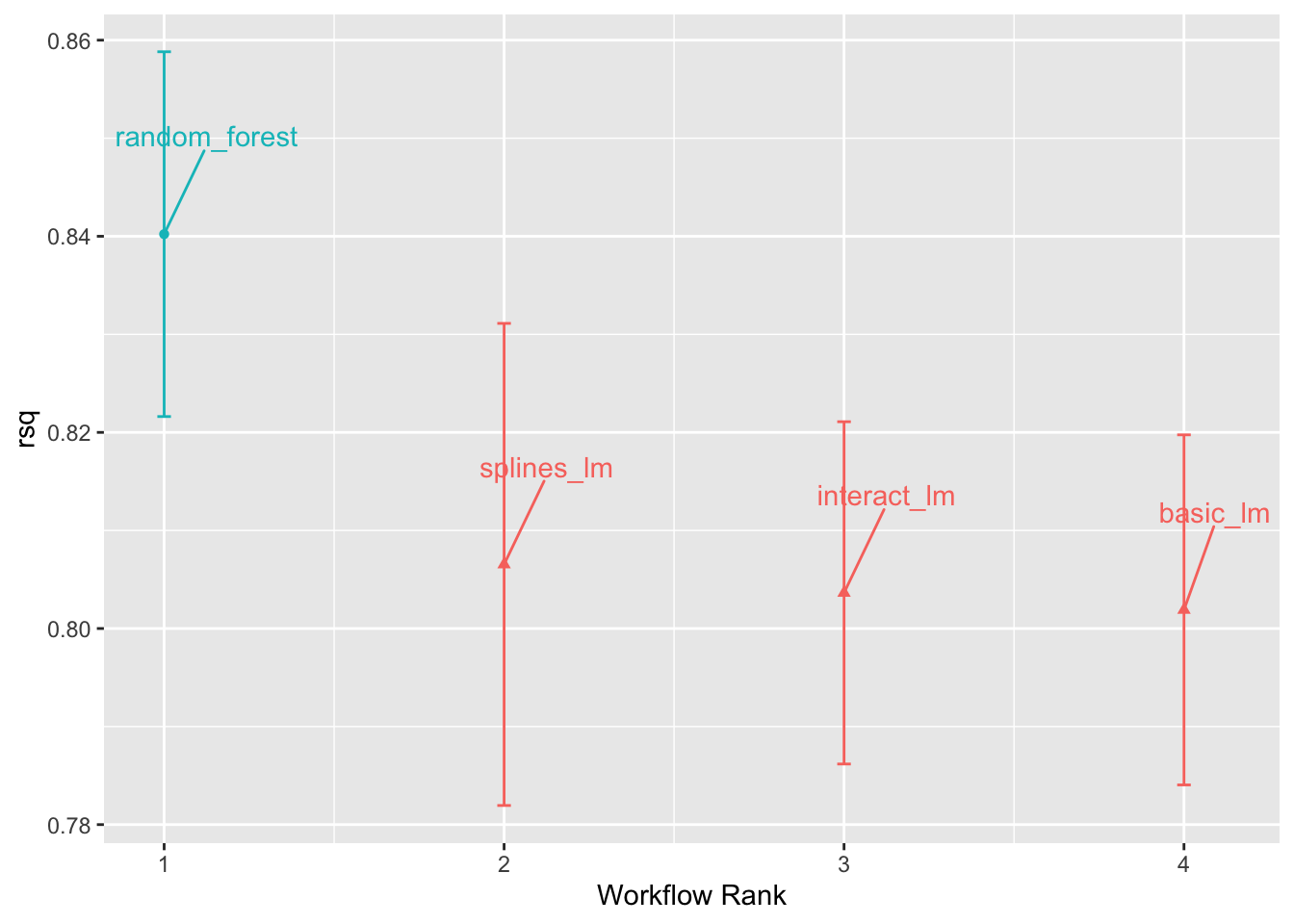
Funkcja autoplot(), której wyniki przedstawiono na Rys. 8.1, pokazuje przedziały ufności dla każdego modelu w kolejności od najlepszego do najgorszego. Jeśli chcemy się skupić na konkretnej mierze wybieramy metric = 'rsq', inaczej funkcja dobierze domyślną metrykę.
Rys. 8.1: Porównanie jakości dopasowania czterech modeli
Z powyższego porównania widać, że model lasu losowego najlepiej radzi sobie z przewidywaniem wartości wynikowej. Jednocześnie widzimy, że kolejne czynności preprocessingu tylko nieznacznie poprawiają dopasowanie.
8.2 Porównanie próbkowań
Stwierdzony powyżej niewielki wpływ kolejnych czynności preprocessingu jest określeniem niejasnym. Można to uściślić stosując test statystyczny do porównania analizowanych wielkości.
Zagrożenie
Przed dokonaniem porównań pomiędzy modelami, ważne jest, abyśmy omówili korelację wewnątrz-próbkową dla statystyk resamplingu. Każdy model był mierzony z tymi samymi foldami walidacji krzyżowej, a wyniki dla tej samej próby mają tendencję do bycia podobnymi.
Innymi słowy, istnieją pewne próbki, dla których wydajność modeli jest niska i inne, w których jest wysoka. W statystyce nazywa się to składnikiem zmienności “próbka do próbki”.
Dla zobrazowania tego problemu zbierzmy poszczególne statystyki resamplingu dla modeli liniowych i lasu losowego. Skupimy się na \(R^2\) dla każdego modelu, która mierzy korelację pomiędzy obserwowanymi i przewidywanymi cenami sprzedaży dla każdego domu. Przefiltrujmy wyniki, aby zachować tylko statystyki \(R^2\), przekształćmy wyniki i obliczmy jak metryki są ze sobą skorelowane.
# A tibble: 4 × 5
term random_forest basic_lm interact_lm splines_lm
<chr> <dbl> <dbl> <dbl> <dbl>
1 random_forest NA 0.906 0.927 0.912
2 basic_lm 0.906 NA 0.995 0.961
3 interact_lm 0.927 0.995 NA 0.960
4 splines_lm 0.912 0.961 0.960 NA
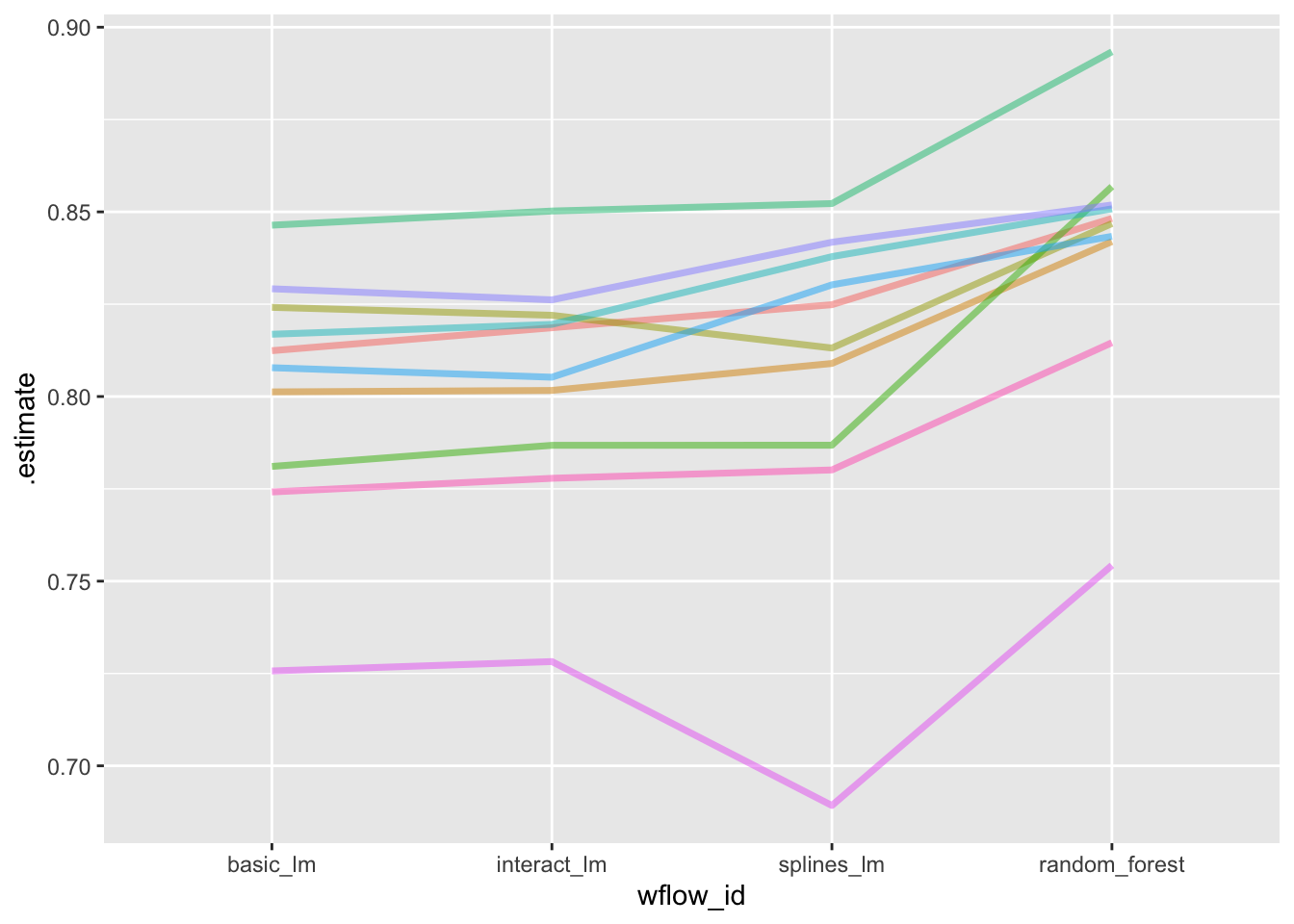
Korelacje te są wysokie, co można też zauważyć wykreślając poziomy \(R^2\) dla różnych modeli i różnych foldów.
Kod
rsq_indiv_estimates%>%mutate(wflow_id =reorder(wflow_id, .estimate))%>%ggplot(aes(x =wflow_id, y =.estimate, group =id, color =id))+geom_line(alpha =.5, lwd =1.25)+theme(legend.position ="none")
Gdyby efektu podobieństwa pomiędzy miarami dla poszczególnych foldów by nie było, wówczas linie nie byłyby równoległe. Można to stwierdzić również na podstawie testów współczynnika korelacji.
Jak widać korelacje te nie są przypadkowe. Stąd wniosek, że korelacje pomiędzy wynikami foldów występują. Będziemy to musieli uwzględnić porównując statystyki \(R^2\). Ponieważ nie interesuje nas efekt foldów a jedynie różnica pomiędzy statystykami poszczególnych modeli, to porównamy je za pomocą modelu liniowego (ANOVA z powtarzanymi pomiarami).
Kod
library(rstatix)rsq_indiv_estimates|>select(wflow_id, id, .estimate)|>anova_test(dv =.estimate, wid =id, within =wflow_id)
ANOVA Table (type III tests)
$ANOVA
Effect DFn DFd F p p<.05 ges
1 wflow_id 3 27 27.13 2.65e-08 * 0.16
$`Mauchly's Test for Sphericity`
Effect W p p<.05
1 wflow_id 0.061 0.000696 *
$`Sphericity Corrections`
Effect GGe DF[GG] p[GG] p[GG]<.05 HFe DF[HF] p[HF]
1 wflow_id 0.634 1.9, 17.11 6.03e-06 * 0.799 2.4, 21.57 5.18e-07
p[HF]<.05
1 *
Gdyby chcieć porównać jedynie model lasu losowego i najgorszego modelu liniowego, można użyć statystyki różnicy.
Kod
compare_lm<-rsq_wider%>%mutate(difference =random_forest-basic_lm)lm(difference~1, data =compare_lm)%>%tidy(conf.int =TRUE)%>%select(estimate, p.value, starts_with("conf"))
# Alternatively, a paired t-test could also be used: rsq_wider%>%with(t.test(random_forest, basic_lm, paired =TRUE))%>%tidy()%>%select(estimate, p.value, starts_with("conf"))