Kod
library(tidymodels)
tidymodels_prefer()
mlp_spec <-
mlp(hidden_units = tune(), penalty = tune(), epochs = tune()) %>%
set_engine("nnet", trace = 0) %>%
set_mode("classification")W tym rozdziale opisano metody przeszukiwania siatki (ang. grid search), które określają możliwe wartości parametrów a priori. Istnieją dwa główne rodzaje siatek. Siatka regularna łączy każdy parametr (z odpowiadającym mu zbiorem możliwych wartości) czynnikowo, tj. poprzez wykorzystanie wszystkich kombinacji zbiorów. Alternatywnie, siatka nieregularna to taka, w której kombinacje parametrów nie są tworzone regularnie.
Zanim przyjrzymy się każdemu z typów bardziej szczegółowo, rozważmy przykładowy model: model perceptronu wielowarstwowego (czyli jednowarstwowej sieci neuronowej). Parametry oznaczone do dostrojenia to:
library(tidymodels)
tidymodels_prefer()
mlp_spec <-
mlp(hidden_units = tune(), penalty = tune(), epochs = tune()) %>%
set_engine("nnet", trace = 0) %>%
set_mode("classification")Argument trace = 0 zapobiega dodatkowemu rejestrowaniu procesu szkolenia. Funkcja extract_parameter_set_dials() może wyodrębnić zbiór argumentów o nieznanych wartościach i ustawia ich obiekty dials:
mlp_param <- extract_parameter_set_dials(mlp_spec)
mlp_param %>% extract_parameter_dials("hidden_units")
mlp_param %>% extract_parameter_dials("penalty")
mlp_param %>% extract_parameter_dials("epochs")To wyjście wskazuje, że obiekty parametrów są kompletne i wyświetla ich domyślne zakresy. Wartości te zostaną wykorzystane do zademonstrowania, jak tworzyć różne typy siatek parametrów.
Regularne siatki są kombinacjami oddzielnych zestawów wartości parametrów. Najpierw użytkownik tworzy odrębny zestaw wartości dla każdego parametru. Liczba możliwych wartości nie musi być taka sama dla każdego parametru. Funkcja tidyr crossing() jest jednym ze sposobów tworzenia siatki regularnej:
# A tibble: 12 × 3
hidden_units penalty epochs
<int> <dbl> <dbl>
1 1 0 100
2 1 0 200
3 1 0.1 100
4 1 0.1 200
5 2 0 100
6 2 0 200
7 2 0.1 100
8 2 0.1 200
9 3 0 100
10 3 0 200
11 3 0.1 100
12 3 0.1 200Obiekt parametru zna zakresy parametrów. Pakiet dials zawiera zestaw funkcji grid_*(), które przyjmują obiekt parametru jako dane wejściowe, aby wytworzyć różne rodzaje siatek. Na przykład:
grid_regular(mlp_param, levels = 2)# A tibble: 8 × 3
hidden_units penalty epochs
<int> <dbl> <int>
1 1 0.0000000001 10
2 10 0.0000000001 10
3 1 1 10
4 10 1 10
5 1 0.0000000001 1000
6 10 0.0000000001 1000
7 1 1 1000
8 10 1 1000Argument levels to liczba poziomów na parametr do utworzenia. Może również przyjąć uszczegółowiony wektor wartości:
mlp_param %>%
grid_regular(levels = c(hidden_units = 3, penalty = 2, epochs = 2))# A tibble: 12 × 3
hidden_units penalty epochs
<int> <dbl> <int>
1 1 0.0000000001 10
2 5 0.0000000001 10
3 10 0.0000000001 10
4 1 1 10
5 5 1 10
6 10 1 10
7 1 0.0000000001 1000
8 5 0.0000000001 1000
9 10 0.0000000001 1000
10 1 1 1000
11 5 1 1000
12 10 1 1000Istnieją techniki tworzenia regularnych siatek, które nie wykorzystują wszystkich możliwych wartości każdego zestawu parametrów. Można również wykorzystać te konstrukcje czynnikowe ułamkowe (Booth i in. 1979).
Jedną z zalet stosowania regularnej siatki jest to, że związki i wzorce między dostrajaniem parametrów i metrykami modelu są łatwo zrozumiałe. Czynnikowa natura tych planów pozwala na zbadanie każdego parametru osobno z niewielką współzależnością między parametrami.
Istnieje kilka możliwości tworzenia nieregularnych siatek. Pierwszą z nich jest użycie losowego próbkowania w całym zakresie parametrów. Funkcja grid_random() generuje niezależne rozkłady jednostajne wartości w całym zakresie parametrów. Jeśli parametr ma powiązane przekształcenie (takie jak mamy dla kary), liczby losowe są generowane w przekształconej skali. Utwórzmy siatkę losową dla parametrów z naszej przykładowej sieci neuronowej:
hidden_units penalty epochs
Min. : 1.000 Min. :0.0000000 Min. : 10.0
1st Qu.: 3.000 1st Qu.:0.0000000 1st Qu.:265.8
Median : 5.000 Median :0.0000061 Median :497.0
Mean : 5.381 Mean :0.0437435 Mean :509.5
3rd Qu.: 8.000 3rd Qu.:0.0026854 3rd Qu.:761.0
Max. :10.000 Max. :0.9814405 Max. :999.0 Dla penalty() liczby losowe są jednostajne w skali logarytmicznej ale wartości w siatce są w jednostkach naturalnych.
Problem z siatkami losowymi polega na tym, że przy małych i średnich siatkach wartości losowe mogą powodować nakładanie się kombinacji parametrów. Ponadto siatka losowa musi pokryć całą przestrzeń parametrów, a prawdopodobieństwo dobrego pokrycia rośnie wraz z liczbą wartości siatki. Nawet dla próbki 20 obserwacji, na Rys. 10.1 widać pewne nakładanie się punktów dla naszego przykładowego perceptronu wielowarstwowego.
library(ggforce)
set.seed(1302)
mlp_param %>%
# The 'original = FALSE' option keeps penalty in log10 units
grid_random(size = 20, original = FALSE) %>%
ggplot(aes(x = .panel_x, y = .panel_y)) +
geom_point() +
geom_blank() +
facet_matrix(vars(hidden_units, penalty, epochs), layer.diag = 2) +
labs(title = "Random design with 20 candidates")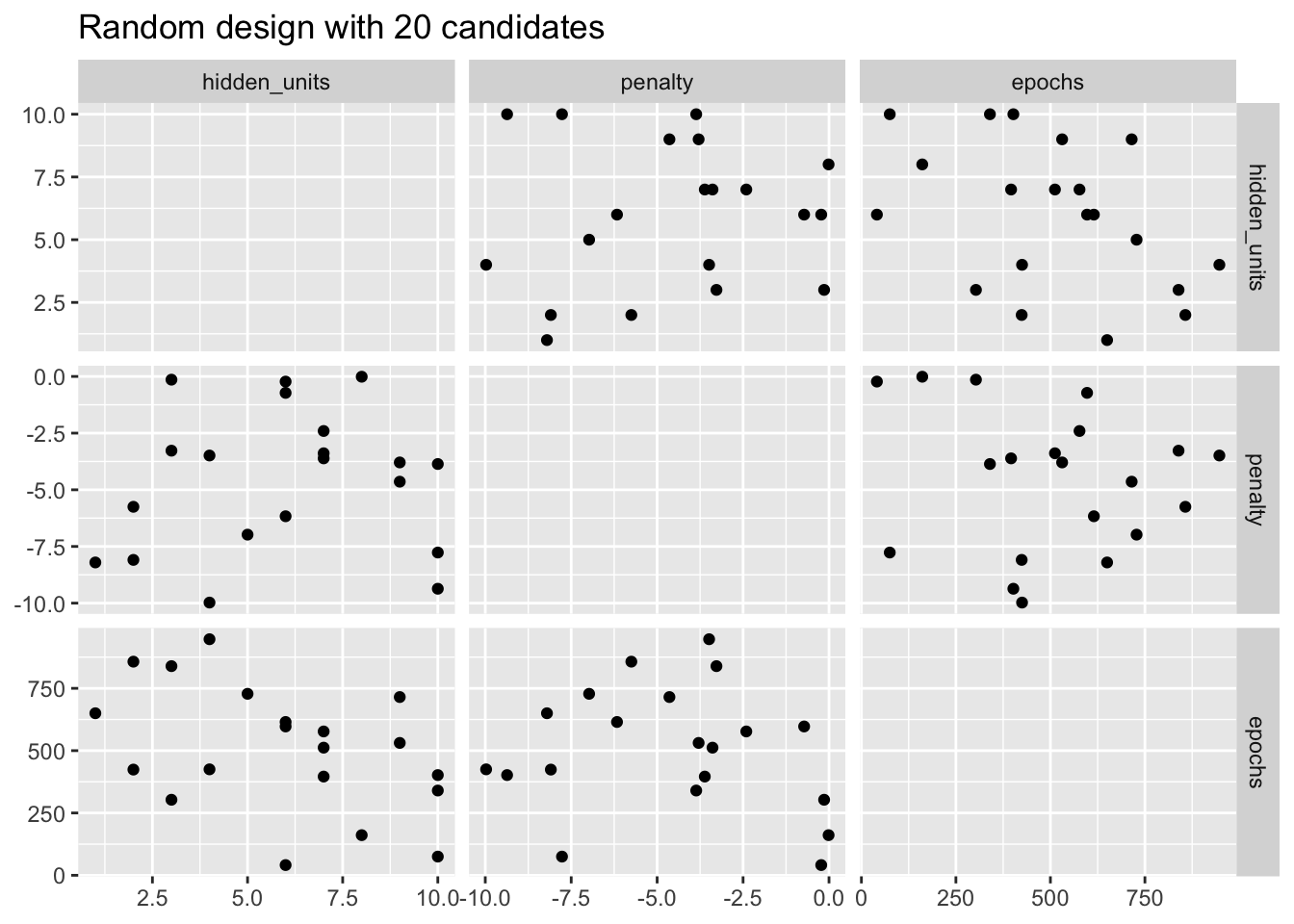
Znacznie lepszym podejściem jest zastosowanie zestawu planów eksperymentalnych zwanych planami wypełniającymi przestrzeń. Chociaż różne metody projektowania mają nieco inne cele, to generalnie znajdują one konfigurację punktów, które pokrywają przestrzeń parametrów z najmniejszym prawdopodobieństwem wystąpienia nakładających się lub nadmiarowych wartości. Przykładami takich planów są hipersześciany łacińskie (ang. Latin hypercube) (McKay, Beckman, i Conover 1979), plany maksymalnej entropii (ang. maximum entropy) (Shewry i Wynn 1987), plany maksymalnej projekcji (ang. maximum projection) (Joseph, Gul, i Ba 2015)i inne.
set.seed(1303)
mlp_param %>%
grid_latin_hypercube(size = 20, original = FALSE) %>%
ggplot(aes(x = .panel_x, y = .panel_y)) +
geom_point() +
geom_blank() +
facet_matrix(vars(hidden_units, penalty, epochs), layer.diag = 2) +
labs(title = "Latin Hypercube design with 20 candidates")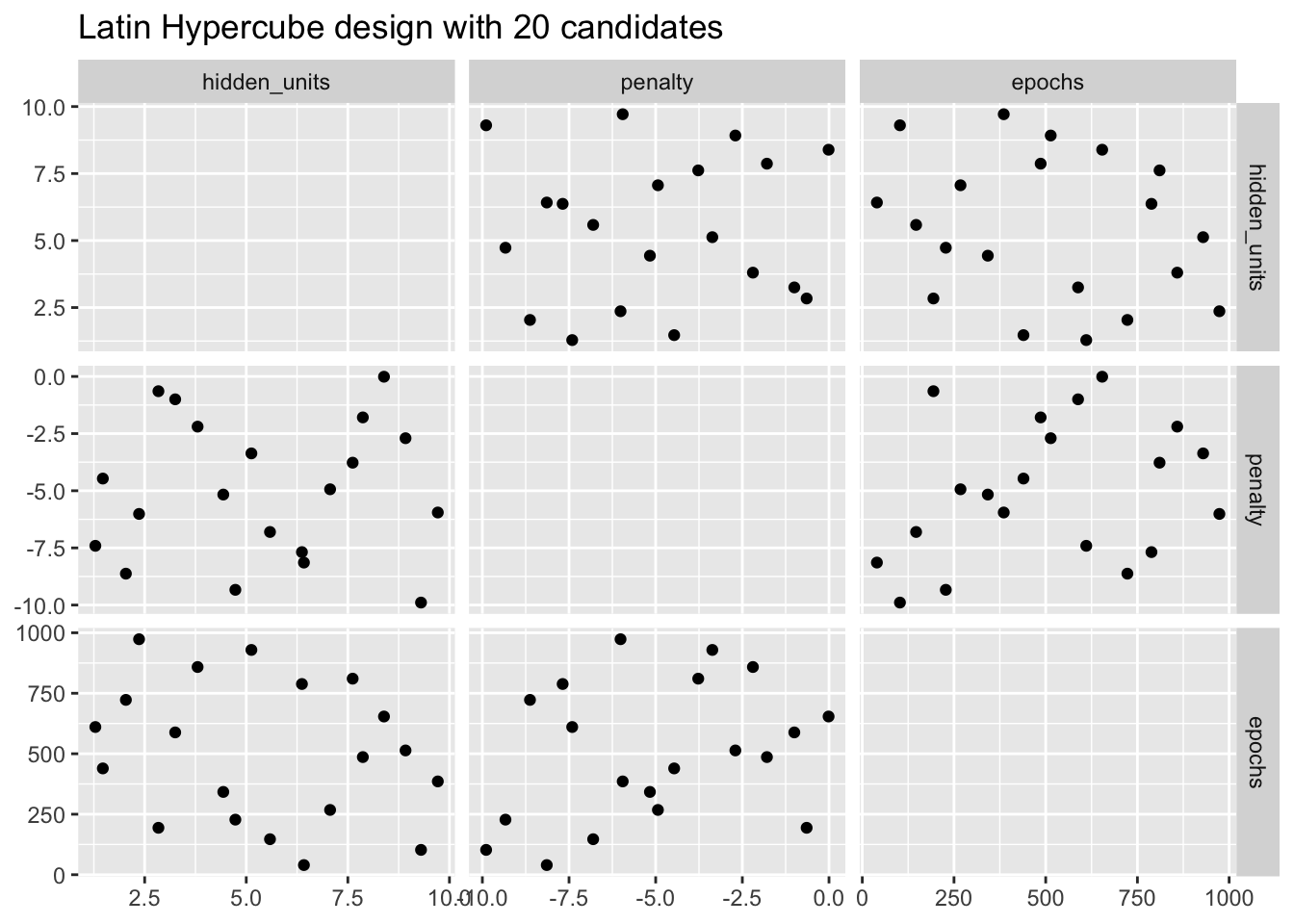
Chociaż nie jest to idealne rozwiązanie, hipersześcian łaciński umieszcza punkty dalej od siebie i pozwala na lepszą eksplorację przestrzeni hiperparametrów.
Konstrukcje wypełniające przestrzeń mogą być bardzo skuteczne w reprezentowaniu przestrzeni parametrów. Domyślnym wzorem używanym przez pakiet tune jest plan kwadratu łacińskiego. Ma on tendencję do tworzenia siatek, które dobrze pokrywają przestrzeń kandydatów i drastycznie zwiększają szanse na znalezienie dobrych wyników.
Aby wybrać najlepszą kombinację parametrów dostrajania, każdy zestaw kandydatów jest oceniany przy użyciu danych, które nie były używane do szkolenia tego modelu. Metody ponownego próbkowania lub pojedynczy zestaw walidacyjny dobrze sprawdzają się w tym celu.
Po resamplingu, użytkownik wybiera najbardziej odpowiedni zestaw parametrów. Sensowne może być wybranie empirycznie najlepszej kombinacji parametrów lub ukierunkowanie wyboru na inne aspekty dopasowania modelu, takie jak prostota modelu.
W tym i następnym rozdziale wykorzystujemy zestaw danych klasyfikacyjnych do demonstracji tuningu modelu. Dane pochodzą od Hill i in. (2007), którzy opracowali zautomatyzowane narzędzie laboratoryjne do mikroskopii w badaniach nad nowotworami. Dane składają się z 56 pomiarów obrazowania na 2019 ludzkich komórkach raka piersi. Predyktory te reprezentują cechy kształtu i intensywności różnych części komórek (np. jądro, granica komórki itp.). Istnieje wysoki stopień korelacji między predyktorami. Na przykład, istnieje kilka różnych predyktorów, które mierzą rozmiar i kształt jądra oraz granicę komórki. Wiele predyktorów ma rozkłady skośne.
Każda komórka należy do jednej z dwóch klas. Ponieważ jest to część zautomatyzowanego testu laboratoryjnego, skupiliśmy się na zdolności przewidywania, a nie wnioskowania.
library(tidymodels)
data(cells)
cells <- cells %>% select(-case)Biorąc pod uwagę wymiary danych, możemy obliczyć metryki wydajności przy użyciu 10-krotnej walidacji krzyżowej:
set.seed(1304)
cell_folds <- vfold_cv(cells)Ze względu na wysoki stopień korelacji pomiędzy predyktorami, sensowne jest użycie ekstrakcji cech PCA do usunięcia efektu współliniowości predyktorów. Poniższy przepis zawiera kroki przekształcenia predyktorów w celu zwiększenia symetrii, znormalizowania ich, aby były w tej samej skali, a następnie przeprowadzenia ekstrakcji cech. Liczba komponentów PCA, które mają być zachowane, jest również dostrajana wraz z parametrami modelu. Wiele predyktorów ma rozkłady skośne. Ponieważ PCA opiera się na wariancji, wartości ekstremalne mogą mieć szkodliwy wpływ na te obliczenia. Aby temu zapobiec, dodajmy krok przepisu polegający na oszacowaniu transformacji Yeo-Johnsona dla każdego predyktora. Krok step_YeoJohnson() występuje w recepturze tuż przed wstępną normalizacją poprzez step_normalize(). Następnie, połączmy recepturę transformacji cech z naszą specyfikacją modelu sieci neuronowej mlp_spec.
mlp_rec <-
recipe(class ~ ., data = cells) %>%
step_YeoJohnson(all_numeric_predictors()) %>%
step_normalize(all_numeric_predictors()) %>%
step_pca(all_numeric_predictors(), num_comp = tune()) %>%
step_normalize(all_numeric_predictors())
mlp_wflow <-
workflow() %>%
add_model(mlp_spec) %>%
add_recipe(mlp_rec)Utwórzmy obiekt parametrów mlp_param, aby dostosować kilka domyślnych zakresów. Możemy zmienić liczbę epok (50 do 200 epok). Również domyślny zakres dla num_comp() jest bardzo wąski (od jednej do czterech składowych); możemy zwiększyć zakres do 40 składowych i ustawić wartość minimalną na zero:
W step_pca(), użycie zerowej liczby komponentów PCA oznazca pominięcie ekstrakcji cech. W ten sposób oryginalne predyktory mogą być bezpośrednio porównywane z wynikami, które zawierają komponenty PCA.
Funkcja tune_grid() jest podstawową funkcją do przeprowadzania przeszukiwania siatki. Jej funkcjonalność jest bardzo podobna do fit_resamples(), choć posiada dodatkowe argumenty związane z siatką:
grid - liczba całkowita lub ramka danych. Gdy użyta jest liczba całkowita, funkcja tworzy wypełniający przestrzeń wzór z siatką liczby kandydujących kombinacji parametrów. Jeśli istnieją konkretne kombinacje parametrów, parametr grid jest używany do przekazania ich do funkcji.param_info - opcjonalny argument służący do definiowania zakresów parametrów. Argument jest najbardziej przydatny, gdy grid jest liczbą całkowitą.W przeciwnym razie, interfejs tune_grid() jest taki sam jak fit_resamples(). Pierwszym argumentem jest albo specyfikacja modelu, albo przepływ pracy. Gdy podany jest model, drugim argumentem może być receptura lub wzór. Drugim wymaganym argumentem jest obiekt rsample (taki jak np. cell_folds). Poniższe wywołanie przekazuje również zestaw metryk, tak aby obszar pod krzywą ROC był mierzony podczas ponownego próbkowania.
roc_res <- metric_set(roc_auc)
set.seed(1305)
mlp_reg_tune <-
mlp_wflow %>%
tune_grid(
cell_folds,
grid = mlp_param %>% grid_regular(levels = 3),
metrics = roc_res
)
mlp_reg_tune# Tuning results
# 10-fold cross-validation
# A tibble: 10 × 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [1817/202]> Fold01 <tibble [81 × 8]> <tibble [0 × 3]>
2 <split [1817/202]> Fold02 <tibble [81 × 8]> <tibble [0 × 3]>
3 <split [1817/202]> Fold03 <tibble [81 × 8]> <tibble [0 × 3]>
4 <split [1817/202]> Fold04 <tibble [81 × 8]> <tibble [0 × 3]>
5 <split [1817/202]> Fold05 <tibble [81 × 8]> <tibble [0 × 3]>
6 <split [1817/202]> Fold06 <tibble [81 × 8]> <tibble [0 × 3]>
7 <split [1817/202]> Fold07 <tibble [81 × 8]> <tibble [0 × 3]>
8 <split [1817/202]> Fold08 <tibble [81 × 8]> <tibble [0 × 3]>
9 <split [1817/202]> Fold09 <tibble [81 × 8]> <tibble [0 × 3]>
10 <split [1818/201]> Fold10 <tibble [81 × 8]> <tibble [0 × 3]>autoplot(mlp_reg_tune) +
scale_color_viridis_d(direction = -1) +
theme(legend.position = "top")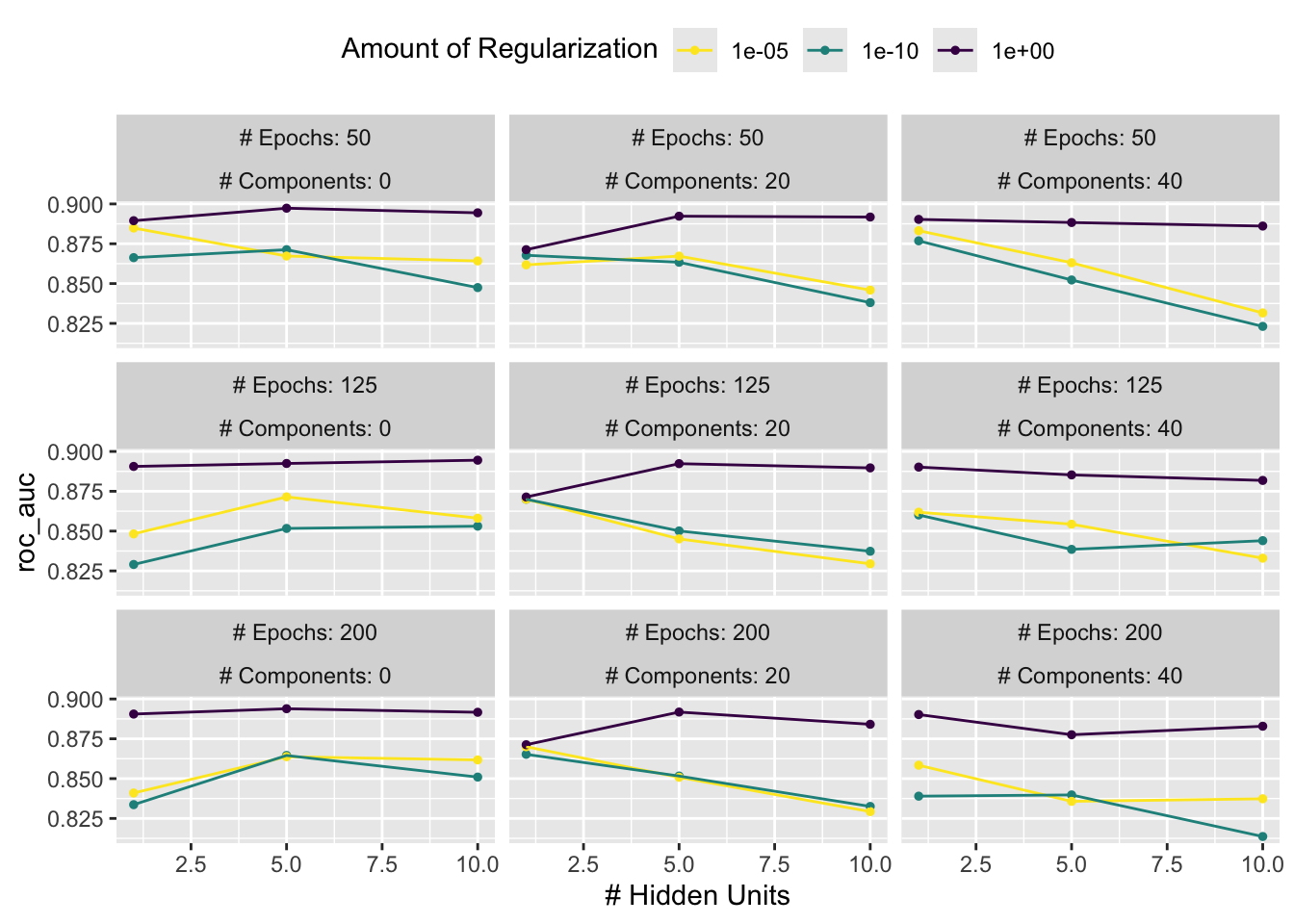
Dla tych danych, wielkość kary ma największy wpływ na obszar pod krzywą ROC. Liczba epok nie wydaje się mieć wyraźnego wpływu na wydajność. Zmiana liczby ukrytych jednostek wydaje się mieć największe znaczenie, gdy współczynnik regularyzacji (kara) jest niski (i szkodzi dopasowaniu). Istnieje kilka konfiguracji parametrów, które mają z grubsza podobną wydajność, jak widać przy użyciu funkcji show_best():
show_best(mlp_reg_tune) %>%
select(-.estimator)# A tibble: 5 × 9
hidden_units penalty epochs num_comp .metric mean n std_err .config
<int> <dbl> <int> <int> <chr> <dbl> <int> <dbl> <chr>
1 5 1 50 0 roc_auc 0.897 10 0.00857 Preprocessor…
2 10 1 125 0 roc_auc 0.895 10 0.00898 Preprocessor…
3 10 1 50 0 roc_auc 0.894 10 0.00960 Preprocessor…
4 5 1 200 0 roc_auc 0.894 10 0.00784 Preprocessor…
5 5 1 125 0 roc_auc 0.892 10 0.00822 Preprocessor…Bazując na tych wynikach, sensowne byłoby przeprowadzenie kolejnego przebiegu przeszukiwania siatki z większymi wartościami kary. Aby użyć konstrukcji wypełniającej przestrzeń, można podać argument grid jako liczbę całkowitą lub za pomocą jednej z funkcji grid_*() stworzyć ramkę danych. Aby ocenić ten sam zakres przy użyciu planu kwadratu łacińskiego z 20 zestawami parametrów:
set.seed(1306)
mlp_sfd_tune <-
mlp_wflow %>%
tune_grid(
cell_folds,
grid = 20,
# Pass in the parameter object to use the appropriate range:
param_info = mlp_param,
metrics = roc_res
)
mlp_sfd_tune# Tuning results
# 10-fold cross-validation
# A tibble: 10 × 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [1817/202]> Fold01 <tibble [20 × 8]> <tibble [0 × 3]>
2 <split [1817/202]> Fold02 <tibble [20 × 8]> <tibble [0 × 3]>
3 <split [1817/202]> Fold03 <tibble [20 × 8]> <tibble [0 × 3]>
4 <split [1817/202]> Fold04 <tibble [20 × 8]> <tibble [0 × 3]>
5 <split [1817/202]> Fold05 <tibble [20 × 8]> <tibble [0 × 3]>
6 <split [1817/202]> Fold06 <tibble [20 × 8]> <tibble [0 × 3]>
7 <split [1817/202]> Fold07 <tibble [20 × 8]> <tibble [0 × 3]>
8 <split [1817/202]> Fold08 <tibble [20 × 8]> <tibble [0 × 3]>
9 <split [1817/202]> Fold09 <tibble [20 × 8]> <tibble [0 × 3]>
10 <split [1818/201]> Fold10 <tibble [20 × 8]> <tibble [0 × 3]>Tym razem funkcja autoplot przedstawia wyniki efektów brzegowych poszczególnych parametrów. Należy zachować ostrożność podczas badania tego wykresu; ponieważ nie jest używana siatka regularna, wartości pozostałych parametrów dostrajania mogą wpływać na każdy panel.
autoplot(mlp_sfd_tune)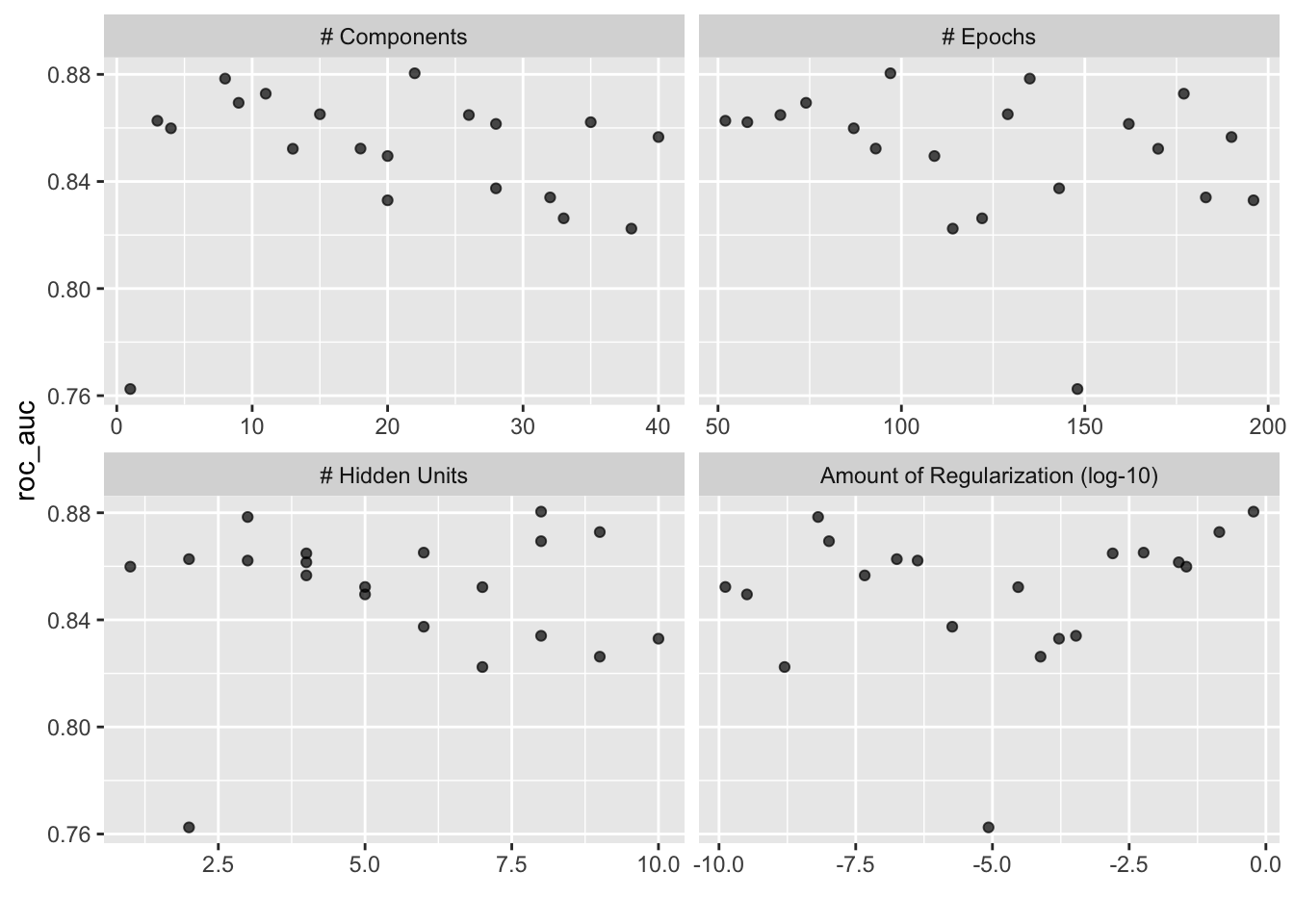
Parametr kary wydaje się skutkować lepszą wydajnością przy mniejszych wartościach. Jest to sprzeczne z wynikami z regularnej siatki. Ponieważ każdy punkt w każdym panelu jest współdzielony z pozostałymi trzema parametrami dostrajania, na trendy w jednym panelu mogą wpływać pozostałe. Przy użyciu siatki regularnej każdy punkt w każdym panelu jest uśredniony względem pozostałych parametrów. Z tego powodu efekt każdego parametru jest lepiej izolowany przy użyciu regularnych siatek.
show_best(mlp_sfd_tune) %>%
select(-.estimator)# A tibble: 5 × 9
hidden_units penalty epochs num_comp .metric mean n std_err .config
<int> <dbl> <int> <int> <chr> <dbl> <int> <dbl> <chr>
1 8 0.594 97 22 roc_auc 0.880 10 0.00998 Prepro…
2 3 0.00000000649 135 8 roc_auc 0.878 10 0.00957 Prepro…
3 9 0.141 177 11 roc_auc 0.873 10 0.0104 Prepro…
4 8 0.0000000103 74 9 roc_auc 0.869 10 0.00761 Prepro…
5 6 0.00581 129 15 roc_auc 0.865 10 0.00659 Prepro…Jak to sygnalizowaliśmy wcześniej, dobrym pomysłem jest ocena modeli za pomocą wielu metryk, tak aby uwzględnione zostały różne aspekty dopasowania modelu. Ponadto, często sensowne jest wybranie nieco suboptymalnej kombinacji parametrów, która jest związana z prostszym modelem. W przypadku tego modelu prostota odpowiada większym wartościom kar i/lub mniejszej liczbie neuronów w warstwie ukrytej.
Jeśli jeden z zestawów możliwych parametrów modelu znalezionych poprzez show_best() byłby atrakcyjną opcją końcową dla tych danych, moglibyśmy chcieć ocenić jak dobrze radzi sobie na zestawie testowym. Jednakże, wyniki funkcji tune_grid() dostarczają jedynie podłoża do wyboru odpowiednich parametrów. Funkcja ta nie dopasowuje modelu końcowego. Aby dopasować model końcowy, należy określić ostateczny zestaw wartości parametrów. Istnieją dwie metody, aby to zrobić:
select_*().
Na przykład select_best() wybierze parametry o numerycznie najlepszych wynikach dopasowania. Wróćmy do naszych zwykłych wyników siatki i zobaczmy, który z nich jest najlepszy:
select_best(mlp_reg_tune, metric = "roc_auc")# A tibble: 1 × 5
hidden_units penalty epochs num_comp .config
<int> <dbl> <int> <int> <chr>
1 5 1 50 0 Preprocessor1_Model08Patrząc na Rys. 10.3, widzimy, że model z pojedynczym neuronem w warstwie ukrytej trenowany przez 125 epok na oryginalnych predyktorach z dużą wartością kary ma wydajność konkurencyjną do modelu otrzymanego z zagęszczeniem wartości parametrów, a jest prostszy. Jest to w zasadzie regularyzowana regresja logistyczna! Aby ręcznie określić te parametry, możemy utworzyć tibble z tymi wartościami, a następnie użyć funkcji finalizacji, aby spleść wartości z powrotem do przepływu pracy:
logistic_param <-
tibble(
num_comp = 0,
epochs = 125,
hidden_units = 1,
penalty = 1
)
final_mlp_wflow <-
mlp_wflow %>%
finalize_workflow(logistic_param)
final_mlp_wflow══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: mlp()
── Preprocessor ────────────────────────────────────────────────────────────────
4 Recipe Steps
• step_YeoJohnson()
• step_normalize()
• step_pca()
• step_normalize()
── Model ───────────────────────────────────────────────────────────────────────
Single Layer Neural Network Model Specification (classification)
Main Arguments:
hidden_units = 1
penalty = 1
epochs = 125
Engine-Specific Arguments:
trace = 0
Computational engine: nnet Żadne inne wartości funkcji tune() nie są uwzględniane w sfinalizowanym procesie pracy. Teraz model może być dopasowany do całego zestawu treningowego:
final_mlp_fit <-
final_mlp_wflow %>%
fit(cells)Obiekt ten może być teraz użyty do przyszłych predykcji na nowych danych.
Jeśli nie użyłeś przepływu pracy, finalizacja modelu i/lub receptury odbywa się za pomocą finalize_model() i finalize_recipe().
Aby automatycznie stworzyć specyfikację modelu do tuningu, wystarczy wykorzystać odpowiednią funkcję pakietu usemodels.
set.seed(1001)
ames <- ames |>mutate(Sale_Price = log10(Sale_Price))
ames_split <- initial_split(ames, prop = 0.80, strata = Sale_Price)
ames_train <- training(ames_split)
ames_test <- testing(ames_split)
library(usemodels)
use_xgboost(Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type +
Latitude + Longitude,
data = ames_train,
# Add comments explaining some of the code:
verbose = TRUE)xgboost_recipe <-
recipe(formula = Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type +
Latitude + Longitude, data = ames_train) %>%
step_zv(all_predictors())
xgboost_spec <-
boost_tree(trees = tune(), min_n = tune(), tree_depth = tune(), learn_rate = tune(),
loss_reduction = tune(), sample_size = tune()) %>%
set_mode("classification") %>%
set_engine("xgboost")
xgboost_workflow <-
workflow() %>%
add_recipe(xgboost_recipe) %>%
add_model(xgboost_spec)
set.seed(76045)
xgboost_tune <-
tune_grid(xgboost_workflow, resamples = stop("add your rsample object"), grid = stop("add number of candidate points"))
