
Kod
library(tidymodels)
imbal_data <-
readr::read_csv("data/imbal_data.csv") |>
mutate(Class = factor(Class))
dim(imbal_data)[1] 1200 16Kod
table(imbal_data$Class)
Class1 Class2
60 1140 Próbkowanie (ang. subsampling) zbioru treningowego, zarówno zaniżanie (ang. undersampling), jak i zawyżanie (ang. oversampling) próbkowania odpowiedniej klasy lub klas, może być pomocne w radzeniu sobie z danymi klasyfikacyjnymi, w których jedna lub więcej klas występuje bardzo rzadko. W takiej sytuacji (bez kompensacji), większość modeli będzie nadmiernie dopasowana do klasy większościowej i wytworzy bardzo dobre statystyki dopasowania dla klasy zawierającej często występujące klasy, podczas gdy klasy mniejszościowe będą miały słabe wyniki.
Ten rozdział opisuje podpróbkowanie stosowane w kontekście radzenia sobie z nierównowagą klas.
Rozważmy problem dwuklasowy, w którym pierwsza klasa ma bardzo niską częstość występowania. Dane zostały zasymulowane i można je zaimportować do R za pomocą poniższego kodu:
library(tidymodels)
imbal_data <-
readr::read_csv("data/imbal_data.csv") |>
mutate(Class = factor(Class))
dim(imbal_data)[1] 1200 16table(imbal_data$Class)
Class1 Class2
60 1140 Jeśli “klasa1” jest zdarzeniem będącym przedmiotem zainteresowania, jest bardzo prawdopodobne, że model klasyfikacyjny byłby w stanie osiągnąć bardzo dobrą specyficzność, ponieważ prawie wszystkie dane należą do drugiej klasy. Czułość jednak będzie prawdopodobnie słaba, ponieważ modele będą optymalizować dokładność (lub inne funkcje straty) poprzez przewidywanie, że wszystko jest klasą większościową.
Jednym z rezultatów braku równowagi klasowej, gdy istnieją dwie klasy, jest to, że domyślne odcięcie prawdopodobieństwa na poziomie 50% jest nieodpowiednie; inne odcięcie, które jest bardziej ekstremalne, może być w stanie osiągnąć lepszą wydajność.
Jednym ze sposobów na złagodzenie tego problemu jest podpróbkowanie danych. Istnieje wiele sposobów, aby to zrobić, ale najprostszym jest próbkowanie w dół (undersample) danych klasy większościowej, aż wystąpi ona z taką samą częstotliwością jak klasa mniejszościowa. Choć może się to wydawać sprzeczne z intuicją, wyrzucenie dużego procentu danych może być skuteczne w tworzeniu użytecznego modelu, który potrafi rozpoznać zarówno klasy większościowe, jak i mniejszościowe. W niektórych przypadkach oznacza to nawet, że ogólna wydajność modelu jest lepsza (np. poprawiony obszar pod krzywą ROC). Podpróbkowanie prawie zawsze daje modele, które są lepiej skalibrowane, co oznacza, że rozkłady prawdopodobieństwa klas są lepiej zachowane. W rezultacie, domyślne odcięcie 50% daje znacznie większe prawdopodobieństwo uzyskania lepszych wartości czułości i specyficzności niż w innym przypadku.
Istnieją również techniki oversampling, które sprowadzają klasy mniejszościowe do liczebności takiej samej jak klasa większościowa (lub jej części) poprzez odpowiednie próbkowanie istniejących obserwacji lub też (jak to jest w przypadku metody SMOTE) tworzy się syntetyczne obserwacje podobne do już istniejących w klasie mniejszościowej. W pakiecie themis można znaleźć różne techniki próbkowania w górę: step_upsample(), step_smote(), step_bsmote(method = 1), step_bsmote(method = 2), step_adasyn(), step_rose() oraz kilka technik próbkowania w dół: step_downsample(), step_nearmiss() i step_tomek().
Zbadajmy działanie próbkowania używając themis::step_rose() w przepisie dla symulowanych danych. Wykorzystuje ona metodę ROSE (ang. Random Over Sampling Examples) z Menardi i Torelli (2012). Jest to przykład strategii oversampling.
W zakresie przepływu pracy:
skip w step_downsample() i innych krokach receptury próbkowania ma domyślnie wartość TRUE.Oto prosta recepta implementująca oversampling:
Jako modelu użyjmy modelu kwadratowej analizy dyskryminacyjnej (QDA). Z poziomu pakietu discrim, model ten można określić za pomocą:
library(discrim)
qda_mod <-
discrim_regularized(frac_common_cov = 0, frac_identity = 0) %>%
set_engine("klaR")Aby utrzymać te obiekty związane ze sobą, połączymy je w ramach przepływu pracy:
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: discrim_regularized()
── Preprocessor ────────────────────────────────────────────────────────────────
1 Recipe Step
• step_rose()
── Model ───────────────────────────────────────────────────────────────────────
Regularized Discriminant Model Specification (classification)
Main Arguments:
frac_common_cov = 0
frac_identity = 0
Computational engine: klaR Do oceny jakości dopasowania modelu zastosujemy 10-krotny sprawdzian krzyżowy z powtórzeniami:
set.seed(5732)
cv_folds <- vfold_cv(imbal_data, strata = "Class", repeats = 5)Aby zmierzyć wydajność modelu, użyjmy dwóch metryk:
Jeśli model jest źle skalibrowany, wartość krzywej ROC może nie wykazywać zmniejszonej wydajności. Jednak wskaźnik J byłby niższy dla modeli z patologicznymi rozkładami prawdopodobieństw klas. Do obliczenia tych metryk zostanie użyty pakiet yardstick.
cls_metrics <- metric_set(roc_auc, j_index)set.seed(2180)
qda_rose_res <- fit_resamples(
qda_rose_wflw,
resamples = cv_folds,
metrics = cls_metrics
)
collect_metrics(qda_rose_res)# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 j_index binary 0.768 50 0.0214 Preprocessor1_Model1
2 roc_auc binary 0.951 50 0.00509 Preprocessor1_Model1Jak wyglądają wyniki bez użycia ROSE? Możemy stworzyć kolejny przepływ pracy i dopasować model QDA dla tych samych foldów:
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 j_index binary 0.250 50 0.0288 Preprocessor1_Model1
2 roc_auc binary 0.953 50 0.00479 Preprocessor1_Model1Wygląda na to, że próbkowanie metodą ROSE bardzo pomogło, zwłaszcza w przypadku indeksu J. Metody próbkowania nierównowagi klasowej mają tendencję do znacznej poprawy metryk opartych na twardych przewidywaniach klasowych (tj. przewidywaniach kategorycznych), ponieważ domyślne odcięcie ma tendencję do lepszej równowagi pomiędzy czułością i specyficznością.
Wykreślmy metryki dla każdej próbki, aby zobaczyć, jak zmieniły się poszczególne wyniki.
no_sampling <-
qda_only_res %>%
collect_metrics(summarize = FALSE) %>%
dplyr::select(-.estimator) %>%
mutate(sampling = "no_sampling")
with_sampling <-
qda_rose_res %>%
collect_metrics(summarize = FALSE) %>%
dplyr::select(-.estimator) %>%
mutate(sampling = "rose")
bind_rows(no_sampling, with_sampling) %>%
mutate(label = paste(id2, id)) %>%
ggplot(aes(x = sampling, y = .estimate, group = label)) +
geom_line(alpha = .4) +
facet_wrap(~ .metric, scales = "free_y")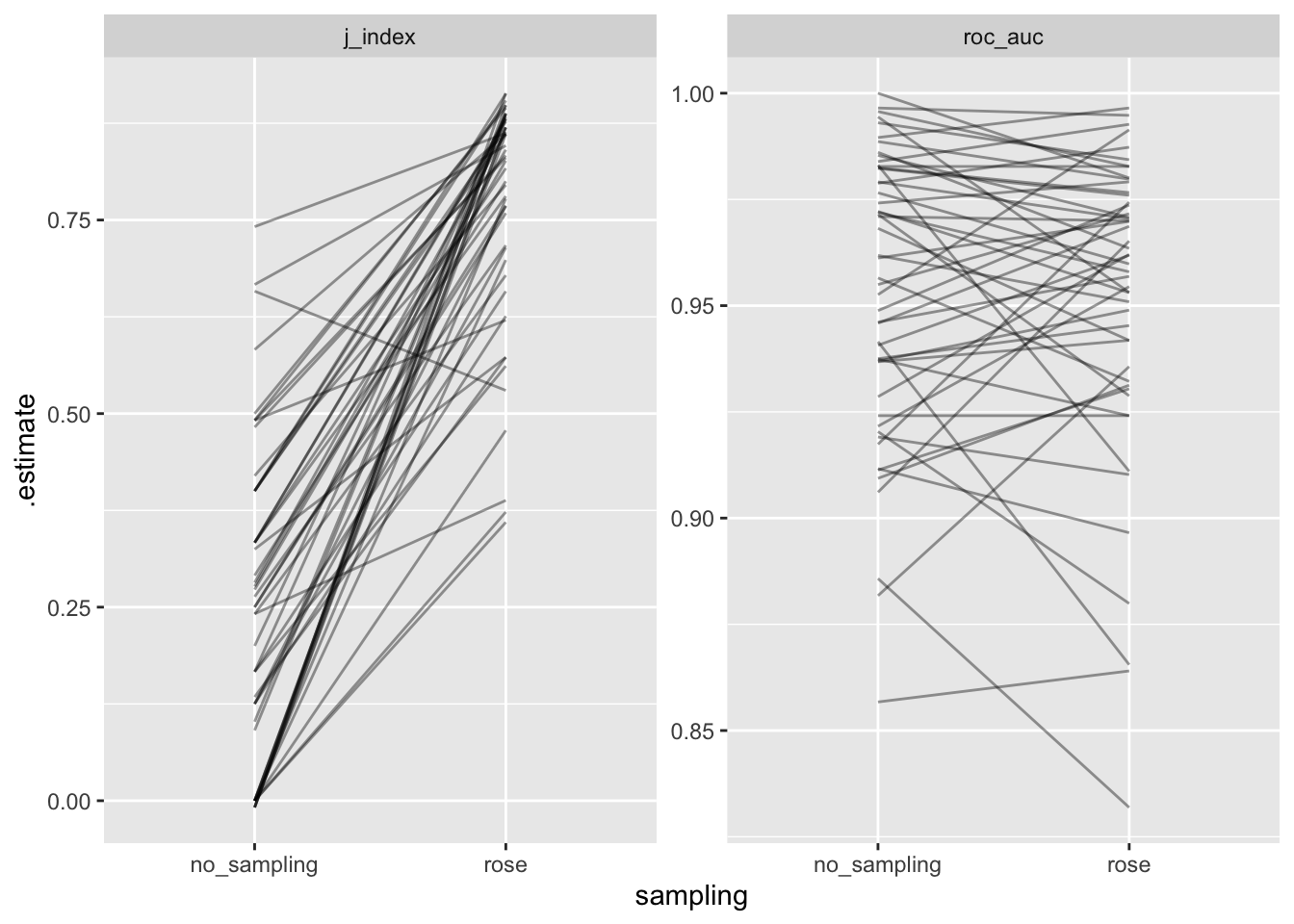
Jak widać na podstawie Rys. 15.1 szczególnie w kontekście miar, które wykorzystują twardy podział (czyli zdefiniowany przez parametr odcięcia) nastąpiła znaczna poprawa.
Pierwszą komplikacją związaną z próbkowaniem jest połączenie jej z przetwarzaniem wstępnym. Czy próbkowanie powinno mieć miejsce przed czy po przetwarzaniu wstępnym? Na przykład, jeśli zmniejszamy próbkę danych i używamy PCA do ekstrakcji cech, czy ładunki powinny być oszacowane z całego zbioru treningowego? Estymacja ta byłaby potencjalnie lepsza, ponieważ wykorzystywany byłby cały zbiór treningowy, ale może się zdarzyć, że podpróbka uchwyci niewielką część przestrzeni PCA. Nie ma żadnej oczywistej odpowiedzi ale zaleca się stosować próbkowanie przed procedurą wstępnego przetwarzania.
Inne zagrożenia to:
grid_search() do określenia siatki wyszukiwania, może się zdarzyć, że dane, które są używane do określenia siatki po próbkowaniu, nie wypełniają pełnych zakresów zmienności hiperparametrów. W większości przypadków nie ma to znaczenia, ale czasami może doprowadzić do uzyskania nieoptymalnej siatki.