Kod
# w wersji klasycznej należałoby je budować następująco
mod_stat <- lm(formula, data = ...)
mod_glmnet <- glmnet(x = matrix, y = vector, family = "gaussian", ...)
mod_stan <- stan_glm(formula, data, family = "gaussian", ...)tidymodels
Filozofia jaką przyjęli twórcy pakietu tidymodels, wraz z wszystkimi pakietami towarzyszącymi, miała na celu ujednolicenie procesu modelowania, bez względu na to jaki aktualnie model jest uczony. Jest to odpowiedź na powszechnie pojawiające się problemy z modelowaniem w R, gdzie praktycznie każdy model ma swoją charakterystyczną formę wywołania, predykcji czy podsumowania. Co więcej, zdarza się nierzadko, że ten sam rodzaj modelu, np. regresja liniowa, może być budowany z wykorzystaniem różnych “silników”: stats, glm, glmnet , rstanarm. W każdym z nich model będzie budowany nieco inaczej. Dodatkowo niektóre z wymienionych pakietów wymagają podczas uczenia ustalenia pewnych parametrów, jak rodzina rozkładów, parametr regularyzacji itp., co więcej w różnych pakietach mogą mieć inne nazwy.

Z pewnością powoduje to dodatkową komplikację podczas budowy modelu nie mającą bezpośredniego związku z modelowaniem. Podobnych przykładów różnic pomiędzy modelami można mnożyć. Nie tylko parametry modelu, czy funkcje wywoławcze się różnią, czasami format w jakim dane muszą być aplikowane do modelu - jako formuła czy jako para \((X,y)\) - czy nawet sposób predykcji mogą się znacząco różnić pomiędzy modelami. To wszystko sprawiło, że autorzy pakiety tidymodels dokonali pewnego rodzaju standaryzacji modeli. Sprawiło, to że badacz już nie musi się zastanawiać nad różnym nazewnictwem tego samego parametru w różnych modelach tego samego typu, czy jak przeprowadzić predykcję aby w wyniku otrzymać prawdopodobieństwa poszczególnych klas. W tym rozdziale postaramy się przybliżyć ten sposób unifikacji w budowie modelu uczenia maszynowego.
Oddzielny pakiet przeznaczony do budowy modeli zawarty w ekosystemie tidymodels o nazwie parsnip pozwala w uniwersalny sposób budować i dopasowywać modele. Wracając do przykładu modelu liniowego postaramy się pokazać wszystkie zalety tego podejścia. Choć regresje liniową możemy zbudować z wykorzystaniem 11 różnych pakietów, to my się ograniczymy tylko do stats, glmnet i rstanarm.
# w wersji klasycznej należałoby je budować następująco
mod_stat <- lm(formula, data = ...)
mod_glmnet <- glmnet(x = matrix, y = vector, family = "gaussian", ...)
mod_stan <- stan_glm(formula, data, family = "gaussian", ...)Już na poziomie definiowana modeli widzimy różnice w definicjach, np. glmnet potrzebuje danych w formacie \((X,y)\). W przypadku tidymodels podejście do określania modelu ma być bardziej zunifikowane:
stan1 lub glmnet. Są to modele same w sobie, a parsnip zapewnia spójne interfejsy, używając ich jako silników do modelowania.1 jest to bibliotek języka C++
2 klasyfikacja czy regresja
library(tidymodels)
# to samo z wykorzystaniem parsnip
linear_reg() %>% set_engine("lm")Linear Regression Model Specification (regression)
Computational engine: lm linear_reg() %>% set_engine("glmnet")Linear Regression Model Specification (regression)
Computational engine: glmnet linear_reg() %>% set_engine("stan")Linear Regression Model Specification (regression)
Computational engine: stan Po ustaleniu modeli można je podać uczeniu, za pomocą funkcji fit w przypadku gdy określaliśmy zależność formułą lub fit_xy gdy zmienne niezależne i zależna były określone oddzielnie. Drugi przypadek ma miejsce gdy w procedurze przygotowania danych mamy je w postaci \((X,y)\). Nie mniej jednak pakiet parsnip pozwala na użycie fit nawet gdy oryginalna funkcja wymagała podania zmiennych niezależnych i zależnej. Ponadto funkcja translate pozwala na przetłumaczenie modelu parsnip na język danego pakietu.

linear_reg() %>% set_engine("lm") |> translate()Linear Regression Model Specification (regression)
Computational engine: lm
Model fit template:
stats::lm(formula = missing_arg(), data = missing_arg(), weights = missing_arg())linear_reg(penalty = 1) %>% set_engine("glmnet") |> translate()Linear Regression Model Specification (regression)
Main Arguments:
penalty = 1
Computational engine: glmnet
Model fit template:
glmnet::glmnet(x = missing_arg(), y = missing_arg(), weights = missing_arg(),
family = "gaussian")linear_reg() %>% set_engine("stan") |> translate()Linear Regression Model Specification (regression)
Computational engine: stan
Model fit template:
rstanarm::stan_glm(formula = missing_arg(), data = missing_arg(),
weights = missing_arg(), family = stats::gaussian, refresh = 0)Wykorzystując dane ames dopasujemy cenę (Sale_Price) na podstawie długości i szerokości geograficznej domu.
set.seed(44)
ames <- ames %>% mutate(Sale_Price = log10(Sale_Price))
ames_split <- initial_split(ames, prop = 0.80, strata = Sale_Price)
ames_train <- training(ames_split)
ames_test <- testing(ames_split)
lm_model <-
linear_reg() %>%
set_engine("lm")
lm_form_fit <-
lm_model %>%
fit(Sale_Price ~ Longitude + Latitude, data = ames_train)
lm_xy_fit <-
lm_model %>%
fit_xy(
x = ames_train %>% select(Longitude, Latitude),
y = ames_train %>% pull(Sale_Price)
)
lm_form_fitparsnip model object
Call:
stats::lm(formula = Sale_Price ~ Longitude + Latitude, data = data)
Coefficients:
(Intercept) Longitude Latitude
-321.755 -2.091 3.120 lm_xy_fitparsnip model object
Call:
stats::lm(formula = ..y ~ ., data = data)
Coefficients:
(Intercept) Longitude Latitude
-321.755 -2.091 3.120 Kolejną zaletą pakietu parsnip jest unifikacja nazw parametrów modeli. Dla przykładu gdybyśmy chcieli dopasować trzy różne modele lasów losowych, korzystając z pakietów ranger, randomForest i sparklyr, musielibyśmy określać parametry modelu używając za każdym razem innych nazw.

W przypadku budowy w parsnip nazwy parametrów zostały zunifikowane:
mtry - liczba wybranych predyktorów;trees - liczba drzew;min_n - minimalna liczba obserwacji aby dokonać podziału węzła.Unifikacja po pierwsze pozwala lepiej zapamiętać nazwy parametrów, a po drugie ich nazwy są zrozumiałe dla czytelnika, który nie koniecznie musi się znać na różnicach pomiędzy pakietami.
Dla wspomnianego przykładu lasów losowych, model można zdefiniować następująco.
rand_forest(trees = 1000, min_n = 5) %>%
set_engine("ranger") %>%
set_mode("regression") %>%
translate() # translate nie musi być używane, w tym przypadku byłoRandom Forest Model Specification (regression)
Main Arguments:
trees = 1000
min_n = 5
Computational engine: ranger
Model fit template:
ranger::ranger(x = missing_arg(), y = missing_arg(), weights = missing_arg(),
num.trees = 1000, min.node.size = min_rows(~5, x), num.threads = 1,
verbose = FALSE, seed = sample.int(10^5, 1))# użyte aby pokazać jak parsnip zamienił z unikalnej funkcji
# rand_forest na model rangerGłówne parametry modelu są przekazywane przez główną funkcję (w przykładzie była to rand_forest), ale pozostałe parametry, charakterystyczne dla danego silnika można przekazać przez argumenty silnika.
rand_forest(trees = 1000, min_n = 5) %>%
set_engine("ranger", verbose = TRUE) %>%
set_mode("regression") # parametr verbose = T przekazany został oddzielnieRandom Forest Model Specification (regression)
Main Arguments:
trees = 1000
min_n = 5
Engine-Specific Arguments:
verbose = TRUE
Computational engine: ranger Po utworzeniu i dopasowaniu modelu możemy wykorzystać wyniki na wiele sposobów; możemy chcieć narysować, podsumować lub w inny sposób zbadać model wyjściowy. W obiekcie modelu parsnip przechowywanych jest kilka wielkości, w tym dopasowany model. Można go znaleźć w elemencie o nazwie fit, który może być zwrócony za pomocą funkcji extract_fit_engine.
lm_form_fit %>% extract_fit_engine()
Call:
stats::lm(formula = Sale_Price ~ Longitude + Latitude, data = data)
Coefficients:
(Intercept) Longitude Latitude
-321.755 -2.091 3.120 lm_form_fit %>% extract_fit_engine() %>% vcov() (Intercept) Longitude Latitude
(Intercept) 214.194437 1.611665120 -1.505256159
Longitude 1.611665 0.016726120 -0.001079561
Latitude -1.505256 -0.001079561 0.033404800Nigdy nie przekazuj elementu fit modelu parsnip do funkcji predict(lm_form_fit), tzn. nie używaj predict(lm_form_fit$fit). Jeśli dane zostały wstępnie przetworzone w jakikolwiek sposób, zostaną wygenerowane nieprawidłowe predykcje (czasami bez błędów). Funkcja predykcji modelu bazowego nie ma pojęcia czy jakiekolwiek przekształcenia zostały dokonane na danych przed uruchomieniem modelu.
Kolejną zaletę unifikacji parsnip możemy dostrzec przeglądając podsumowanie modeli. Nie zawsze wyniki modelu są przedstawiane w jednakowy sposób. Czasami różnice są niewielkie, gdy w jednym podsumowaniu zobaczymy p-value a w innym Pr(>|t|) ale czasem mogą być większe. I o ile nie da się zunifikować wszystkich podsumować modeli, ponieważ zawierają różne elementy, to w pakiecie parsnip korzysta się z funkcji tidy pakietu broom do podsumowania modelu.

tidy(lm_form_fit)# A tibble: 3 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -322. 14.6 -22.0 1.57e-97
2 Longitude -2.09 0.129 -16.2 7.71e-56
3 Latitude 3.12 0.183 17.1 1.17e-61Oczywiście nie wszystkie modele da się w ten sposób podsumować.

Predykcja z modelu jest kolejnym elementem, w którym unifikacja daje o sobie znać:
tibble;tibble wynikowej wierszy jest zawsze tyle samo co w zbiorze, na którym predykcja była przeprowadzona;ames_test_small <- ames_test %>% slice(1:5)
predict(lm_form_fit, new_data = ames_test_small)# A tibble: 5 × 1
.pred
<dbl>
1 5.23
2 5.29
3 5.25
4 5.25
5 5.23To sprawia, że łatwiej można korzystać z wyników predykcji, ponieważ zawsze jesteśmy pewni jaki układ ramki danych predykcji się pojawi.
# A tibble: 5 × 4
Sale_Price .pred .pred_lower .pred_upper
<dbl> <dbl> <dbl> <dbl>
1 5.24 5.23 4.91 5.54
2 5.33 5.29 4.97 5.60
3 5.06 5.25 4.93 5.56
4 5.26 5.25 4.93 5.56
5 5.08 5.23 4.92 5.55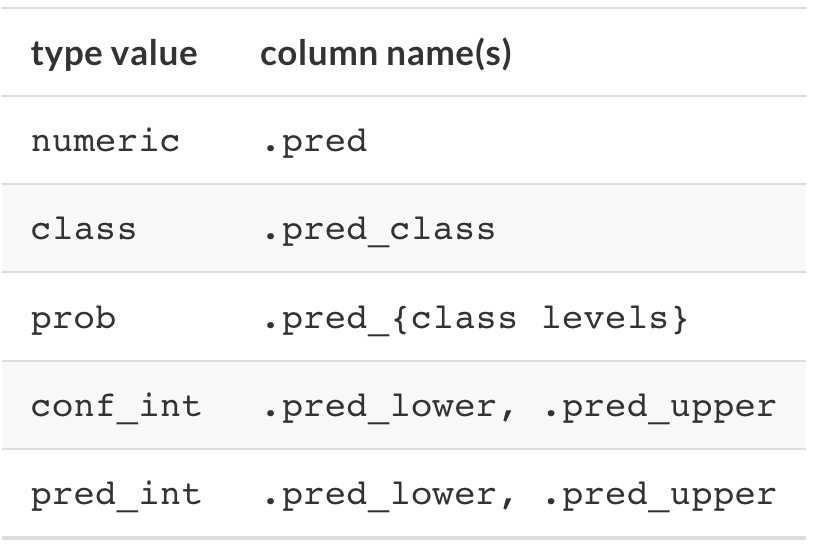
tree_model <-
decision_tree(min_n = 2) %>%
set_engine("rpart") %>%
set_mode("regression")
tree_fit <-
tree_model %>%
fit(Sale_Price ~ Longitude + Latitude, data = ames_train)
ames_test_small %>%
select(Sale_Price) %>%
bind_cols(predict(tree_fit, ames_test_small))# A tibble: 5 × 2
Sale_Price .pred
<dbl> <dbl>
1 5.24 5.16
2 5.33 5.31
3 5.06 5.16
4 5.26 5.16
5 5.08 5.16Sam pakiet parsnip zawiera interfejsy do wielu modeli. Jednakże, dla ułatwienia instalacji i konserwacji pakietu, istnieją inne pakiety tidymodels, które posiadają definicje modeli nie zawartych w parsnip. Np. pakiet discrim posiada definicje modeli klasyfikacyjnych zwanych metodami analizy dyskryminacyjnej (takich jak liniowa lub kwadratowa analiza dyskryminacyjna). Lista wszystkich modeli, które mogą być używane z parsnip znajduje się na stronie https://www.tidymodels.org/find/.
Przydatnym narzędziem w budowaniu modeli z wykorzystaniem pakietu tidymodels jest dodatek programu Rstudio3.
3 addin instalowany razem z pakietem parsnip
Do tej pory o modelowaniu myśleliśmy w uproszczony sposób, ponieważ zakładaliśmy pewną strukturę modelu, dobieraliśmy silnik i uczyliśmy model na zbiorze treningowym. W “prawdziwych” zadaniach z zakresu uczenia maszynowego, proces ten jest znacznie bardziej złożony. W fazie, którą się powszechnie nazywa przygotowaniem danych (ang. pre-processing), dokonuje się transformacji, agregacji i imputacji danych w celu wykształcenia predyktorów o większej mocy predykcyjnej. W tej fazie dochodzi również do inżynierii cech4 (ang. feature engineering), która ma na celu odfiltrowanie nieużytecznych cech zbioru danych.
4 chodzi o wszelkiego rodzaju modyfikacje i selekcje cech
5 szerzej o tej części będziemy mówić w dalszej części tej książki
Kolejna faza budowania poprawnego modelu to jego optymalizacja (ang. tuning). Często bowiem budowane modele zawierają hiperparametry, których nie oszacujemy podczas uczenia modelu, dlatego należy je skalibrować na podstawie innych metod5.
Również w końcowej fazie uczenia modelu tzw. post-processing-u dokonuje się jego modyfikacji, np. dobierając optymalny poziom odcięcia dla regresji logistycznej.
To wszystko powoduje, że procedura modelowania składa się z kilku elementów. Do ich połączenia w ekosystemie tidymodels używa się przepływów (ang. workflow). Pakiet workflow zawiera szereg funkcji pozwalających skutecznie obsługiwać potoki workflow6.
6 tak nazywa się funkcja do tworzenia potoku
Pomimo złożoności procedury modelowania można się dalej zastawiać nad koniecznością stosowania przepływów, skoro można te czynności wykonywać oddzielnie. Postaramy się na przykładzie pokazać zasadności stosowania przepływów.
Weźmy, dajmy na to, że predyktory w zbiorze danych są wysoce skorelowane. Wiem, że zjawisko współliniowości może przeszkodzić w modelowaniu zjawiska, np. za pomocą modelu liniowego, ponieważ znacznie rosną wówczas błędy standardowe estymacji. Jednym ze sposobów radzenia sobie z tym problemem jest zrzutowanie danych na nową przestrzeń mniej wymiarową za pomocą PCA. I gdyby PCA była metodą deterministyczną, czyli nie towarzyszyła jej żadna niepewność7, to tę procedurę preprocessingu użyli byśmy do zbioru uczącego w procesie uczenia modelu, a w predykcji do zbioru testowego, bez konsekwencji w postaci niedokładnego oszacowania wartości wynikowych. Jednak PCA wiąże się z niepewnością, dlatego procedura ta powinna być włączona do przepływu, czyli być immanentną częścią procesu modelowania.
7 jak np. logarytmowanie zmiennej
Choć workflow pozwalają na łączenie preprocessingu, tuningu i postprocessingu, to w następnym przykładzie pokażemy zastosowanie workflow do prostego ucznia modelu bez tych elementów.
# określenie modelu
lm_model <-
linear_reg() |>
set_engine("lm")
# zebranie elementów w workflow
lm_wflow <-
workflow() |>
add_model(lm_model) |>
add_formula(Sale_Price ~ Longitude + Latitude)
# workflow
lm_wflow══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Formula
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Sale_Price ~ Longitude + Latitude
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm # uczenie modelu
lm_fit <- fit(lm_wflow, ames_train)
lm_fit══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Formula
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Sale_Price ~ Longitude + Latitude
── Model ───────────────────────────────────────────────────────────────────────
Call:
stats::lm(formula = ..y ~ ., data = data)
Coefficients:
(Intercept) Longitude Latitude
-321.755 -2.091 3.120 # predykcja
predict(lm_fit, ames_test %>% slice(1:3))# A tibble: 3 × 1
.pred
<dbl>
1 5.23
2 5.29
3 5.25Pomimo tego, że model został zebrany w jedną całość (przepływ), to cały czas możemy modyfikować jego elementy. Przykładowo ujmijmy jeden z predyktorów.
lm_fit %>% update_formula(Sale_Price ~ Longitude)══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Formula
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Sale_Price ~ Longitude
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm Jeszcze inny przykład modyfikacji przepływu pokazuje przeformatowanie zależności opisywanej modelem.
lm_wflow <-
lm_wflow %>%
remove_formula() %>%
add_variables(outcome = Sale_Price, predictors = c(Longitude, Latitude))
lm_wflow══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Variables
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Outcomes: Sale_Price
Predictors: c(Longitude, Latitude)
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm fit(lm_wflow, ames_train)══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Variables
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Outcomes: Sale_Price
Predictors: c(Longitude, Latitude)
── Model ───────────────────────────────────────────────────────────────────────
Call:
stats::lm(formula = ..y ~ ., data = data)
Coefficients:
(Intercept) Longitude Latitude
-321.755 -2.091 3.120 Genialną właściwością przepływów jest to, że gdy uczymy model wymagający zamiany zmiennych typu faktor na indykatory (ang. dummy variables), to przepływ to zrobi za nas. Przykładowo gdy uczymy model boost_tree z silnikiem xgboost to przepływ zamieni faktory na indykatory, a gdy uczymy z silnikiem C5.0 to już nie, ponieważ ten pakiet tego nie wymaga. Są jednak sytuacje, w których niewielka interwencja w workflow jest potrzebna. Np. jeśli uczymy model z efektami losowymi.
Linear mixed model fit by REML ['lmerMod']
Formula: distance ~ Sex + (age | Subject)
Data: Orthodont
REML criterion at convergence: 471.1635
Random effects:
Groups Name Std.Dev. Corr
Subject (Intercept) 7.3912
age 0.6943 -0.97
Residual 1.3100
Number of obs: 108, groups: Subject, 27
Fixed Effects:
(Intercept) SexFemale
24.517 -2.145 # tej formuły nie możemy bezpośrednio przekazać do workflow
# za pomocą add_formula
library(multilevelmod)
multilevel_spec <- linear_reg() %>% set_engine("lmer")
multilevel_workflow <-
workflow() %>%
# Pass the data along as-is:
add_variables(outcome = distance, predictors = c(Sex, age, Subject)) %>%
add_model(multilevel_spec,
# This formula is given to the model
formula = distance ~ Sex + (age | Subject))
multilevel_fit <- fit(multilevel_workflow, data = Orthodont)
multilevel_fit══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Variables
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Outcomes: distance
Predictors: c(Sex, age, Subject)
── Model ───────────────────────────────────────────────────────────────────────
Linear mixed model fit by REML ['lmerMod']
Formula: distance ~ Sex + (age | Subject)
Data: data
REML criterion at convergence: 471.1635
Random effects:
Groups Name Std.Dev. Corr
Subject (Intercept) 7.3912
age 0.6943 -0.97
Residual 1.3100
Number of obs: 108, groups: Subject, 27
Fixed Effects:
(Intercept) SexFemale
24.517 -2.145 Kolejną zaletą pakietu workflowset jest możliwość jednoczesnego uczenia wielu wariantów modeli.
# określamy potencjalne formuły modeli
location <- list(
longitude = Sale_Price ~ Longitude,
latitude = Sale_Price ~ Latitude,
coords = Sale_Price ~ Longitude + Latitude,
neighborhood = Sale_Price ~ Neighborhood
)
library(workflowsets)
# zestaw przepływów do uczenia
location_models <- workflow_set(preproc = location, models = list(lm = lm_model))
location_models# A workflow set/tibble: 4 × 4
wflow_id info option result
<chr> <list> <list> <list>
1 longitude_lm <tibble [1 × 4]> <opts[0]> <list [0]>
2 latitude_lm <tibble [1 × 4]> <opts[0]> <list [0]>
3 coords_lm <tibble [1 × 4]> <opts[0]> <list [0]>
4 neighborhood_lm <tibble [1 × 4]> <opts[0]> <list [0]># pierwszy przepływ
location_models$info[[1]]# A tibble: 1 × 4
workflow preproc model comment
<list> <chr> <chr> <chr>
1 <workflow> formula linear_reg "" # wyciągamy informacje o przepływie trzecim
extract_workflow(location_models, id = "coords_lm")══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Formula
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Sale_Price ~ Longitude + Latitude
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm # A workflow set/tibble: 4 × 5
wflow_id info option result fit
<chr> <list> <list> <list> <list>
1 longitude_lm <tibble [1 × 4]> <opts[0]> <list [0]> <workflow>
2 latitude_lm <tibble [1 × 4]> <opts[0]> <list [0]> <workflow>
3 coords_lm <tibble [1 × 4]> <opts[0]> <list [0]> <workflow>
4 neighborhood_lm <tibble [1 × 4]> <opts[0]> <list [0]> <workflow># wynik uczenia modelu 1
location_models$fit[[1]]══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Formula
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
Sale_Price ~ Longitude
── Model ───────────────────────────────────────────────────────────────────────
Call:
stats::lm(formula = ..y ~ ., data = data)
Coefficients:
(Intercept) Longitude
-181.180 -1.991 Jeszcze jedną wygodną funkcja do oceny ostatecznego modelu jest funkcja last_fit, której używamy do ostatecznego modelu. Wywołanie jej powoduje uczenie modelu na zbiorze uczącym i predykcje na zbiorze testowym.
# ostatnie dopasowanie
final_lm_res <- last_fit(lm_wflow, ames_split)
# wynik dopasowania
final_lm_res# Resampling results
# Manual resampling
# A tibble: 1 × 6
splits id .metrics .notes .predictions .workflow
<list> <chr> <list> <list> <list> <list>
1 <split [2342/588]> train/test split <tibble> <tibble> <tibble> <workflow># podsumowanie modelu
collect_metrics(final_lm_res)# A tibble: 2 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 0.163 Preprocessor1_Model1
2 rsq standard 0.131 Preprocessor1_Model1# predykjca na pierwszych pięciu obserwacjach
collect_predictions(final_lm_res) %>% slice(1:5)# A tibble: 5 × 5
.pred id .row Sale_Price .config
<dbl> <chr> <int> <dbl> <chr>
1 5.23 train/test split 3 5.24 Preprocessor1_Model1
2 5.29 train/test split 7 5.33 Preprocessor1_Model1
3 5.25 train/test split 28 5.06 Preprocessor1_Model1
4 5.25 train/test split 29 5.26 Preprocessor1_Model1
5 5.23 train/test split 35 5.08 Preprocessor1_Model1
Wspomniana już inżynieria cech jest bardzo ważnym elementem budowy modelu. Inżynieria cech polega na przeformatowaniu wartości predyktorów, aby ułatwić ich efektywne wykorzystanie przez model. Obejmuje to transformacje i kodowanie danych, aby najlepiej reprezentować ich ważne cechy. Wyobraź sobie, że masz dwa predyktory w zestawie danych, które mogą być bardziej efektywnie reprezentowane w modelu jako stosunek; stworzenie nowego predyktora ze stosunku oryginalnych dwóch jest prostym przykładem inżynierii cech.
Weźmy lokalizację domu w Ames jako bardziej ambitny przykład. Istnieje wiele sposobów, w jakie te informacje przestrzenne mogą być eksponowane w modelu, w tym sąsiedztwo (miara jakościowa), długość/szerokość geograficzna, odległość do najbliższej szkoły lub Uniwersytetu Stanowego Iowa, i tak dalej. Wybierając sposób kodowania tych danych w modelowaniu, możemy wybrać opcję, która naszym zdaniem jest najbardziej związana z wynikiem. Oryginalny format danych, na przykład numeryczny (jak odległość) lub kategoryczny (np. sąsiedztwo), jest również czynnikiem decydującym o przeprowadzeniu inżynierii cech.
Inne przykłady przetwarzania wstępnego w celu zbudowania lepszych cech dla modelowania to:
Inżynieria cech i wstępne przetwarzanie danych może również obejmować przeformatowanie, które może być wymagane przez model. Niektóre modele używają metryki odległości geometrycznej i w konsekwencji predyktory numeryczne powinny być wyśrodkowane i przeskalowane tak, aby wszystkie były w tych samych jednostkach8. W przeciwnym razie wartości odległości byłyby zniekształcone przez skalę każdej kolumny.
8 przykładem może być model kNN
W ekosystemie tidymodels do realizowania inżynierii cech został dedykowany pakiet recipes.
Przykład 6.1 Dla przykładu przeprowadzimy transformację kilku cech zbioru ames:
Ze względu na asymetrię rozkładu zmiennej Gr_Liv_Area załóżmy, że początkowy model regresji będzie opisany równaniem:
Wywołanie tej funkcji dokonało by następujących czynności na predyktorach i zmiennej zależnej:
Sale_Price została by przypisana jako zależna;Gr_Liv_Area została by przekształcona logarytmicznie;Neighborhood i Bldg_Type zostały by zamienione na indykatory stanów.Te czynności byłyby wykonane również podczas predykcji na podstawie tego modelu. Chcąc przeprowadzić te czynności w pakiecie recipes wykorzystujemy kroki step_:
Jaka jest przewaga stosowania przepisów, nad prostą formułą lub surowymi predykatorami? Jest ich kilka, w tym:
all_nominal_predictors może być użyta do uchwycenia wielu zmiennych dla określonych typów przetwarzania, podczas gdy formuła wymagałaby wyraźnego wymienienia każdej z nich.Oczywiście przepisy można (a nawet trzeba) łączyć z przepływami.
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: linear_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
2 Recipe Steps
• step_log()
• step_dummy()
── Model ───────────────────────────────────────────────────────────────────────
Linear Regression Model Specification (regression)
Computational engine: lm lm_fit <- fit(lm_wflow, ames_train)Przez to, że przepis na preprocessing został zapisany w przepływie, to zostanie on zastosowany (co jest konieczne) również do zbioru testowego używając funkcji predict.
Możemy się przekonać, że faktycznie przepisy zostały wykonane podczas uczenia modelu.
lm_fit %>%
extract_recipe(estimated = TRUE)Otrzymany model jest postaci:
lm_fit %>%
extract_fit_parsnip() %>%
tidy() %>%
slice(1:5) # oczywiście parametrów modelu jest dużo więcej# A tibble: 5 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -0.876 0.233 -3.76 1.77e- 4
2 Gr_Liv_Area 0.631 0.0141 44.8 2.50e-316
3 Year_Built 0.00208 0.000118 17.6 2.38e- 65
4 Neighborhood_College_Creek 0.0135 0.00822 1.64 1.01e- 1
5 Neighborhood_Old_Town -0.0251 0.00837 -3.00 2.71e- 3Dane są przekazywane do receptur na różnych etapach.
Po pierwsze, podczas wywołania recipe(..., dane), zestaw danych jest wykorzystywany do określenia typów danych dla każdej kolumny, tak aby można było użyć selektorów takich jak all_numeric() lub all_numeric_predictors().
Po drugie, podczas przygotowywania danych za pomocą fit(workflow, data), dane treningowe są używane do wszystkich operacji estymacji, w tym czynności z przepisu, który może być częścią przepływu, od określenia poziomów czynników do obliczania komponentów PCA i wszystkiego pomiędzy.
Wreszcie, gdy używamy predict(workflow, new_data), żadne parametry modelu czy preprocessingu, jak te z przepisu, nie są ponownie szacowane przy użyciu wartości z new_data. Weźmy jako przykład centrowanie i skalowanie przy użyciu step_normalize(). Używając tego kroku, średnie i odchylenia standardowe z odpowiednich kolumn są określane z zestawu treningowego; nowe próbki w czasie predykcji są normalizowane przy użyciu tych wartości z treningu, gdy wywoływana jest funkcja predict().
Wszystkie kroki przetwarzania wstępnego i inżynierii cech wykorzystują tylko dane treningowe. W przeciwnym razie wyciek informacji może negatywnie wpłynąć na wydajność modelu, gdy jest on używany z nowymi danymi.

Czynności, które można wykonać przy użyciu kroków/przepisów jest bardzo wiele, od bardzo prostych, jak centrowanie i skalowanie (step_nomalize()), po wyrafinowane, jak wybór spośród dni tygodnia tylko tych, które nie wypadały w święta (step_holiday()). W trakcie budowania modelu różne czynności będą wymagane, a wśród nich bardzo często zdarza się, że trzeba obsłużyć zmienne niezależne typu faktor. Możemy to zrobić na kilka sposobów. Oczywiście najczęściej stosowaną jest zamiana poziomów czynnika na indykatory. Co jednak w przypadku gdy pewien poziom czynnika nie wystąpił w zbiorze uczącym. Zamiana go na indykator powoduje powstanie stałej zmiennej, która jest bezużyteczna w uczeniu modelu. Można oczywiście przystąpić do imputacji takiej wartości, a sposobów na jej realizację jest bardzo wiele. Pomijając techniki korzystające z modeli pomocniczych, jak step_impute_knn czy step_impute_bag, można też zastąpić brak stałą wartością (step_unknown). Podobnie, jeśli przewidujemy, że w testowych danych może pojawić się nowy poziom czynnika, step_novel() może w tym celu przydzielić mu nowy poziom czynnika.
Dodatkowo, funkcja step_other() może być użyta do przeanalizowania częstotliwości poziomów czynników w zbiorze treningowym i przekonwertowania rzadko występujących wartości do poziomu “inne”, z progiem, który można określić. Dobrym przykładem jest predyktor Neighborhood w naszych danych, pokazany na Rys. 6.2.
ames_train |>
ggplot(aes(Neighborhood))+
geom_bar()+
coord_flip()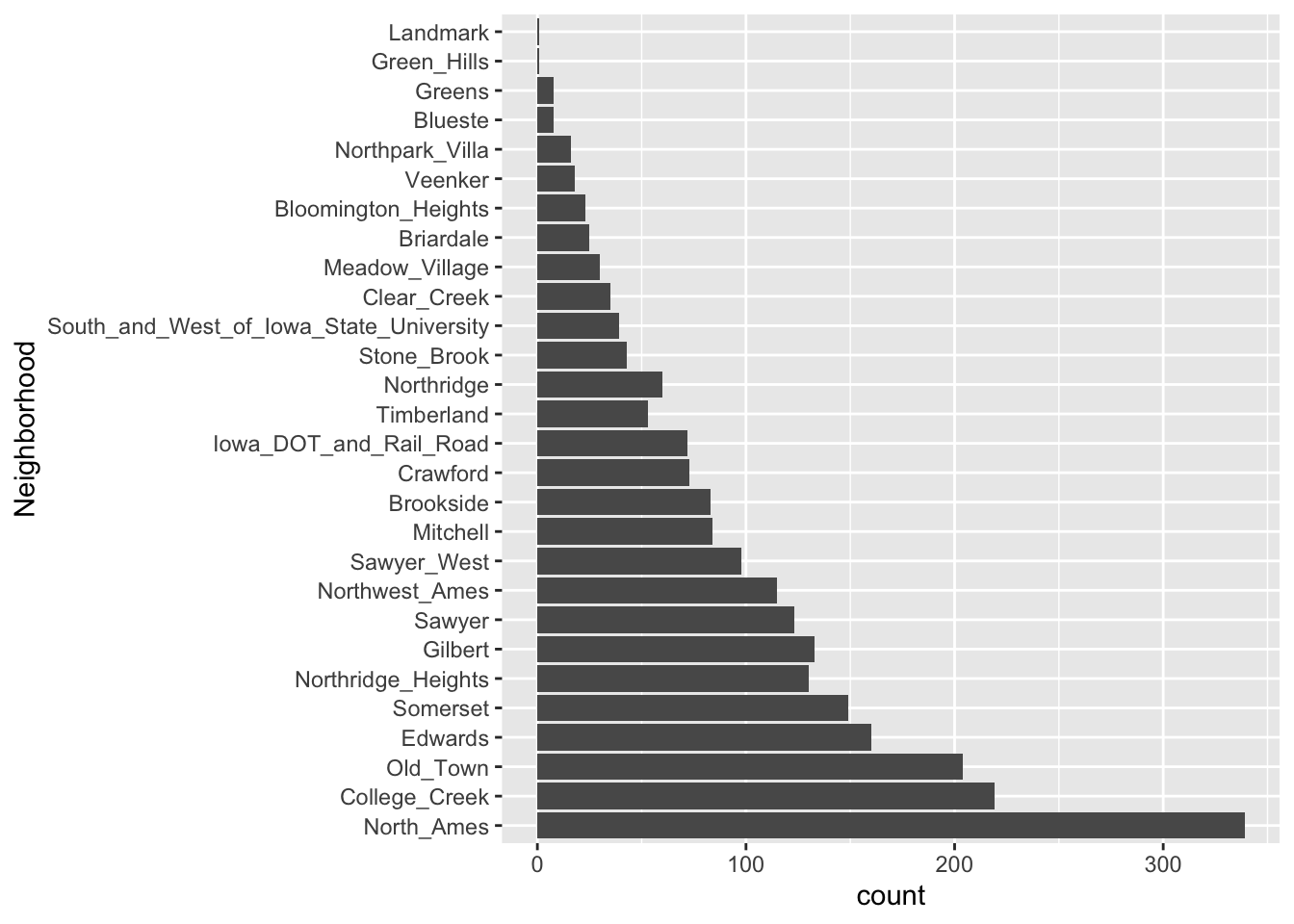
Widzimy, że dwie dzielnice mają mniej niż pięć nieruchomości w danych treningowych (Landmark i Green Hills); w tym przypadku żadne domy w dzielnicy Landmark nie zostały włączone do zbioru testowego. Dla niektórych modeli może być problematyczne posiadanie zmiennych dummy z jednym niezerowym wpisem w kolumnie. Przynajmniej jest wysoce nieprawdopodobne, że te cechy byłyby ważne dla modelu. Jeśli dodamy step_other(Neighborhood, threshold = 0.01) do naszego przepisu, 1% dzielnic9 zostanie wrzucony do nowego poziomu o nazwie “inne”. W tym zbiorze treningowym próg ten obejmie siedem sąsiedztw.
9 najrzadziej występujący
W kodowaniu zmiennych typu faktor na indykatory stanów zazwyczaj korzysta się z pełno-rzędowego przekształcenia, czyli dla faktora z 5 kategoriami, jeden traktuje się jako referencyjny, a pozostałe się koduje indykatorami. Powstała w ten sposób macierz modelu jest pełnego rzędu. Takie zachowanie jest domyślne używając funkcji step_dummy. Jednak niektóre modele wymagają kodowania one-hot edcoding, które tworzy indykatory wszystkich kategorii. Chcąc wywołać kodowanie one-hot używamy funkcji step_dummy(…, one_hot = TRUE).
Jeszcze innym ciekawym zagadnieniem podczas budowy jest odpowiedź na pytanie, czy model powinien zawierać interakcje efektów. Pozwalają to na stwierdzenie czy wpływ jednej zmiennej na wynik jest modyfikowany przez inną zmienną. W naszym przykładzie domów ames też możemy podejrzewać istnienie interakcji, ponieważ na Rys. 6.3 można zauważyć inny charakter zależności dla różnych typów budynków.
ggplot(ames_train, aes(x = Gr_Liv_Area, y = 10^Sale_Price)) +
geom_point(alpha = .2) +
facet_wrap(~ Bldg_Type) +
geom_smooth(method = lm, formula = y ~ x, se = FALSE, color = "lightblue") +
scale_x_log10() +
scale_y_log10() +
labs(x = "Gross Living Area", y = "Sale Price (USD)")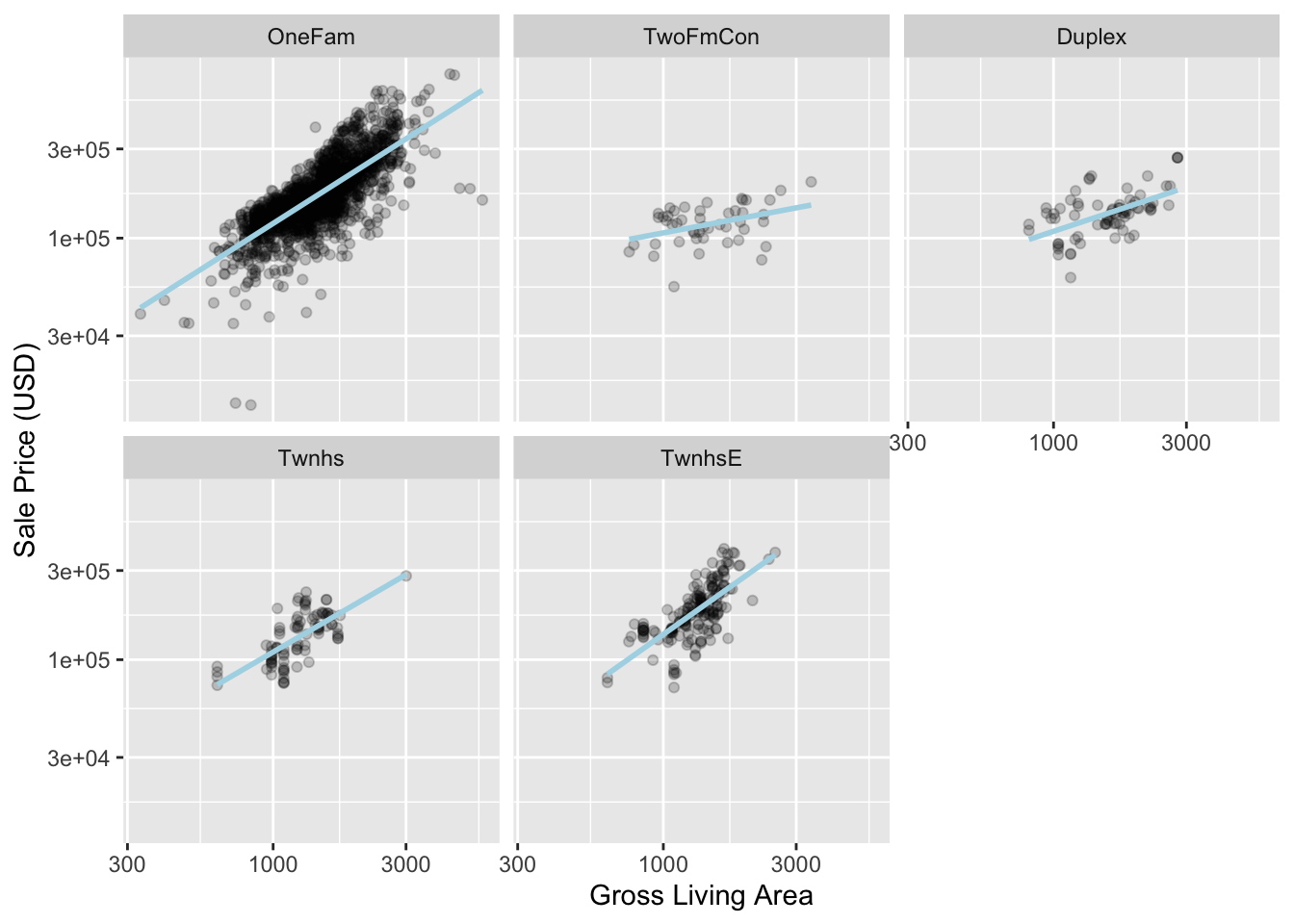
Gr_Liv_Area i Bldg_Type
W pakiecie recipes istnieje oddzielny krok to tworzenia interakcji.
simple_ames <-
recipe(Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type,
data = ames_train) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_other(Neighborhood, threshold = 0.01) %>%
step_dummy(all_nominal_predictors()) %>%
# Gr_Liv_Area is on the log scale from a previous step
step_interact( ~ Gr_Liv_Area:starts_with("Bldg_Type_") )Można ją było również dodać w klasyczny sposób +var1:var2 wpisując do formuły. Jednak w naszym przypadku ten sposób nie byłby poprawny, ponieważ to kazałoby funkcji step_interact(), aby stworzyła indykatory, a następnie utworzyć interakcje. W rzeczywistości, program nie miałby jak stworzyć interakcji, ponieważ powstałyby już nowe zmienne z prefiksem Bldg_Type_.
Powyższy przykład pokazuje, że kolejność włączania kroków jest bardzo ważna.

Bardzo często analizowane zależności są bardzo złożone i wykazują nieliniowy charakter. Jednym ze sposobów modelowania takich relacji jest aproksymacja ich za pomocą rozbudowanych modeli liniowych składających się z olbrzymiej liczby kombinacji liniowych predyktorów10. Innym sposobem obsługi tego zjawiska jest odpowiednie przekształcenie predyktorów, tak aby zamodelować złożony charakter zależności. Często w tym miejscu są polecane funkcje wielomianowe. Mają one jednak jedną poważną wadę, ponieważ o ile mogą dobrze opisywać zależność w analizowanej dziedzinie, to ekstrapolacja tej zależności często nie ma sensu. Z pomocą mogą przyjść splajny (ang. spline), czyli funkcje bazowe modeli GAM (ang. Generalized Additive Models). Nie wchodząc w szczegóły modeli GAM, splajny pozwalają na lokalną estymację zależności11 .
10 przykładem może być sieć neuronowa
11 lokalną - czyli pomiędzy punktami węzłowymi, im więcej punktów węzłowych wym większa elastyczność splajnów
library(patchwork)
library(splines)
plot_smoother <- function(deg_free) {
ggplot(ames_train, aes(x = Latitude, y = 10^Sale_Price)) +
geom_point(alpha = .2) +
scale_y_log10() +
geom_smooth(
method = lm,
formula = y ~ ns(x, df = deg_free),
color = "lightblue",
se = FALSE
) +
labs(title = paste(deg_free, "Spline Terms"),
y = "Sale Price (USD)")
}
( plot_smoother(2) + plot_smoother(5) ) / ( plot_smoother(20) + plot_smoother(100) )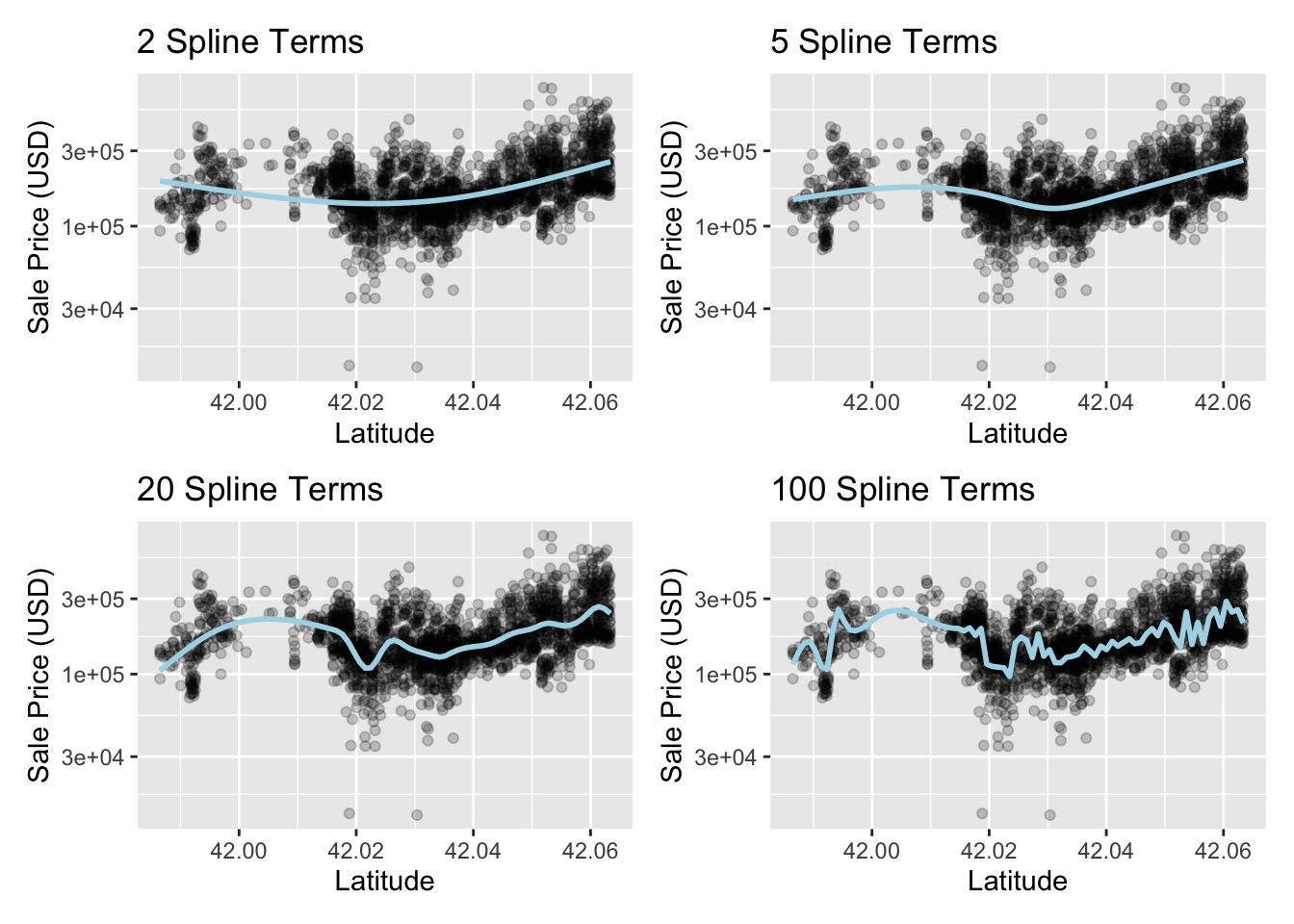
Rozwiązanie z 2 i 100 punktami węzłowymi wykazuje niedopasowanie i nadmierne dopasowanie odpowiednio. Wybór 5 lub 20 punktów wydaje się dużo lepszy. Ostatecznie ten hiperparametr modelu można kalibrować, ale to nie będzie naszym celem w tym przykładzie.
recipe(Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type + Latitude,
data = ames_train) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_other(Neighborhood, threshold = 0.01) %>%
step_dummy(all_nominal_predictors()) %>%
step_interact( ~ Gr_Liv_Area:starts_with("Bldg_Type_") ) %>%
step_ns(Latitude, deg_free = 20)Inna powszechna metoda reprezentowania wielu cech jednocześnie nazywana jest ekstrakcją cech. Większość z tych technik tworzy nowe cechy z predyktorów, które wychwytują informacje w szerszym zestawie jako całości. Na przykład, analiza składowych głównych (PCA) próbuje wyodrębnić jak najwięcej oryginalnej informacji w zestawie predyktorów przy użyciu mniejszej liczby cech. PCA jest liniową metodą ekstrakcji, co oznacza, że każda nowa cecha jest liniową kombinacją oryginalnych predyktorów. Jednym z ciekawych aspektów PCA jest to, że każda z nowych cech, zwanych głównymi składowymi, jest nieskorelowana z innymi. Z tego powodu PCA może być bardzo skuteczne w redukcji korelacji pomiędzy predyktorami.
W danych ames, kilka predyktorów mierzy powierzchnię nieruchomości, takich jak całkowita powierzchnia piwnicy (Total_Bsmt_SF), powierzchnia pierwszego piętra (First_Flr_SF), powierzchnia mieszkalna (Gr_Liv_Area), i tak dalej. PCA może być sposobem reprezentowania tych potencjalnie zbędnych zmiennych w mniej wymiarowej przestrzeni cech. Oprócz powierzchni mieszkalnej brutto, predyktory mają przyrostek SF w swoich nazwach (oznaczające stopy kwadratowe), więc krok przepisu PCA mógłby wyglądać tak:
step_pca(matches("(SF$)|(Gr_Liv)"))Zauważmy, że wszystkie wspomniane kolumny są mierzone w stopach kwadratowych, a PCA zakłada, że wszystkie predyktory są w tej samej skali. W tym przypadku to prawda, ale często ten krok musi być poprzedzony przez step_normalize().
Istnieją kroki przepisów dla innych metod ekstrakcji, takie jak: analiza składowych niezależnych (ICA), faktoryzacja macierzy nieujemnej (NNMF), skalowanie wielowymiarowe (MDS), jednolita aproksymacja i projekcja (UMAP) i inne.
Do tej pory wspominaliśmy o krokach, które dotyczyły zmiennych, ale istnieją również takie, które dotyczą wierszy. Na przykład, techniki podpróbkowania (ang. subsampling) dla nierównowagi klas zmieniają proporcje klas w danych przekazywanych do modelu; techniki te często nie poprawiają ogólnej wydajności, ale mogą generować lepiej zachowujące się rozkłady przewidywanych prawdopodobieństw klas. O nich jednak będzie więcej w dalszej części tej książki.
Istnieją inne funkcje krokowe, które są również oparte na wierszach, jak: step_filter(), step_sample(), step_slice() i step_arrange().
Tylko zestaw treningowy powinien być poddany wpływowi tych technik. Zbiór testowy lub inne próbki powinny być pozostawione w niezmienionym stanie, czyli ten krok przepisu nie powinien być do nich stosowany. Z tego powodu, wszystkie kroki podpróbkowania i filtrowania domyślnie ustawiają argument skip na wartość TRUE.
Przekształcenia, które mają swoje korzenie w pakiecie dplyr jak step_mutate też mogą być stosowane w przepisach. Najlepiej używać ich do prostych przekształceń, takich jak obliczanie stosunku dwóch zmiennych, (np. Bedroom_AbvGr / Full_Bath), stosunek sypialni do łazienek dla danych mieszkaniowych ames.
Podczas korzystania z tego kroku należy zachować szczególną ostrożność, aby uniknąć wycieku danych w swoim wstępnym przetwarzaniu. Rozważmy na przykład transformację x = w > mean(w). W przypadku zastosowania go do nowych danych lub danych testowych, ta transformacja użyłaby średniej w z nowych danych, a nie średniej wz danych treningowych.
Przepis może również obsługiwać dane, które nie mają tradycyjnej struktury. Na przykład pakiet textrecipes może zastosować do danych metody przetwarzania języka naturalnego. Kolumna wejściowa jest zwykle ciągiem tekstu, a różne kroki mogą być użyte do tokenizacji danych (np. podzielenia tekstu na osobne słowa), odfiltrowania tokenów i stworzenia nowych cech odpowiednich do modelowania.
Na samym początku analiz zbioru ames przekształciliśmy zmienną Sale_Price logarytmicznie. Dlaczego nie użyliśmy zamiast tego kroku
step_log(Sale_Price, base = 10)Ponieważ użycie go powodowałoby problemy przy użyciu całego przepisu na nowych danych do predykcji. Często jest bowiem tak, że zmiennej zależnej w tym zbiorze nie ma.
W przypadku prostych przekształceń kolumny (kolumn) wynikowej, zdecydowanie sugerujemy, aby operacje te były wykonywane poza przepisem.
Również wspomniane wcześniej kroki redukujące nierównowagę klasową powinny być stosowane tylko do danych uczących. Wszystkie te kroki, które chcemy wyłączyć z przetwarzania podczas predykcji na nowych zbiorach, powinny mieć włączoną flagę skip = TRUE.
Na koniec części dotyczącej inżynierii cech nauczymy model.
ames_rec <-
recipe(Sale_Price ~ Neighborhood + Gr_Liv_Area + Year_Built + Bldg_Type +
Latitude + Longitude, data = ames_train) %>%
step_log(Gr_Liv_Area, base = 10) %>%
step_other(Neighborhood, threshold = 0.01, id = "my_id") %>%
step_dummy(all_nominal_predictors()) %>%
step_interact( ~ Gr_Liv_Area:starts_with("Bldg_Type_") ) %>%
step_ns(Latitude, Longitude, deg_free = 20)
lm_wflow <-
workflow() %>%
add_model(lm_model) %>%
add_recipe(ames_rec)
lm_fit <- fit(lm_wflow, ames_train)
estimated_recipe <-
lm_fit %>%
extract_recipe(estimated = TRUE)
tidy(estimated_recipe)# A tibble: 5 × 6
number operation type trained skip id
<int> <chr> <chr> <lgl> <lgl> <chr>
1 1 step log TRUE FALSE log_p06et
2 2 step other TRUE FALSE my_id
3 3 step dummy TRUE FALSE dummy_rztdZ
4 4 step interact TRUE FALSE interact_1T8XZ
5 5 step ns TRUE FALSE ns_eTRX6 # możemy też wywołać szczegóły konkretnego kroku
tidy(estimated_recipe, id = "my_id")# A tibble: 21 × 3
terms retained id
<chr> <chr> <chr>
1 Neighborhood North_Ames my_id
2 Neighborhood College_Creek my_id
3 Neighborhood Old_Town my_id
4 Neighborhood Edwards my_id
5 Neighborhood Somerset my_id
6 Neighborhood Northridge_Heights my_id
7 Neighborhood Gilbert my_id
8 Neighborhood Sawyer my_id
9 Neighborhood Northwest_Ames my_id
10 Neighborhood Sawyer_West my_id
# ℹ 11 more rowsW modelach przedstawianych do tej pory dominowały dwie role zmiennych: predyktory (predictor) i zmienna zależna (outcome). W razie potrzeby można jednak przypisać inne role.
Na przykład, w naszym zestawie danych ames, oryginalne dane zawierały kolumnę z adresem. Może być przydatne zachowanie tej kolumny w danych, aby po dokonaniu przewidywań można było szczegółowo zbadać problematyczne wyniki. Innymi słowy, kolumna może być ważna, nawet jeśli nie jest predyktorem lub wynikiem. Aby to rozwiązać, pomocne mogą być funkcje add_role(), remove_role() i update_role(). Na przykład, dla danych dotyczących cen domów, rola kolumny adresu ulicy może być zmodyfikowana przy użyciu:
ames_rec %>% update_role(address, new_role = "street address")Po tej zmianie kolumna adresu w ramce danych nie będzie już predyktorem, ale “adresem ulicy” zgodnie z przepisem. Każdy ciąg znaków może być użyty jako rola. Również kolumny mogą mieć wiele ról (dodatkowe role są dodawane poprzez add_role()) tak, że mogą być nadane w więcej niż jednym kontekście.
Może to być pomocne, gdy dane są próbkowane. Pomaga to utrzymać kolumny, które nie są zaangażowane w dopasowanie modelu w tej samej ramce danych (a nie w zewnętrznym wektorze). Próbkowanie, opisane nieco później, tworzy alternatywne wersje danych głównie poprzez podpróbkowanie wierszy. Gdyby adres ulicy znajdował się w innej kolumnie, wymagane byłoby dodatkowe podpróbkowanie, co mogłoby prowadzić do bardziej skomplikowanego kodu i większego prawdopodobieństwa wystąpienia błędów.

Wreszcie, wszystkie funkcje kroków mają pole role, które może przypisać role do wyników kroku. W wielu przypadkach kolumny, na które wpływa krok, zachowują swoją dotychczasową rolę. Na przykład, wywołania funkcji step_log() w naszym obiekcie ames_rec wpłynęły na kolumnę Gr_Liv_Area. Dla tego kroku, domyślnym zachowaniem jest zachowanie istniejącej roli dla tej kolumny, ponieważ nie jest tworzona żadna nowa kolumna. Jako przykład przeciwny, krok do tworzenia splajnów ustawia domyślnie nowe kolumny na rolę “predyktor”, ponieważ jest to zwykle sposób, w jaki kolumny splajnów są używane w modelu.