W przypadku projektów z nowymi zbiorami danych, które nie zostały jeszcze dobrze poznane, osoba zajmująca się danymi może być zmuszona do sprawdzenia wielu kombinacji modeli i różnych kombinacji metod przygotowania danych. Powszechne jest to, że nie posiadamy wiedzy a priori na temat tego, która metoda będzie działać najlepiej z nowym zestawem danych.
Dobrą strategią jest poświęcenie trochę uwagi na wypróbowanie różnych podejść do modelowania, określenie, co działa najlepiej, a następnie zainwestowanie dodatkowego czasu na dostosowanie / optymalizację małego zestawu modeli.
Aby zademonstrować, jak przesiewać zestaw wielu modeli, użyjemy jako przykładu danych mieszanki betonowej z książki Applied Predictive Modeling(Khun i Johnson 2013). W rozdziale 10 tej książki zademonstrowano modele do przewidywania wytrzymałości na ściskanie mieszanek betonowych z wykorzystaniem składników jako zmiennych niezależnych. Oceniono wiele różnych modeli z różnymi zestawami predyktorów i typami metod wstępnego przetwarzania.
Zmienna compressive_strength jest zmienną zależną, przewidywaną w tym zadaniu. W kilku przypadkach w tym zestawie danych, ta sama formuła betonu była testowana wielokrotnie. Wolimy nie uwzględniać tych replikowanych mieszanek jako pojedynczych punktów danych, ponieważ mogą one być rozmieszczone zarówno w zbiorze treningowym, jak i testowym. Może to sztucznie zawyżyć nasze szacunki wydajności.
Podzielmy dane przy użyciu domyślnego stosunku 3:1 treningu do testu i ponownie wypróbujmy zestaw treningowy przy użyciu pięciu powtórzeń 10-krotnej walidacji krzyżowej:
Niektóre modele (zwłaszcza sieci neuronowe, KNN i SVM) wymagają predyktorów, które zostały wyśrodkowane i przeskalowane, więc niektóre przepływy pracy modelu będą wymagały przepisów z tymi krokami przetwarzania wstępnego. Dla innych modeli, tradycyjne rozwinięcie modelu powierzchni odpowiedzi (tj. interakcje kwadratowe i dwukierunkowe) jest dobrym pomysłem. Dla tych celów tworzymy dwie receptury:
Kod
normalized_rec<-recipe(compressive_strength~., data =concrete_train)%>%step_normalize(all_predictors())poly_recipe<-normalized_rec%>%step_poly(all_predictors())%>%step_interact(~all_predictors():all_predictors())
13.2 Określenie modeli
Teraz zdefiniujmy model, które chcemy przetestować:
Autorzy w Khun i Johnson (2013) określa, że sieć neuronowa powinna mieć do 27 jednostek ukrytych w warstwie. Funkcja extract_parameter_set_dials() wyodrębnia zbiór parametrów, który modyfikujemy, aby miał prawidłowy zakres parametrów:
Ponieważ zastosowaliśmy tylko jedna funkcję wstępnej obróbki danych (normalized_rec), to w podsumowaniu występują tylko kombinacje tego preprocesora i modeli. Kolumna wflow_id tworzona jest automatycznie, ale może być modyfikowana poprzez wywołanie mutate(). Kolumna info zawiera tibble z pewnymi identyfikatorami i obiektem przepływu pracy. Przepływ pracy może zostać wyodrębniony:
Kolumna option to miejsce na dowolne argumenty, których należy użyć, gdy oceniamy przepływ pracy. Na przykład, aby dodać obiekt parametrów sieci neuronowej:
Kod
normalized<-normalized%>%option_add(param_info =nnet_param, id ="normalized_neural_network")normalized
Te obiekty to tibble z dodatkową klasą workflow_set. Łączenie wierszy nie wpływa na stan zestawów, a wynik jest sam w sobie zestawem przepływów pracy:
Kod
all_workflows<-bind_rows(no_pre_proc, normalized, with_features)%>%# Make the workflow ID's a little more simple: mutate(wflow_id =gsub("(simple_)|(normalized_)", "", wflow_id))all_workflows
Prawie wszystkie modele ujęte w all_workflows zawierają parametry dostrajania. Aby ocenić ich wydajność, możemy użyć standardowych funkcji strojenia lub resamplingu (np. tune_grid() i tak dalej). Funkcja workflow_map() zastosuje tę samą funkcję do wszystkich przepływów w zestawie; domyślnie jest to tune_grid().
Dla tego przykładu, wyszukiwanie w oparciu o siatkę jest stosowane do każdego przepływu pracy, stosując jednocześnie 25 różnych kandydatów na parametry. Istnieje zestaw wspólnych opcji do wykorzystania przy każdym wykonaniu tune_grid(). Na przykład, w poniższym kodzie użyjemy tego samego próbkowania i obiektów kontrolnych dla każdego przepływu pracy, wraz z rozmiarem siatki równym 25. Funkcja workflow_map() posiada dodatkowy argument o nazwie seed, który służy do zapewnienia, że każde wykonanie tune_grid() zużywa tych samych liczb losowych.
Kolumna option zawiera teraz wszystkie opcje, których użyliśmy w wywołaniu workflow_map(). W kolumnach result, notacje tune[+] i rsmp[+] oznaczają, że obiekt nie miał żadnych problemów w procesie optymalizacji. Wartość taka jak tune[x] pojawia się, gdy wszystkie modele z jakiegoś powodu zawiodły.
Istnieje kilka wygodnych funkcji do badania wyników, takich jak grid_results. Funkcja rank_results() uporządkuje modele według wybranej metryki wydajności. Domyślnie używa ona pierwszej metryki w zestawie metryk (w tym przypadku RMSE). Przefiltrujmy wyniki, aby analizować tylko na RMSE:
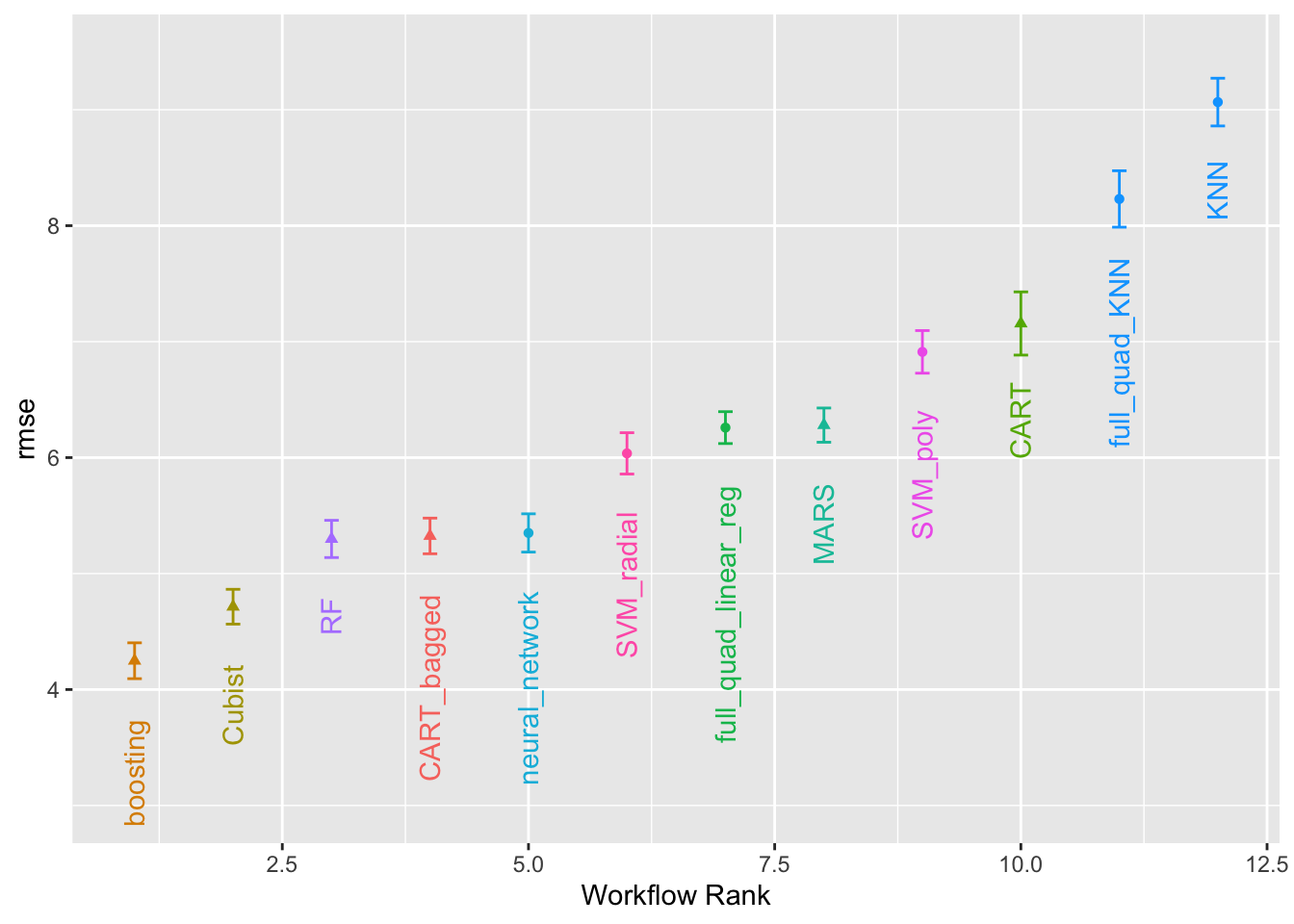
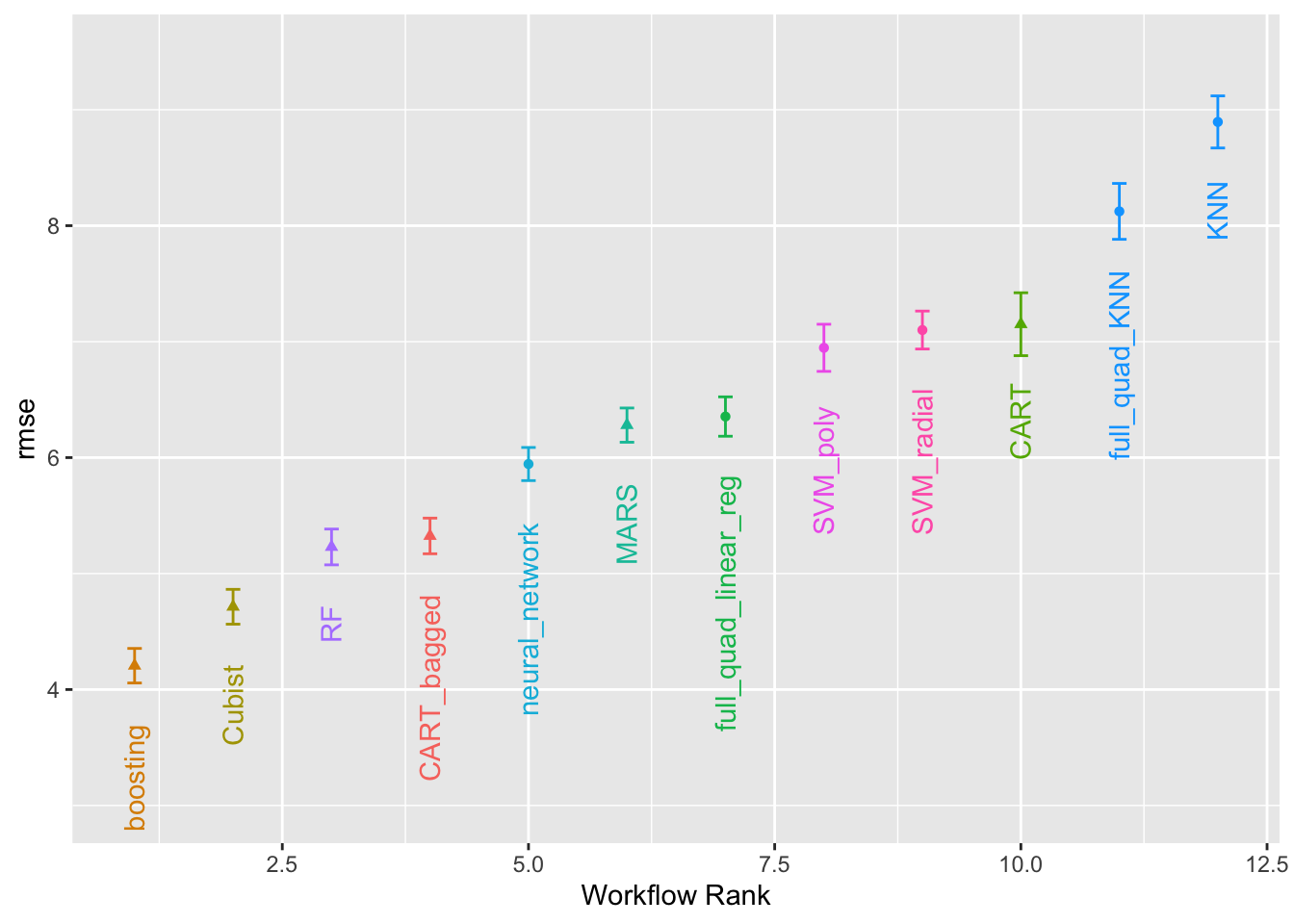
Domyślnie funkcja szereguje wszystkie zestawy kandydatów, dlatego ten sam model może pojawić się wielokrotnie na wyjściu. Opcja select_best może być użyta do uszeregowania modeli przy użyciu najlepszej kombinacji dostrajania parametrów. Metoda autoplot() tworzy wykresy rankingowy; posiada ona również argument select_best. Wykres na Rys. 13.1 wizualizuje najlepsze wyniki dla każdego modelu i jest generowany za pomocą:
Kod
autoplot(grid_results, rank_metric ="rmse", # <- how to order models metric ="rmse", # <- which metric to visualize select_best =TRUE# <- one point per workflow)+geom_text(aes(y =mean-1/2, label =wflow_id), angle =90, hjust =1)+lims(y =c(3, 9.5))+theme(legend.position ="none")
Rys. 13.1: Oszacowany RMSE (i przybliżone przedziały ufności) dla najlepszej konfiguracji modelu w każdym przepływie pracy
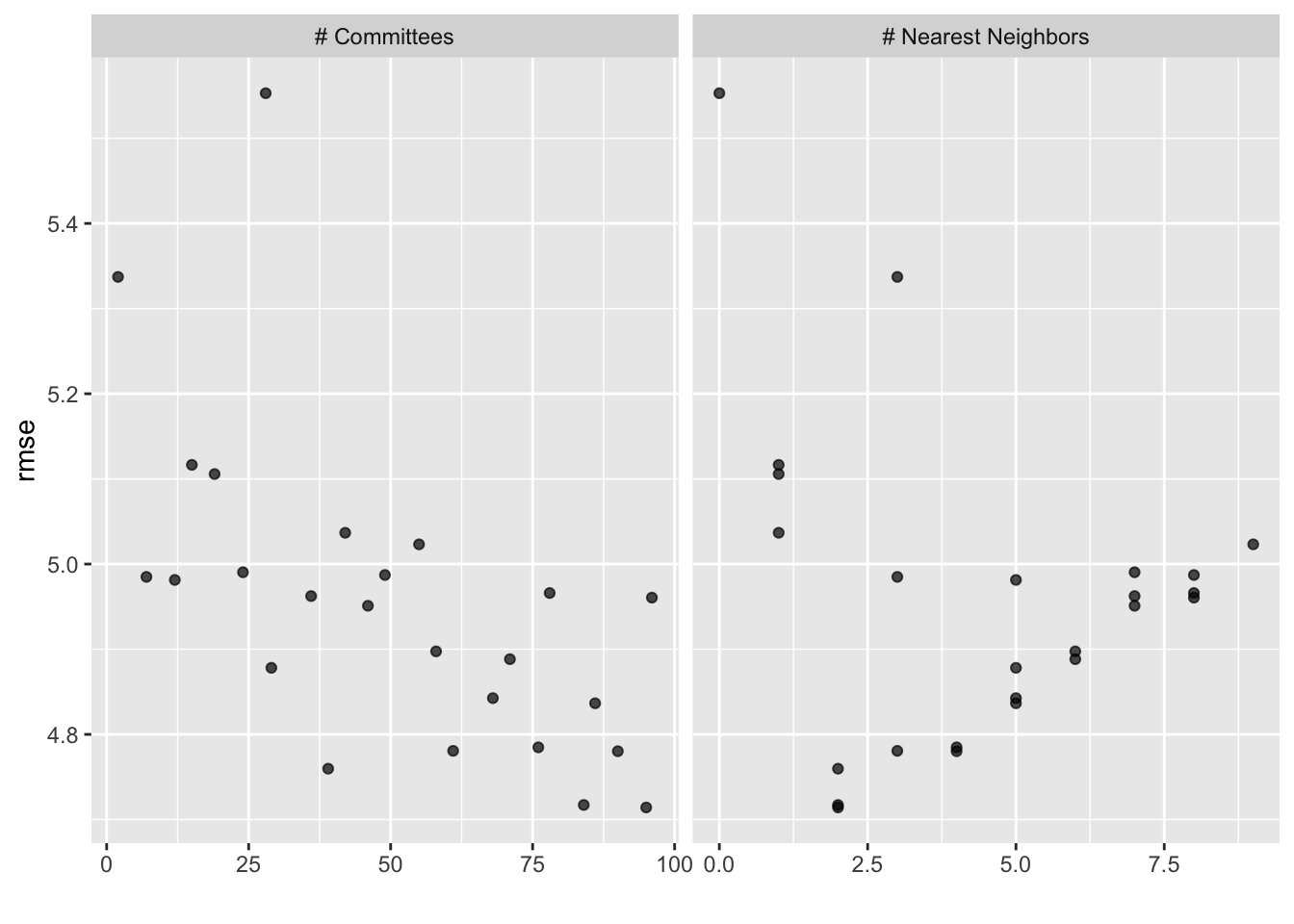
W przypadku, gdy chcesz zobaczyć wyniki dostrajania parametrów dla konkretnego modelu, tak jak na Rys. 13.2, argument id może przyjąć pojedynczą wartość z kolumny wflow_id dla którego modelu ma być wykreślony:
Kod
autoplot(grid_results, id ="Cubist", metric ="rmse")
Rys. 13.2: Wizualizacja RMSE w kontekście konfiguracji hiperparametrów modelu Cubist
W powyższym procesie optymalizacji przeuczono 12600 modeli, co zajęło około 2 godzin przy wykorzystaniu 4 rdzeni procesora. Pokazuje to, że zagadnienie tuningu nawet kilku kandydackich modeli zajmuje sporo czasu.
13.4 Efektywna filtracja modeli
Jedną z metod efektywnego przesiewania dużego zbioru modeli jest zastosowanie podejścia wyścigowego opisanego wcześniej. Mając zestaw przepływów pracy, możemy użyć funkcji workflow_map() do podejścia wyścigowego.
Rys. 13.3: Oszacowane RMSE (i przybliżone przedziały ufności) dla najlepszej konfiguracji modelu w poszukiwaniu za pomocą metody wyścigowej.
Podejście wyścigowe oszacowało łącznie 1050 modeli, 8,33% z pełnego zestawu 12600 modeli w pełnej siatce. W rezultacie podejście wyścigowe trwało nieco ponad 17 min., więc było 7-krotnie szybsze1.
1 Wartości te będą zależały od sprzętu na jakim wykonuje się obliczenia
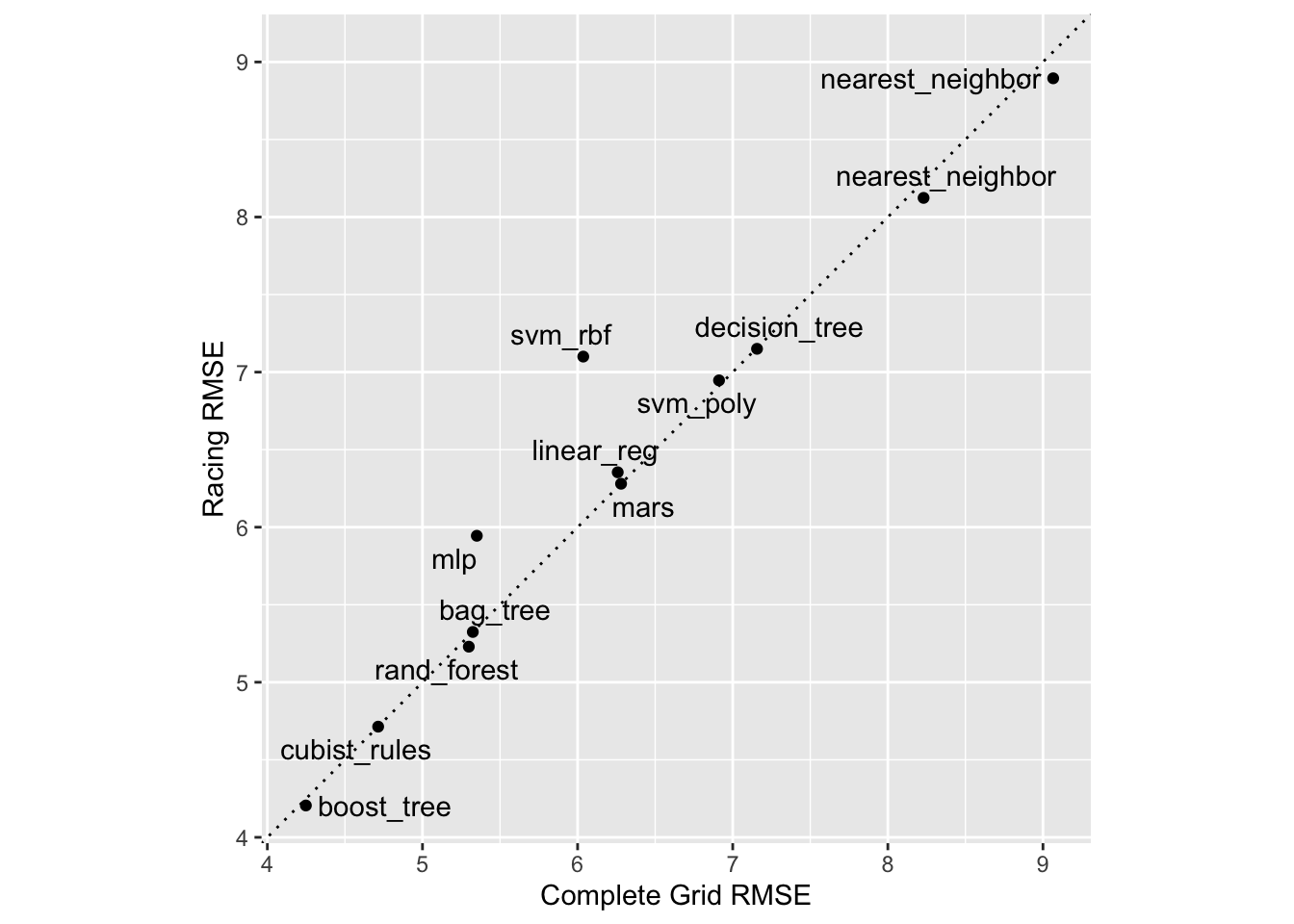
Na ile zbliżone wyniki otrzymaliśmy stosując obie metody tuningu?
Kod
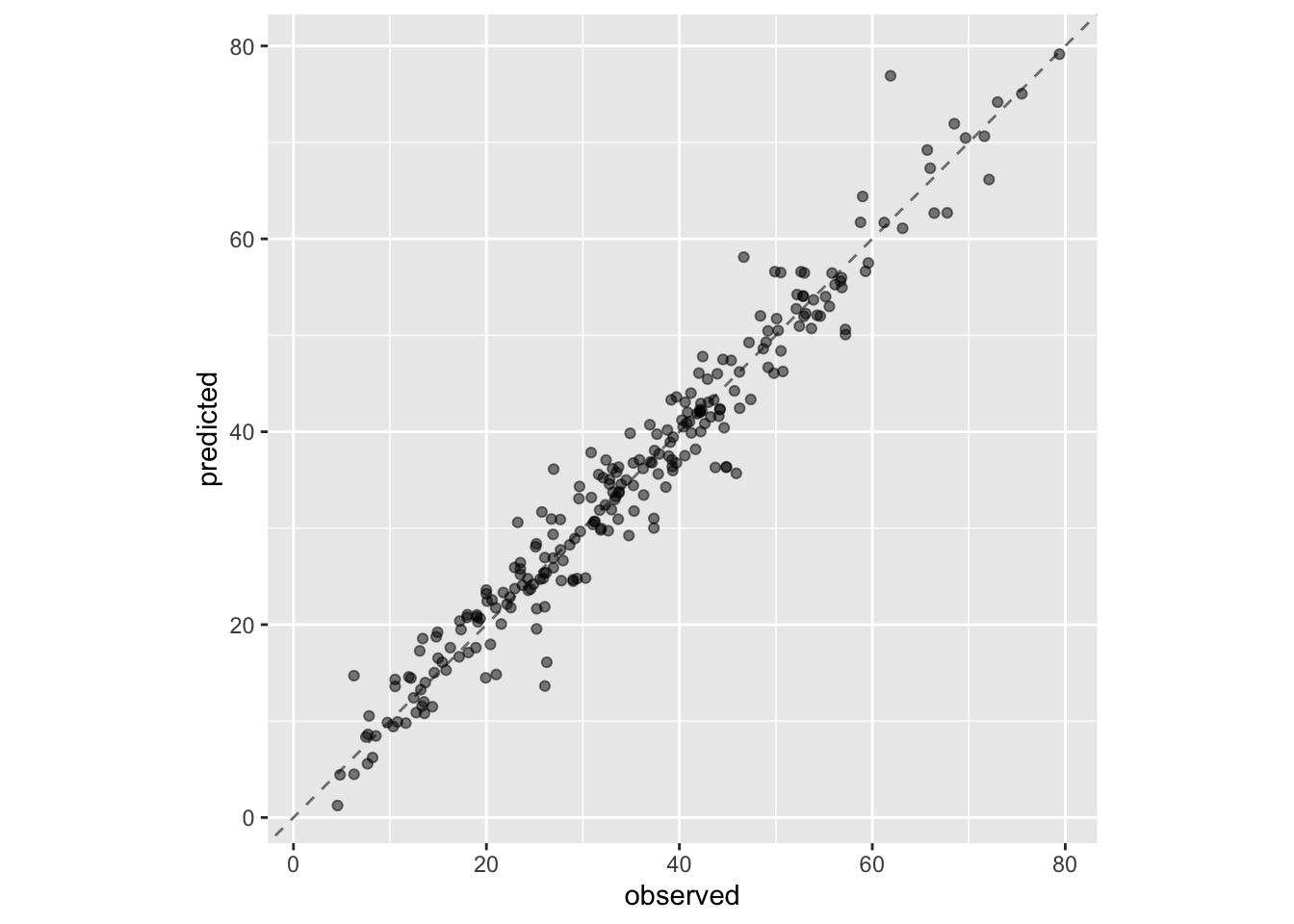
matched_results<-rank_results(race_results, select_best =TRUE)%>%select(wflow_id, .metric, race =mean, config_race =.config)%>%inner_join(rank_results(grid_results, select_best =TRUE)%>%select(wflow_id, .metric, complete =mean, config_complete =.config, model), by =c("wflow_id", ".metric"),)%>%filter(.metric=="rmse")library(ggrepel)matched_results%>%ggplot(aes(x =complete, y =race))+geom_abline(lty =3)+geom_point()+geom_text_repel(aes(label =model))+coord_obs_pred()+labs(x ="Complete Grid RMSE", y ="Racing RMSE")
Podczas gdy podejście wyścigowe wybrało te same parametry kandydata co kompletna siatka tylko dla 41,67% modeli, metryki wydajności modeli wybranych przez wyścig były prawie równe. Korelacja wartości RMSE wyniosła 0,968, a korelacja rangowa 0,951. Wskazuje to, że w obrębie modelu istniało wiele kombinacji dostrajania parametrów, które dawały niemal identyczne wyniki.
13.5 Finalizacja modelu
Podobnie do tego, co pokazaliśmy w poprzednich rozdziałach, proces wyboru ostatecznego modelu i dopasowania go na zbiorze treningowym jest prosty. Pierwszym krokiem jest wybranie zbioru treningowego do sfinalizowania. Ponieważ model boosted tree działał dobrze, wyodrębnimy go ze zbioru, zaktualizujemy parametry o numerycznie najlepsze ustawienia i dopasujemy do zbioru treningowego. W przypadku gdy mamy wątpliwości dotyczące siatki hiperparametrów dobranych podczas filtrowania modeli, np. że pomija ona ważne kombinacje, możemy zastosować do wybranego modelu metody finetune przedstawione w poprzednim rozdziale.