Wszystkie modele są błędne, ale niektóre są przydatne - George E.P. Box
Ocenę jakości dopasowania modelu można dokonywać na różne sposoby:
porównując przewidywaną klasę lub wartość na podstawie modelu z obserwowaną prawdziwą klasą lub wartością;
korzystając z ilustracji graficznej przedstawiając np. na osi odciętych wartości przewidywane na podstawie modelu, a na osi rzędnych wartości obserwowane w danych1; choć można się też spotkać z innymi wykresami, jak np. krzywe ROC, czy Precision-Recall;
przedstawić klasyfikację w postaci macierzy błędnych klasyfikacji (ang. confusion matrix);
najczęściej można się jednak spotkać z podejściem wykorzystującym różnego rodzaju miarami dopasowania modelu.
1 dotyczy to modeli regresyjnych
2 czyli większej niż dwie
W tym rozdziale przedstawimy najpowszechniej stosowane miary dopasowania modelu w podziale na modele regresyjne i klasyfikacyjne. Przy czym w rodzinie modeli klasyfikacyjnych można wyszczególnić podklasę modeli, dla których zmienna wynikowa jest binarna. Modele ze zmienną wynikową binarną stanowią oddzielną klasę w kontekście dopasowania, ponieważ stosuje się wówczas inne miary dopasowania. Co prawda miary te można zastosować również w przypadku zmiennej wynikowej o większej liczbie kategorii2, ale wymaga to wówczas przyjęcia dodatkowych umów w jaki sposób je stosować, a sposoby te nie są jednoznaczne.
4.1 Miary dopasowania modeli regresyjnych
Przegląd zaczniemy od najlepiej znanych miar, a skończymy na rzadziej stosowanych, jak funkcja straty Hubera.
4.1.1\(R^2\)
Miara stosowana najczęściej do oceny dopasowania modeli liniowych, a definiowana jako:
gdzie \(\hat{y}_i\) jest \(i\)-tą wartością przewidywaną na podstawie modelu, \(\bar{y}\) jest średnią zmiennej wynikowej, a \(y_i\) jest \(i\)-tą wartością obserwowaną. Już na kursie modeli liniowych dowiedzieliśmy się o wadach tak zdefiniowanej miary. Wśród nich należy wymienić przede wszystkim fakt, iż dołączając do modelu zmienne, których zdolność predykcyjna jest nieistotna3, to i tak rośnie \(R^2\)
3 czyli nie mają znaczenia w przewidywaniu wartości wynikowej
4 drzewo składa się tylko z korzenia
W przypadku modeli liniowych wprowadzaliśmy korektę eliminującą tą wadę, jednak w przypadku modeli predykcyjnych skorygowana miara \(R^2_{adj}\) nie wystarcza. W sytuacji gdy modele mają bardzo słabą moc predykcyjną, czyli są np. drzewem regresyjnym bez żadnej reguły podziału4, wówczas można otrzymać ujemne wartości obu miar. Zaleca się zatem wprowadzenie miary, która pozbawiona jest tej wady, a jednocześnie ma tą sama interpretację. Definiuję się ją następująco:
Miara zdefiniowana w (4.2) zapewnia nam wartości w przedziale (0,1), a klasyczna miara (4.1) nie (Kvalseth 1985). Tradycyjna jest zdefiniowana w bibliotece yardstick5 pod nazwą rsq_trad, natomiast miara oparta na korelacji jako rsq. Oczywiście interpretacja jest następująca, że jeśli wartość \(\tilde{R}^2\) jest bliska 1, to model jest dobrze dopasowany, a bliskie 0 oznacza słabe dopasowanie.
5 będącej częścią ekosystemu tidymodels
4.1.2 RMSE
Inną powszechnie stosowaną miarą do oceny dopasowania modeli regresyjnych jest pierwiastek błędu średnio-kwadratowego (ang. Root Mean Square Error), zdefiniowany następująco:
gdzie \(n\) oznacza liczebność zbioru danych na jakim dokonywana jest ocena dopasowania. Im mniejsza jest wartość błędu RMSE tym lepiej dopasowany jest model. Niestety wadą tej miary jest brak odporności na wartości odstające. Błąd w tym przypadku jest mierzony w tych samych jednostkach co mierzona wielkość wynikowa \(Y\). Do wywołania jej używamy funkcji rmse.
4.1.3 MSE
Ściśle powiązaną miarą dopasowania modelu z RMSE jest błąd średnio-kwadratowy (ang. Mean Square Error). Oczywiście jest on definiowany jako kwadrat RMSE. Interpretacja jest podobna jak w przypadku RMSE. W tym przypadku błąd jest mierzony w jednostkach do kwadratu i również jak w przypadku RMSE miara ta jest wrażliwa na wartości odstające. Wywołujemy ją funkcją mse.
4.1.4 MAE
Chcąc uniknąć (choćby w części) wrażliwości na wartości odstające stosuje się miarę średniego absolutnego błędu (ang. Mean Absolut Error). Definiujemy go następująco:
Ponieważ wartości błędów \(y_i-\hat{y}_i\) nie są podnoszone do kwadratu, to miara ta jest mniej wrażliwa na punkty odstające. Interpretacja jej jest podobna jak MSE i RMSE. Do wywołania jej używamy funkcji mae. Błąd w tym przypadku jest również mierzony w tych samych jednostkach co \(Y\).
Wymienione miary błędów są nieunormowane, a dopasowania modeli możemy dokonywać jedynie porównując wynik błędu z wartościami \(Y\), lub też przez porównanie miar dla różnych modeli.
4.1.5 MAPE
Średni bezwzględny błąd procentowy (ang. Mean Absolute Percentage Error) jest przykładem miary błędu wyrażanego w procentach. Definiuje się go następująco:
Interpretujemy ten błąd podobnie jak poprzednie pomimo, że jest wyrażony w procentach. Do wywołania go w pakiecie yardstick używamy funkcji mape.
4.1.6 MASE
Średni bezwzględny błąd skalowany (ang. Mean Absolute Scaled Error) jest miarą dokładności prognoz. Została zaproponowana w 2005 roku przez statystyka Roba J. Hyndmana i profesora Anne B. Koehler, którzy opisali ją jako “ogólnie stosowaną miarę dokładności prognoz bez problemów widocznych w innych miarach” (Hyndman i Koehler 2006). Średni bezwzględny błąd skalowany ma korzystne właściwości w porównaniu z innymi metodami obliczania błędów prognoz, takimi jak RMSE, i dlatego jest zalecany do określania dokładności prognoz w szeregach czasowych (Franses 2016). Definiujemy go następująco
\[
MASE = \frac{\sum_{i=1}^n\vert y_i-\hat{y}_i\vert}{\sum_{i=1}^n\vert y_i-\bar{y}_i\vert}.
\tag{4.6}\]
Ponieważ we wzorze wykorzystywane są rzeczywiste, a nie bezwzględne wartości błędów prognozy, dodatnie i ujemne błędy prognozy mogą się wzajemnie kompensować. W rezultacie wzór ten można wykorzystać jako miarę błędu systematycznego w prognozach. Wadą tej miary jest to, że jest ona zawsze określona, gdy pojedyncza wartość rzeczywista wynosi zero. Wywołujemy ją za pomocą mpe.
4.1.8 MSD
Średnia znakowa różnic (ang. Mean Signed Deviation), znana również jako średnie odchylenie znakowe i średni błąd znakowy, jest statystyką próbkową, która podsumowuje, jak dobrze szacunki \(\hat{Y}\) pasują do wielkości obserwowanych \(Y\). Definiujemy ją następująco:
Interpretacja podobnie jak w przypadku innych błędów i mniej wynosi miara tym lepiej dopasowany model. Wywołujemy go funkcją msd.
Istnieje cały szereg miar specjalistycznych rzadziej stosowanych w zagadnieniach regresyjnych. Wśród nich należy wymienić
4.1.9 Funkcja straty Hubera
Funkcja straty Hubera (ang. Huber loss) jest miarą błędu nieco bardziej odporną na punkty odstające niż RMSE. Definiujemy ją następująco:
\[
L_{\delta}(y, \hat{y})= \begin{cases}
\frac12 (y_i-\hat{y}_i)^2, &\text{ jeśli }\vert y_i-\hat{y}_i\vert\leq\delta\\
\delta\cdot \vert y_i-\hat{y}_i\vert-\tfrac12\delta, &\text{ w przeciwnym przypadku}.
\end{cases}
\tag{4.9}\]
W implementacji yardstick\(\delta=1\) natomiast wyliczanie funkcji straty następuje przez uśrednienie po wszystkich obserwacjach. Z definicji widać, że funkcja straty Hubera jest kombinacją MSE i odpowiednio przekształconej miary MAE, w zależności od tego czy predykcja znacząco odbiegają od obserwowanych wartości. Wywołujemy ją przez funkcję huber_loss.
4.1.10 Funkcja straty Pseudo-Hubera
Funkcja straty Pseudo-Hubera (ang. Pseudo-Huber loss) może być stosowana jako gładkie przybliżenie funkcji straty Hubera. Łączy ona najlepsze właściwości straty kwadratowej6 i straty bezwzględnej7, będąc silnie wypukłą, gdy znajduje się blisko celu (minimum) i mniej stromą dla wartości ekstremalnych . Skala, przy której funkcja straty Pseudo-Hubera przechodzi od straty L2 dla wartości bliskich minimum do straty L1 może być kontrolowana przez parametr \(\delta\). Funkcja straty Pseudo-Hubera zapewnia, że pochodne są ciągłe dla wszystkich stopni . Definiujemy ją następująco :
6 inaczej w normie L2
7 w normie L1
\[
L_{\delta}(y-\hat{y})=\delta^2\left(\sqrt{1+((y-\hat{y})/\delta)^2}-1\right).
\tag{4.10}\] Wywołujemy ją za pomocą funkcji huber_loss_pseudo.
4.1.11 Logarytm funkcji straty dla rozkładu Poissona
Logarytm funkcji straty dla rozkładu Poissona (ang. Mean log-loss for Poisson data) definiowany jest w następujący sposób:
Symetryczny średni bezwzględny błąd procentowy (ang. Symmetric Mean Absolute Percentage Error) jest miarą dokładności opartą na błędach procentowych (lub względnych). Definiujemy ją następująco:
Stosunek wydajności do odchylenia standardowego (ang. Ratio of Performance to Deviation) definiujemy jako
\[
RPD = \frac{SD}{RMSE},
\tag{4.12}\]
gdzie \(SD\) oczywiście oznacza odchylenie standardowe zmiennej zależnej. Tym razem interpretujemy go w ten sposób, że im wyższa jest wartość RPD tym lepiej dopasowany model. Wywołujemy za pomocą rpd.
W szczególności w dziedzinie spektroskopii, stosunek wydajności do odchylenia (RPD) został użyty jako standardowy sposób raportowania jakości modelu. Jest to stosunek odchylenia standardowego zmiennej do błędu standardowego przewidywania tej zmiennej przez dany model. Jednak jego systematyczne stosowanie zostało skrytykowane przez kilku autorów, ponieważ użycie odchylenia standardowego do reprezentowania rozrzutu zmiennej może być niewłaściwe w przypadku zbiorów danych z asymetrią rozkładów. Stosunek wydajności do rozstępu międzykwartylowego został wprowadzony przez Bellon-Maurel i in. (2010) w celu rozwiązania niektórych z tych problemów i uogólnienia RPD na zmienne o rozkładzie nienormalnym.
4.1.14 RPIQ
Stosunek wartości do rozstępu międzykwartylowego (ang. Ratio of Performance to Inter-Quartile) definiujemy następująco:
\[
RPIQ = \frac{IQ}{RMSE},
\tag{4.13}\]
gdzie \(IQ\) oznacza rozstęp kwartylowy zmiennej zależnej. Wywołujemy go przez funkcję rpiq.
4.1.15 CCC
Korelacyjny współczynnik zgodności (ang. Concordance Correlation Coefficient) mierzy zgodność pomiędzy wartościami predykcji i obserwowanymi. Definiujemy go w następujący sposób:
gdzie \(\mu_y,\mu_{\hat{y}}\) oznaczają średnią wartości obserwowanych i przewidywanych odpowiednio, \(\sigma_{y},\sigma_{\hat{y}}\) stanowią natomiast odchylenia standardowe tych wielkości. \(\rho\) jest współczynnikiem korelacji pomiędzy \(Y\) i \(\hat{Y}\). Wywołanie w R to funkcja ccc.
4.1.16 Podsumowanie miar dla modeli regresyjnych
Wśród miar dopasowania modelu można wyróżnić, te które mierzą zgodność pomiędzy wartościami obserwowanymi a przewidywanymi, wyrażone często pewnego rodzaju korelacjami (lub ich kwadratami), a interpretujemy je w ten sposób, że im wyższe wartości tych współczynników tym bardziej zgodne są predykcje z obserwacjami. Drugą duża grupę miar stanowią błędy (bezwzględne i względne), które mierzą w różny sposób różnice pomiędzy wartościami obserwowanymi i przewidywanymi. Jedne są bardziej odporne wartości odstające inne mniej, a wszystkie interpretujemy tak, że jeśli ich wartość jest mniejsza tym lepiej jest dopasowany model.
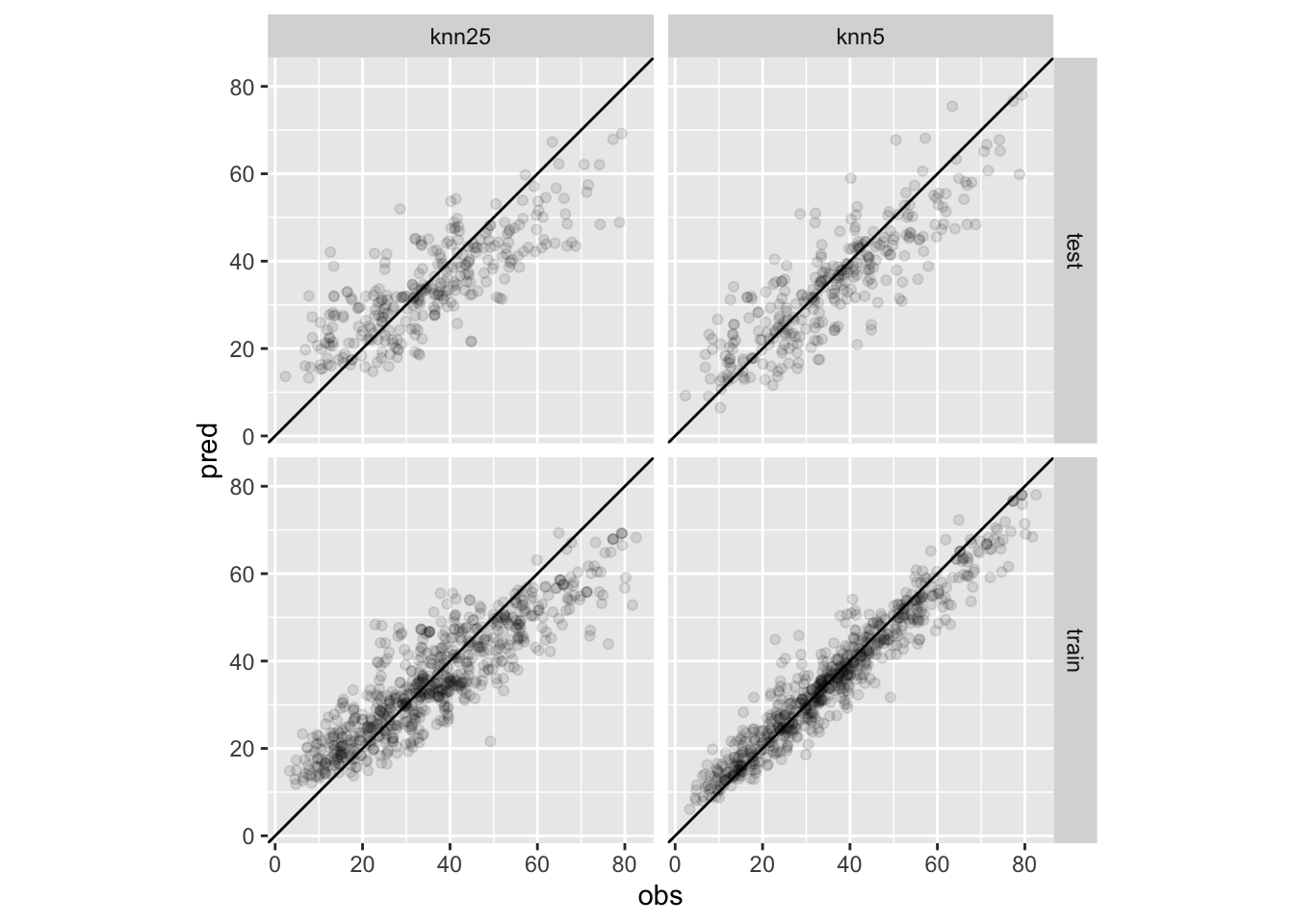
Przykład 4.1 Dla zilustrowania działania wspomnianych miar przeanalizujemy przykład modelu regresyjnego. Dla przykładu rozwiążemy zadanie przewidywania wytrzymałości betonu na podstawie jego parametrów. Do tego celu użyjemy danych ze zbioru concrete pakietu modeldata.(Yeh 2006)
# modelowania dokonamy bez szczególnego uwzględnienia charakteru zmiennych,# tuningowania i innych czynności, które będą nam towarzyszyć w normalnej# budowie modelu# podział danych na uczące i testoweset.seed(44)split<-initial_split(data =concrete, prop =0.7)train_data<-training(split)test_data<-testing(split)# określenie modeli, wybrałem kNNknn5<-nearest_neighbor(neighbors =5)|>set_engine('kknn')%>%set_mode('regression')knn25<-nearest_neighbor(neighbors =25)|>set_engine('kknn')%>%set_mode('regression')# uczymy modelefit5<-knn5|>fit(compressive_strength~., data =train_data)fit25<-knn25|>fit(compressive_strength~., data =train_data)# obliczamy predykcję dla obu modeli na obu zbiorachpred_train5<-predict(fit5, train_data)pred_train25<-predict(fit25, train_data)pred_test5<-predict(fit5, test_data)pred_test25<-predict(fit25, test_data)
# A tibble: 4 × 5
model sample .metric .estimator .estimate
<chr> <chr> <chr> <chr> <dbl>
1 pred25 test rsq standard 0.645
2 pred25 train rsq standard 0.787
3 pred5 test rsq standard 0.737
4 pred5 train rsq standard 0.929
Kod
# można też podsumować od razu kilkoma miarami# będa miary domyślne dla modelu regresyjnegobind_cols(obs =c(train_data$compressive_strength, test_data$compressive_strength), pred5 =c(pred_train5$.pred, pred_test5$.pred), pred25 =c(pred_train25$.pred, pred_test25$.pred))|>mutate(sample =rep(c("train", "test"), c(nrow(train_data), nrow(test_data))))|>pivot_longer(cols =c(pred5, pred25), names_to ="model", values_to ="pred")|>group_by(model, sample)|>metrics(truth =obs, estimate =pred)|>arrange(model, .metric)
# A tibble: 12 × 5
model sample .metric .estimator .estimate
<chr> <chr> <chr> <chr> <dbl>
1 pred25 test mae standard 7.73
2 pred25 train mae standard 6.50
3 pred25 test rmse standard 9.74
4 pred25 train rmse standard 8.22
5 pred25 test rsq standard 0.645
6 pred25 train rsq standard 0.787
7 pred5 test mae standard 6.33
8 pred5 train mae standard 3.45
9 pred5 test rmse standard 8.26
10 pred5 train rmse standard 4.68
11 pred5 test rsq standard 0.737
12 pred5 train rsq standard 0.929
Kod
# możemy zmienić parametry niektórych miarhuber_loss2<-metric_tweak("huber_loss2", huber_loss, delta =2)# można również wybrać jakie miary zostana użyteselected_metrics<-metric_set(ccc, rpd, mape, huber_loss2)bind_cols(obs =c(train_data$compressive_strength, test_data$compressive_strength), pred5 =c(pred_train5$.pred, pred_test5$.pred), pred25 =c(pred_train25$.pred, pred_test25$.pred))|>mutate(sample =rep(c("train", "test"), c(nrow(train_data), nrow(test_data))))|>pivot_longer(cols =c(pred5, pred25), names_to ="model", values_to ="pred")|>group_by(model, sample)|>selected_metrics(truth =obs, estimate =pred)|>arrange(model, sample)
# A tibble: 16 × 5
model sample .metric .estimator .estimate
<chr> <chr> <chr> <chr> <dbl>
1 pred25 test ccc standard 0.750
2 pred25 test rpd standard 1.64
3 pred25 test mape standard 30.9
4 pred25 test huber_loss2 standard 13.6
5 pred25 train ccc standard 0.851
6 pred25 train rpd standard 2.07
7 pred25 train mape standard 24.8
8 pred25 train huber_loss2 standard 11.1
9 pred5 test ccc standard 0.844
10 pred5 test rpd standard 1.93
11 pred5 test mape standard 24.1
12 pred5 test huber_loss2 standard 10.8
13 pred5 train ccc standard 0.958
14 pred5 train rpd standard 3.64
15 pred5 train mape standard 12.8
16 pred5 train huber_loss2 standard 5.19
Jak to zostało wspomniane wcześniej w modelach klasyfikacyjnych można podzielić miary dopasowania na te, które dotyczą modeli z binarną zmienną wynikową i ze zmienna wielostanową. Miary można też podzielić na te, które zależą od prawdopodobieństwa poszczególnych stanów i te, które zależą tylko od klasyfikacji wynikowej.
Do wyliczenia miar probabilistycznych konieczne jest wyliczenie predykcji z prawdopodobieństwami poszczególnych stanów. Aby uzyskać taki efekt wystarczy w predykcji modelu użyć parametru type = "prob". W przykładzie podsumowującym miary będzie to zilustrowane.
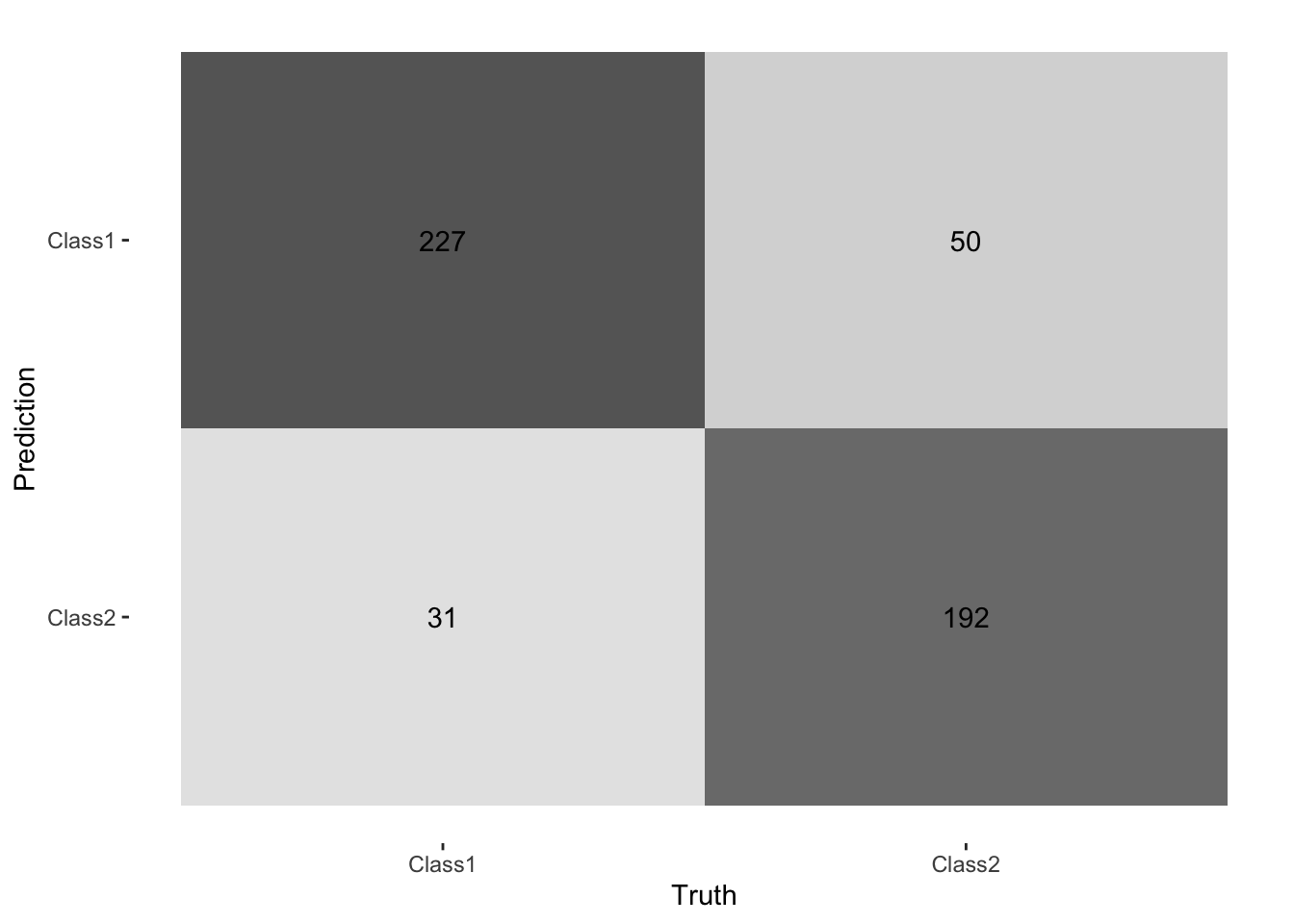
Na to, aby przybliżyć miary dopasowania opartych o prawdopodobieństwa stanów, konieczne jest wprowadzenie pojęcia macierzy klasyfikacji (ang. confusion matrix). Można je stosować zarówno do klasyfikacji dwustanowej, jak i wielostanowej. Użyjemy przykładu binarnego aby zilustrować szczegóły tej macierzy.
Kod
# import danych do przykładudata(two_class_example)# kilka pierwszych wierszy wyników predykcjihead(two_class_example)
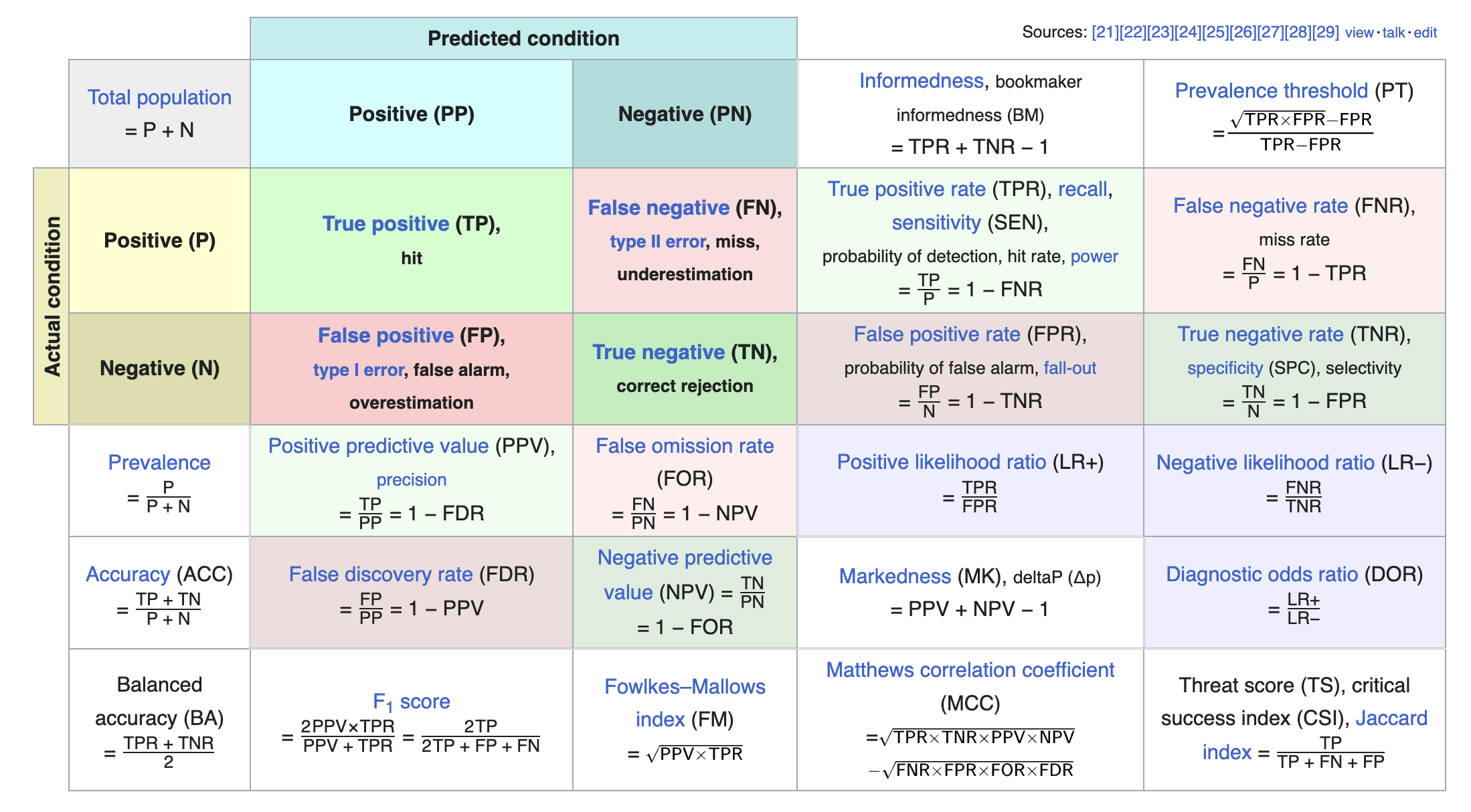
Aby przedstawić poszczególne miary na podstawie macierzy klasyfikacji wystarczy przywołać ilustrację z Wikipedii, która w genialny sposób podsumowuje większość miar.
Rys. 4.3: Macierz klasyfikacji
Na podstawie tej macierzy możemy ocenić dopasowanie modelu za pomocą:
accuacy - informuje o odsetku poprawnie zaklasyfikowanych obserwacji. Jest bardzo powszechnie stosowaną miarą dopasowania modelu choć ma jedną poważną wadę. Mianowicie w przypadku modeli dla danych z wyraźną dysproporcją jednej z klas (powiedzmy jedna stanowi 95% wszystkich obserwacji), może się zdarzyć sytuacja, że nawet bezsensowny model, czyli taki, który zawsze wskazuje tą właśnie wartość, będzie miał accuracy na poziomie 95%.
kappa - miara podobna miarą do accuracy i jest bardzo przydatna, gdy jedna lub więcej klas dominuje. Definiujemy ją następująco \(\kappa = \frac{p_o-p_e}{1-p_e}\), gdzie \(p_o,p_e\) są odpowiednio zgodnością obserwowaną i oczekiwaną. Zgodność obserwowana jest odsetkiem obserwacji poprawnie zaklasyfikowanych, a oczekiwana to zgodność wynikająca z przypadku.
precision - oznaczana też czasem jako PPV (ang. Positive Predictive Value) oznacza stosunek poprawnie zaklasyfikowanych wartości true positive (TP) do wszystkich przewidywanych wartości pozytywnych (ang. positive predictive).
recall - nazywany także sensitivity lub True Positive Rate (TPR), który stanowi stosunek true positive do wszystkich przypadków positive.
specificity - nazywane również True Negative Rate (TNR), wyraża się stosunkiem pozycji true negative do wszystkich obserwacji negative.
negative predictive value (NPV) - oznaczane czasem też jako false omission rate jest liczone jako stosunek false negative do wszystkich przewidywanych negative (PN).
\(F_1\) - jest miarą zdefiniowaną jako \(\frac{2PPV*TPR}{PPV+TPR}\).
MCC - Mathews Correlation Coeficient - jest zdefiniowany jako \(\sqrt{TPR*TNR*PPV*NPV}-\sqrt{FNR*FPR*NPV*FDR}\). Istnieje również odmiana tej miary dla przypadku wielostanowej zmiennej wynikowej.
balanced accuracy - liczona jako średnia sensitivity i specificity.
detection prevalence - zdefiniowana jako stosunek poprawnie przewidywanych obserwacji do liczby wszystkich przewidywanych wartości.
J index - metryka Youden’a definiowana jako sensitivity + specificity -1, często jest wykorzystywana do określenia poziomu odcięcia prawdopodobieństwa zdarzenia wyróżnionego (ang. threshold).
koszt niepoprawnej klasyfikacji - czasami niektóre błędy klasyfikacji są mniej kosztowne z punktu widzenie badacza, a inne bardziej. Wówczas można przypisać koszty błędnych klasyfikacji do poszczególnych klas, nakładając kary za błędne przypisane do innej klasy i w ten sposób zapobiegać takim sytuacjom.
średnia logarytmu funkcji straty (ang. log loss) - określana też w literaturze jako binary cross-entropy dla przypadku zmiennej wynikowej dwustanowej i multilevel cross-entropy albo categorical cross-entropy w przypadku wielostanowej klasyfikacji. Definiuje się ją następująco:
\[
\mathcal{L} = \frac1n\sum_{i=1}^n\left[y_i\log(\hat{y}_i)+(1-y_i)\log(1-\hat{y}_i)\right],
\tag{4.14}\] gdzie \(y_i\) jest indykatorem klasy wyróżnionej dla \(i\)-tej obserwacji, a \(\hat{y}_i\) prawdopodobieństwem wyróżnionego stanu \(i\)-tej obserwacji. Piękną rzeczą w tej definicji jest to, że jest ona ściśle związana z teorią informacji: log-loss jest entropią krzyżową pomiędzy rozkładem prawdziwych etykiet a przewidywaniami i jest bardzo blisko związana z tym, co jest znane jako entropia względna lub rozbieżność Kullbacka-Leiblera. Entropia mierzy nieprzewidywalność czegoś. Entropia krzyżowa zawiera entropię prawdziwego rozkładu plus dodatkową nieprzewidywalność, gdy ktoś zakłada inny rozkład niż prawdziwy. Tak więc log-loss jest miarą z teorii informacji pozwalającą zmierzyć “dodatkowy szum”, który powstaje w wyniku użycia predykcji w przeciwieństwie do prawdziwych etykiet. Minimalizując entropię krzyżową, maksymalizujemy dokładność klasyfikatora. Log-loss, czyli strata logarytmiczna, wnika w najdrobniejsze szczegóły działania klasyfikatora.
Prawdopodobieństwo można rozumieć jako miernik zaufania. Jeśli prawdziwa etykieta to 0, ale klasyfikator ocenia, że należy ona do klasy 1 z prawdopodobieństwem 0,51, to pomimo tego, że klasyfikator popełniłby błąd, jest to niewielki błąd, ponieważ prawdopodobieństwo jest bardzo bliskie granicy decyzji 0,5. Log-loss jest subtelną miarą dokładności.
Należy pamiętać, że większość wspomnianych miar opiera się na wartościach z macierzy klasyfikacji. Przy czym aby obserwacje zaklasyfikować do jednej z klas należy przyjąć pewien punkt odcięcia (threshold) prawdopodobieństwa, od którego przewidywana wartość będzie przyjmowała stan “1”. Domyślnie w wielu modelach ten punkt jest ustalony na poziomie 0,5. Nie jest on jednak optymalny ze względu na jakość klasyfikacji. Zmieniając ten próg otrzymamy różne wartości specificity, sensitivity, precision, recall, itd. Istnieją kryteria doboru progu odcięcia, np. oparte na wartości Youdena, F1, średniej geometrycznej itp. W przykładzie prezentowanym poniżej pokażemy zastosowanie dwóch z tych technik. Bez względu na przyjęty poziom odcięcia istnieją również miary i wykresy, które pozwalają zilustrować jakość modelu. Należą do nich:
wykresy:
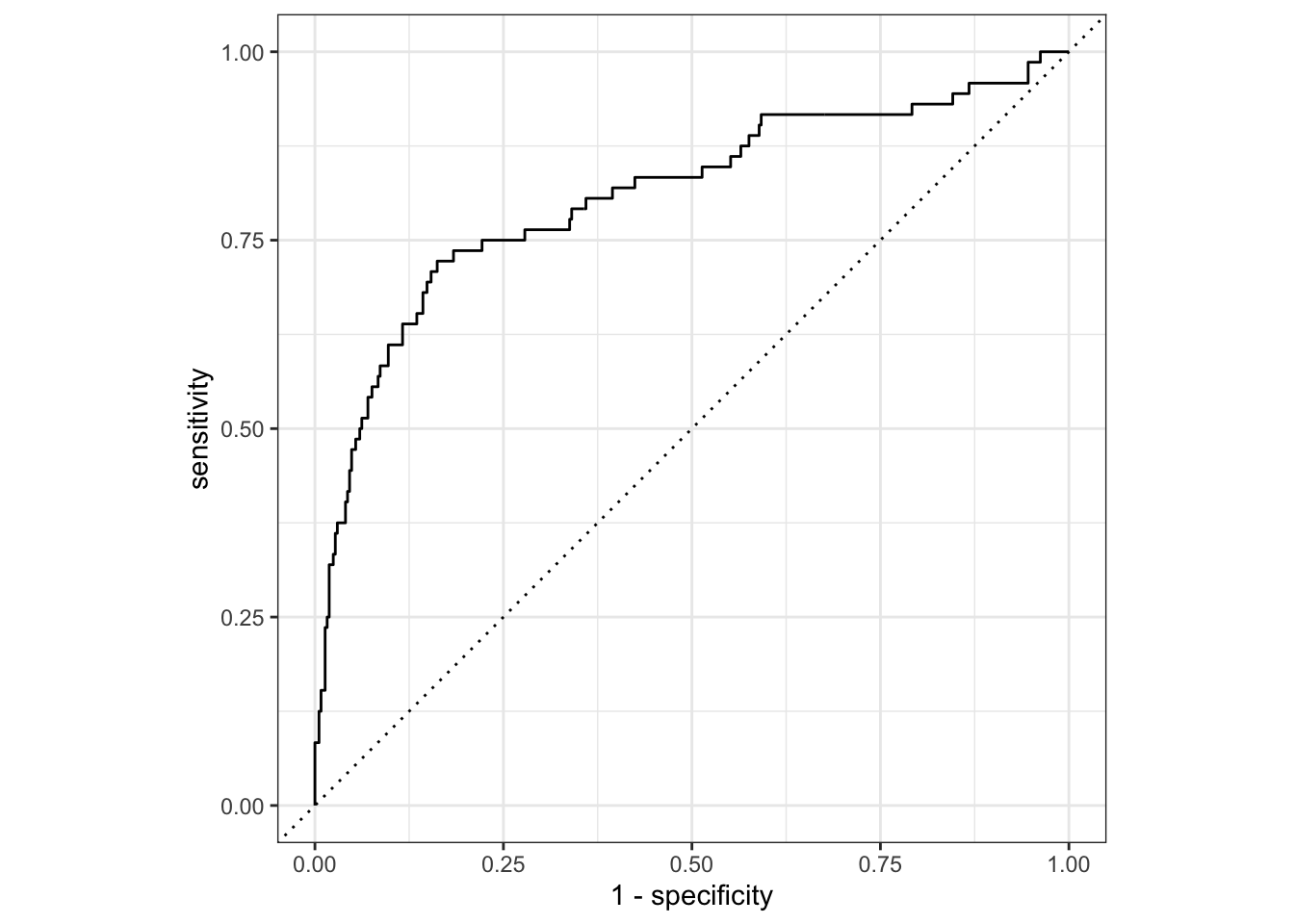
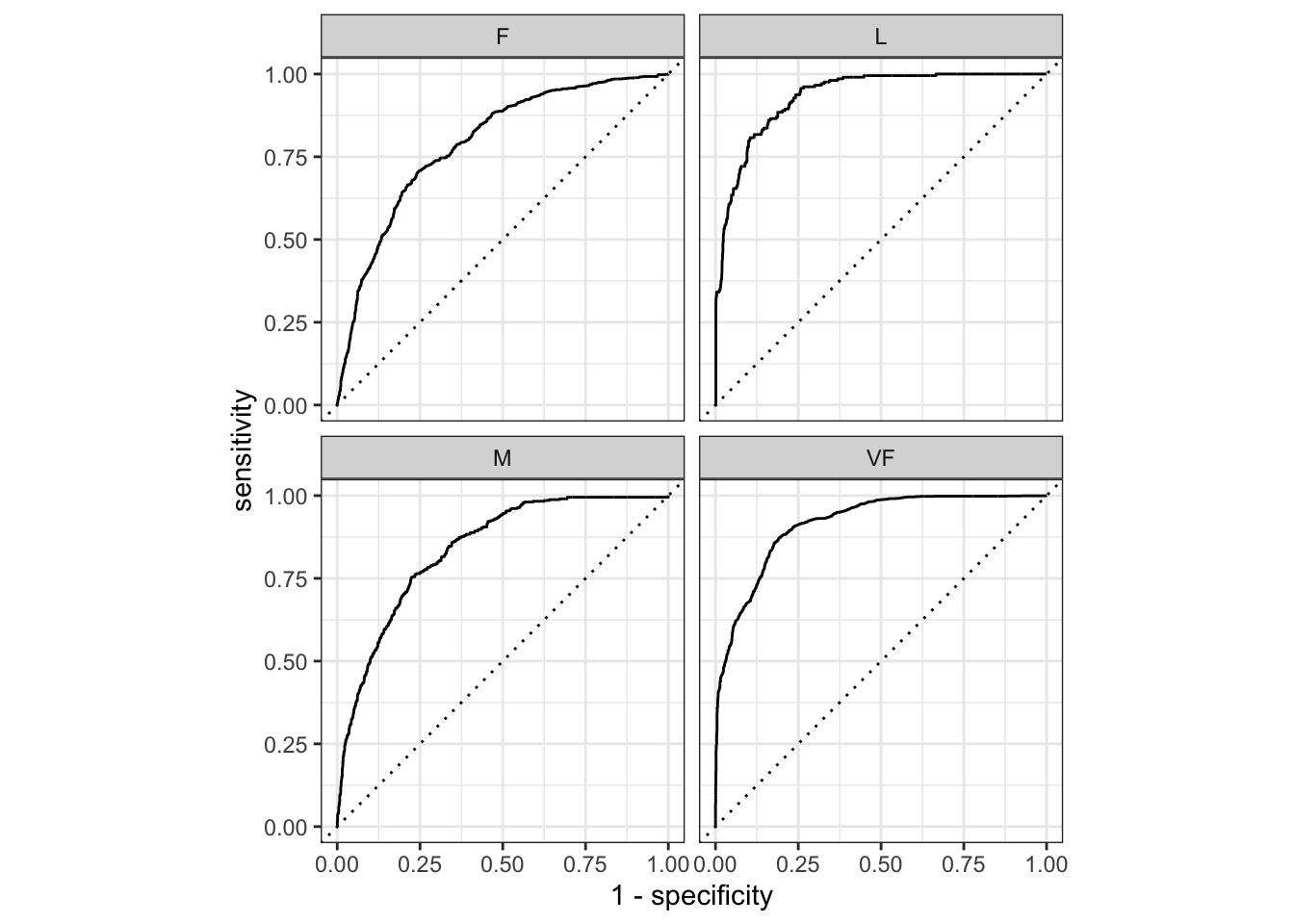
ROC - Receiver Operating Characteristic - krzywa, która przedstawia kompromis pomiędzy sensitivity i specificity dla różnych poziomów odcięcia. Ta egzotycznie brzmiąca nazwa wywodzi się z analizy sygnałów radiowych i została spopularyzowana w 1978 roku przez Charlesa Metza w artykule “Basic Principles of ROC Analysis”. Krzywa ROC pokazuje czułość klasyfikatora poprzez wykreślenie TPR do FPR. Innymi słowy, pokazuje ona, ile poprawnych pozytywnych klasyfikacji można uzyskać, gdy dopuszcza się coraz więcej fałszywych pozytywów. Idealny klasyfikator, który nie popełnia żadnych błędów, osiągnąłby natychmiast 100% wskaźnik prawdziwych pozytywów, bez żadnych fałszywych pozytywów - w praktyce prawie nigdy się to nie zdarza.
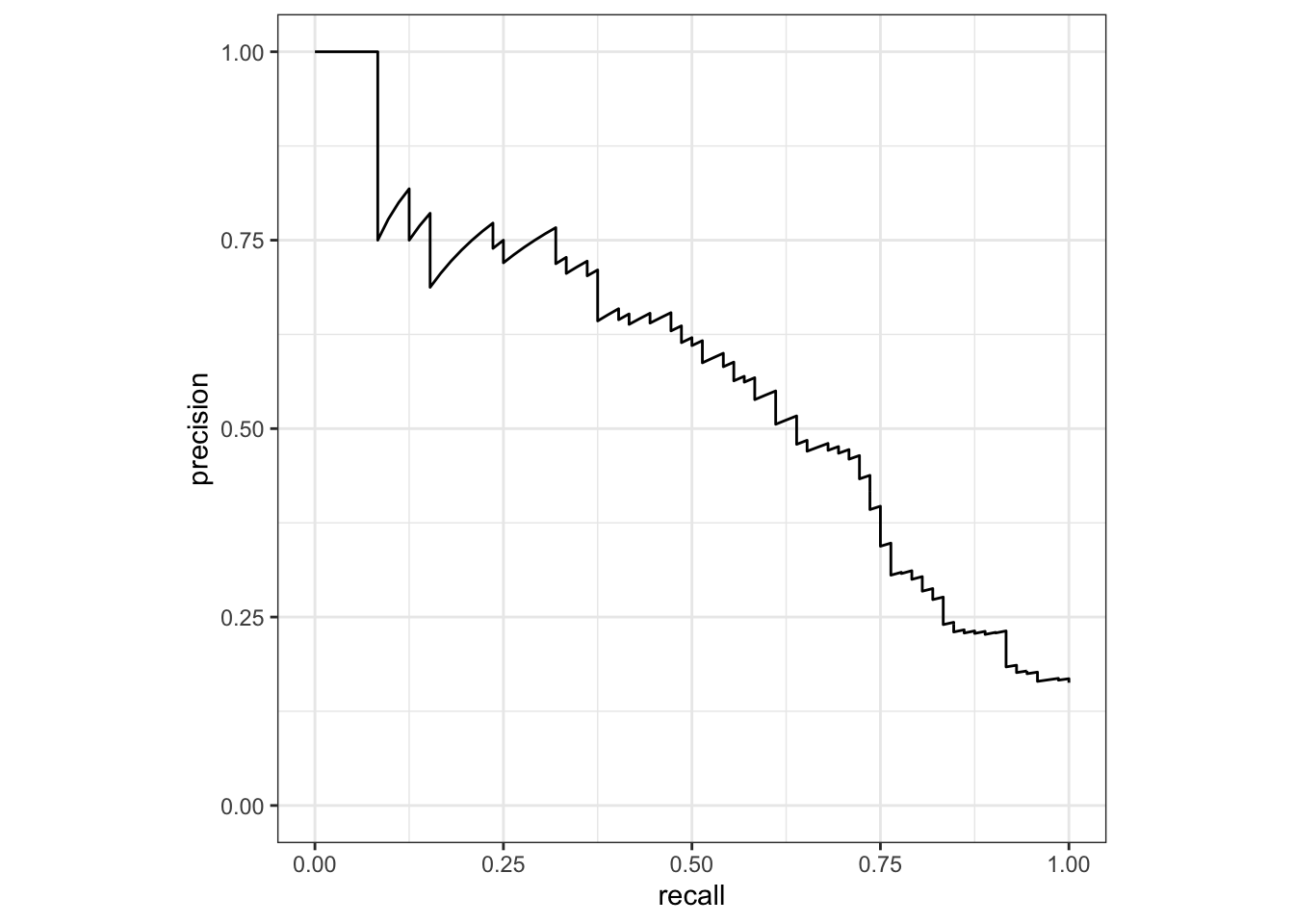
PRC - Precision-Recall Curve - krzywa, która pokazuje kompromis pomiędzy precision i recall. Precision i recall to tak naprawdę dwie metryki. Jednak często są one używane razem. Precision odpowiada na pytanie: “Z elementów, które klasyfikator przewidział jako pozytywnych ile jest rzeczywiście pozytywnych?”. Natomiast recall odpowiada na pytanie: “Spośród wszystkich elementów, które są pozytywne, ile zostało przewidzianych jako takie przez klasyfikator?”. Krzywa PRC to po prostu wykres z wartościami Precision na osi y i Recall na osi x. Innymi słowy, krzywa PRC zawiera TP/(TP+FP) na osi y oraz TP/(TP+FN) na osi x.
Krzywa wzrostu (ang. Gain Curve) - to krzywa przedstawiająca stosunek skumulowanej liczby pozytywnych (wyróżnionych) obserwacji w decylu do całkowitej liczby pozytywnych obserwacji w danych.
Krzywa wyniesienia (ang. Lift Curve) - jest stosunkiem liczby pozytywnych obserwacji w \(i\)-tym decylu na podstawie modelu do oczekiwanej liczby pozytywnych obserwacji należących do \(i\)-tego decyla na podstawie modelu losowego.
miary:
AUC - Area Under ROC Curve - mierzy pole pod krzywą ROC. Krzywa ROC nie jest pojedynczą liczbą ale całą krzywą. Dostarcza ona szczegółowych informacji o zachowaniu klasyfikatora, ale trudno jest szybko porównać wiele krzywych ROC ze sobą. W szczególności, jeśli ktoś chciałby zastosować jakiś automatyczny mechanizm tuningowania hiperparametrów, maszyna potrzebowałaby wymiernego wyniku zamiast wykresu, który wymaga wizualnej inspekcji. AUC jest jednym ze sposobów podsumowania krzywej ROC w jedną liczbę, tak aby można było ją łatwo i automatycznie porównać. Dobra krzywa ROC ma dużo miejsca pod sobą (ponieważ prawdziwy wskaźnik pozytywny bardzo szybko wzrasta do 100%). Zła krzywa ROC obejmuje bardzo mały obszar. Tak więc wysokie AUC jest sygnałem dobrego dopasowania modelu.
PRAUC - Area Under Precision-Racall Curve - mierzy pole pod krzywą P-R.
Pole pod krzywą wzrosu.
Pole pod krzywą wyniesienia.
Przykład 4.2 Tym razem zbudujemy model klasyfikacyjny dla zmiennej wynikowej dwustanowej. Dane pochodzą ze zbioru attrition pakietu modeldata. Naszym zadaniem będzie zbudować modeli przewidujący odejścia z pracy.
# podział zbioru na uczący i testowyset.seed(44)split<-initial_split(attrition, prop =0.7, strata ="Attrition")train_data<-training(split)test_data<-testing(split)# określam modellr_mod<-logistic_reg()|>set_engine("glm")|>set_mode("classification")# uczę modellr_fit<-lr_mod|>fit(Attrition~., data =train_data)# podsumowanie modelulr_fit|>tidy()
Teraz korzystając z różnych miar podsumujemy dopasowanie modelu.
Kod
# predykcja z modelu przyjmując threshold = 0.5pred_class<-predict(lr_fit, new_data =test_data)# predkcja (prawdopodobieństwa klas)pred_prob<-predict(lr_fit, new_data =test_data, type ="prob")# ale można też takpred<-augment(lr_fit, test_data)|>select(Attrition, .pred_class, .pred_No, .pred_Yes)# macierz klasyfikacjicm<-pred|>conf_mat(truth =Attrition, estimate =.pred_class)cm
library(probably)# ustalam zakres thresholdthresholds<-seq(0.01,1, by =0.01)# poszukuje najlepszego progu ze względu kryterium Youden'apred|>threshold_perf(Attrition, .pred_Yes, thresholds, event_level ="second")|>pivot_wider(names_from =.metric, values_from =.estimate)|>arrange(-j_index)
4.2.1 Miary dopasowania dla modeli ze zmienną wynikową wieloklasową
Wspomniane zostało, że miary dedykowane dla modeli binarnych można również wykorzystać do modeli ze zmienną zależną wielostanową. Oczywiście wówczas trzeba użyć pewnego rodzaju uśredniania. Implementacje wieloklasowe wykorzystują mikro, makro i makro-ważone uśrednianie, a niektóre metryki mają swoje własne wyspecjalizowane implementacje wieloklasowe.
4.2.1.1 Makro uśrednianie
Makro uśrednianie redukuje wieloklasowe predykcje do wielu zestawów przewidywań binarnych. Oblicza się odpowiednią metrykę dla każdego z przypadków binarnych, a następnie uśrednia wyniki. Jako przykład, rozważmy precision. W przypadku wieloklasowym, jeśli istnieją poziomy A, B, C i D, makro uśrednianie redukuje problem do wielu porównań jeden do jednego. Kolumny truth i estimate są rekodowane tak, że jedynymi dwoma poziomami są A i inne, a następnie precision jest obliczana w oparciu o te rekodowane kolumny, przy czym A jest “wyróżnioną” kolumną. Proces ten jest powtarzany dla pozostałych 3 poziomów, aby uzyskać łącznie 4 wartości precyzji. Wyniki są następnie uśredniane.
Formuła dla \(k\) klas wynikowych prezentuje się następująco:
gdzie \(Pr_i\) oznacza precision dla \(i\)-tej klasy.
4.2.1.2 Makro-ważone uśrednianie
Makro-ważone uśrednianie jest co do zasady podobne do metody makro uśredniania, z tą jednak zmianą, że wagi poszczególnych czynników w średniej zależą od liczności tych klas, co sprawia, że miara ta jest bardziej optymalna w przypadku wyraźnych dysproporcji zmiennej wynikowej. Formalnie obliczamy to wg reguły:
gdzie \(\#Obs_i\) oznacza liczbę obserwacji w grupie \(i\)-tej, a \(n\) jest liczebnością całego zbioru.
4.2.1.3 Mikro uśrednianie
Mikro uśrednianie traktuje cały zestaw danych jako jeden wynik zbiorczy i oblicza jedną metrykę zamiast \(k\) metryk, które są uśredniane. Dla precision działa to poprzez obliczenie wszystkich true positive wyników dla każdej klasy i użycie tego jako licznika, a następnie obliczenie wszystkich true positive i false positive wyników dla każdej klasy i użycie tego jako mianownika.
W tym przypadku, zamiast klas o równej wadze, mamy obserwacje z równą wagą. Dzięki temu klasy z największą liczbą obserwacji mają największy wpływ na wynik.
Przykład 4.3 Przykład użycia miar dopasowania modelu dla zmiennych wynikowych wieloklasowych.
Kod
# predykcja wykonana dla sprawdzianu krzyżowego# bedzie nas interesować tylko wynik pierwszego foldahead(hpc_cv)
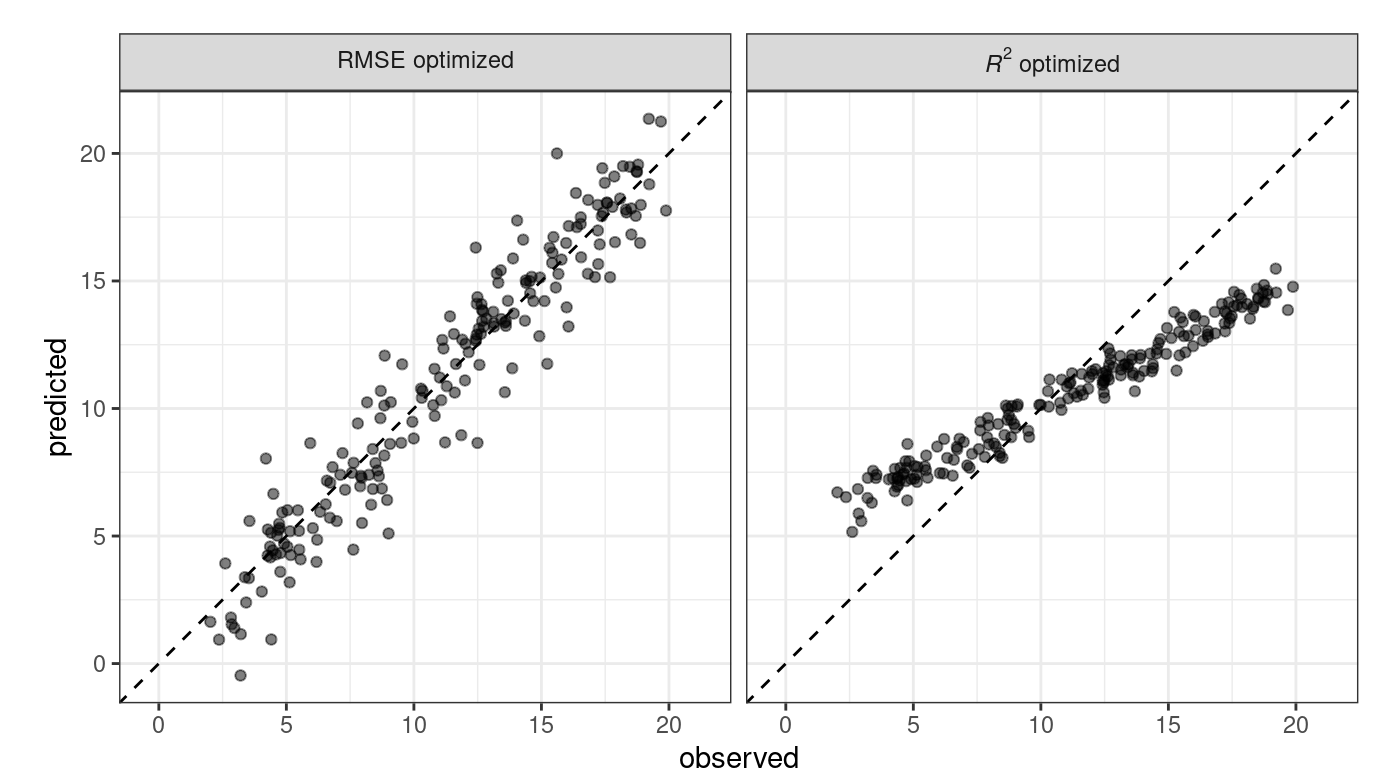
Stosując jedna miarę dopasowania modelu (bez względu na to czy jest to model klasyfikacyjny czy regresyjny) możemy nie otrzymać optymalnego modelu. Ze względu na definicje miary dopasowania różnią się pomiędzy sobą eksponując nieco inne aspekty. To powoduje, że może się zdarzyć sytuacja, że optymalny model ze względu na \(R^2\) będzie się różnił (nawet znacznie) od modelu optymalizowanego z użyciem RMSE (patrz Rys. 4.4).
Rys. 4.4: Porównanie jakości modeli z wykorzystaniem różnych miar
Model zoptymalizowany pod kątem RMSE ma większą zmienność, ale ma stosunkowo jednolitą dokładność w całym zakresie wyników. Prawy panel pokazuje, że istnieje silniejsza korelacja między wartościami obserwowanymi i przewidywanymi, ale model ten słabo radzi sobie w przewidywaniu skrajnych wartości. Na marginesie można dodać, że jeśli model miałby być stosowany do predykcji (co zdarza się bardzo często w modelach ML), to miara RMSE jest lepsza, natomiast gdy interesują nas poszczególne efekty modelu regresji, wówczas \(R^2\) jest częściej stosowaną miarą oceny dopasowania modelu.
Podobny przykład można przytoczyć również dla modeli klasyfikacyjnych.
Ocena skuteczności danego modelu zależy od tego, do czego będzie on wykorzystywany. Model inferencyjny jest używany przede wszystkim do zrozumienia związków i zazwyczaj kładzie nacisk na wybór (i ważność) rozkładów probabilistycznych i innych cech generatywnych, które definiują model. Dla modelu używanego głównie do przewidywania, w przeciwieństwie do tego, siła predykcyjna ma podstawowe znaczenie, a inne obawy dotyczące podstawowych właściwości statystycznych mogą być mniej ważne. Siła predykcyjna jest zwykle określana przez to, jak blisko nasze przewidywania zbliżają się do obserwowanych danych, tj. wierność przewidywań modelu do rzeczywistych wyników. W tym rozdziale skupiono się na funkcjach, które można wykorzystać do pomiaru siły predykcji. Jednakże naszą radą dla osób opracowujących modele inferencyjne jest stosowanie tych technik nawet wtedy, gdy model nie będzie używany z głównym celem przewidywania.
Od dawna problemem w praktyce statystyki inferencyjnej jest to, że skupiając się wyłącznie na wnioskowaniu, trudno jest ocenić wiarygodność modelu. Na przykład, rozważ dane dotyczące choroby Alzheimera z Craig-Schapiro i in. (2011), gdzie 333 pacjentów było badanych w celu określenia czynników wpływających na upośledzenie funkcji poznawczych. W analizie można uwzględnić znane czynniki ryzyka i zbudować model regresji logistycznej, w którym wynik jest binarny (upośledzony/nieupośledzony). Rozważmy predyktory wieku, płci i genotypu apolipoproteiny E. Ta ostatnia jest zmienną kategoryczną zawierającą sześć możliwych kombinacji trzech głównych wariantów tego genu. Wiadomym jest, że apolipoproteina E ma związek z demencją (Kim, Basak, i Holtzman 2009).
Powierzchowne, ale nierzadkie podejście do tej analizy polegałoby na dopasowaniu dużego modelu z głównymi efektami i interakcjami, a następnie zastosowaniu testów statystycznych w celu znalezienia minimalnego zestawu efektów modelu, które są statystycznie istotne na jakimś wcześniej zdefiniowanym poziomie. Jeśli użyto pełnego modelu z trzema czynnikami i ich dwu- i trójstronnymi interakcjami, wstępnym etapem byłoby przetestowanie interakcji przy użyciu sekwencyjnych testów ilorazu prawdopodobieństwa (Hosmer i Lemeshow 2000). Przejdźmy przez takie podejście dla przykładowych danych dotyczących choroby Alzheimera:
Porównując model ze wszystkimi interakcjami dwukierunkowymi z modelem z dodatkową interakcją trójkierunkową, testy ilorazu wiarygodności dają wartość \(p\) równą 0,888. Oznacza to, że nie ma dowodów na to, że cztery dodatkowe terminy modelu związane z interakcją trójkierunkową wyjaśniają wystarczająco dużo zmienności w danych, aby zachować je w modelu.
Następnie, dwukierunkowe interakcje są podobnie oceniane w stosunku do modelu bez interakcji. Wartość \(p\) wynosi tutaj 0,0382. Biorąc pod uwagę niewielki rozmiar próbki, byłoby rozsądnie stwierdzić, że istnieją dowody na to, że niektóre z 10 możliwych dwukierunkowych interakcji są ważne dla modelu.
Na tej podstawie wyciągnęlibyśmy pewne wnioski z uzyskanych wyników. Interakcje te byłyby szczególnie ważne do omówienia, ponieważ mogą one zapoczątkować interesujące fizjologiczne lub neurologiczne hipotezy, które należy dalej badać.
Chociaż jest to strategia uproszczona, jest ona powszechna zarówno w praktyce, jak i w literaturze. Jest to szczególnie częste, jeśli praktykujący ma ograniczone formalne wykształcenie w zakresie analizy danych.
Jedną z brakujących informacji w tym podejściu jest to, jak blisko model ten pasuje do rzeczywistych danych. Stosując metody resamplingu, omówione w rozdziale 10, możemy oszacować dokładność tego modelu na około 73,4%. Dokładność jest często słabą miarą wydajności modelu; używamy jej tutaj, ponieważ jest powszechnie rozumiana. Jeśli model ma 73,4% dokładności w stosunku do danych, to czy powinniśmy zaufać wnioskom, które produkuje? Moglibyśmy tak myśleć, dopóki nie zdamy sobie sprawy, że wskaźnik bazowy nieupośledzonych pacjentów w danych wynosi 72,7%. Oznacza to, że pomimo naszej analizy statystycznej, model dwuczynnikowy okazuje się być tylko o 0,8% lepszy od prostej heurystyki, która zawsze przewiduje, że pacjenci nie są upośledzeni, niezależnie od obserwowanych danych.
3.4 Evaluating Forecast Accuracy | Forecasting: Principles and Practice (2nd Ed). b.d.
Bellon-Maurel, Véronique, Elvira Fernandez-Ahumada, Bernard Palagos, Jean-Michel Roger, i Alex McBratney. 2010. „Critical Review of Chemometric Indicators Commonly Used for Assessing the Quality of the Prediction of Soil Attributes by NIR Spectroscopy”. TrAC Trends in Analytical Chemistry 29 (9): 1073–81. https://doi.org/10.1016/j.trac.2010.05.006.
Craig-Schapiro, Rebecca, Max Kuhn, Chengjie Xiong, Eve H. Pickering, Jingxia Liu, Thomas P. Misko, Richard J. Perrin, i in. 2011. „Multiplexed Immunoassay Panel Identifies Novel CSF Biomarkers for Alzheimer’s Disease Diagnosis and Prognosis”. Zredagowane przez Ashley I. Bush. PLoS ONE 6 (4): e18850. https://doi.org/10.1371/journal.pone.0018850.
Hyndman, Rob J., i Anne B. Koehler. 2006. „Another Look at Measures of Forecast Accuracy”. International Journal of Forecasting 22 (4): 679–88. https://doi.org/10.1016/j.ijforecast.2006.03.001.
Kim, Jungsu, Jacob M. Basak, i David M. Holtzman. 2009. „The Role of Apolipoprotein E in Alzheimer’s Disease”. Neuron 63 (3): 287–303. https://doi.org/10.1016/j.neuron.2009.06.026.
Kvalseth, Tarald O. 1985. „Cautionary Note about R2”. The American Statistician 39 (4): 279–85. https://doi.org/10.2307/2683704.
Yeh, I.-Cheng. 2006. „Analysis of Strength of Concrete Using Design of Experiments and Neural Networks”. Journal of Materials in Civil Engineering 18 (4): 597–604. https://doi.org/10.1061/(ASCE)0899-1561(2006)18:4(597).