Modele są narzędziami matematycznymi, które mogą opisać system i uchwycić pewne wzorce w danych, które są im przekazywane. Modele mogą być wykorzystywane do różnych celów, w tym do przewidywania przyszłych zdarzeń, określania, czy istnieje różnica między kilkoma grupami, wspomagania wizualizacji opartej na mapach, odkrywania nowych wzorców w danych, które mogą być dalej badane, i innych. Użyteczność modelu zależy od jego zdolności do redukcji, czyli sprowadzenia złożonych relacji do prostszych pojęć. Wpływy podstawowych czynników mogą być uchwycone matematycznie w użyteczny sposób, np. w relacji, która może być wyrażona jako równanie.
Od początku XXI wieku modele matematyczne stały się wszechobecne w naszym codziennym życiu, zarówno w sposób oczywisty, jak i bardziej subtelny. Typowy dzień dla wielu osób może obejmować sprawdzenie pogody, aby zobaczyć, kiedy jest dobry czas na spacer z psem, zamówienie produktu na stronie internetowej, napisanie wiadomości tekstowej do przyjaciela i jej autokorektę oraz sprawdzenie poczty elektronicznej. W każdym z tych przypadków istnieje duża szansa, że w grę wchodził jakiś rodzaj modelu. W niektórych przypadkach wkład modelu może być łatwo zauważalny (“Możesz być również zainteresowany zakupem produktu X”), podczas gdy w innych przypadkach wpływ może polegać na braku czegoś (np. spamu). Modele są wykorzystywane do wyboru ubrań, które mogą się spodobać klientowi, do identyfikacji substancji, która powinna być oceniana jako kandydat na lek, a nawet mogą być mechanizmem, którego używa nieuczciwa firma, aby uniknąć odkrycia samochodów, które nadmiernie zanieczyszczają środowisko.
2.1 Typy modeli
Zanim przejdziemy dalej, opiszmy taksonomię rodzajów modeli, pogrupowanych według przeznaczenia. Taksonomia ta informuje zarówno o tym, jak model jest używany, jak i o wielu aspektach tego, jak model może być tworzony lub oceniany. Chociaż lista ta nie jest wyczerpująca, większość modeli należy do przynajmniej jednej z tych kategorii:
2.1.1 Modele opisowe
Celem modelu opisowego jest opis lub zilustrowanie pewnych cech danych. Analiza może nie mieć innego celu niż wizualne podkreślenie jakiegoś trendu lub artefaktu (lub defektu) w danych.
Na przykład, pomiary RNA na dużą skalę są możliwe od pewnego czasu przy użyciu mikromacierzy. Wczesne metody laboratoryjne umieszczały próbkę biologiczną na małym mikrochipie. Bardzo małe miejsca na chipie mogą mierzyć sygnał oparty na bogactwie specyficznej sekwencji RNA. Chip zawierałby tysiące (lub więcej) wyników, z których każdy byłby kwantyfikacją RNA związanego z procesem biologicznym. Jednakże na chipie mogłyby wystąpić problemy z jakością, które mogłyby prowadzić do słabych wyników. Na przykład, odcisk palca przypadkowo pozostawiony na części chipa mógłby spowodować niedokładne pomiary podczas skanowania.
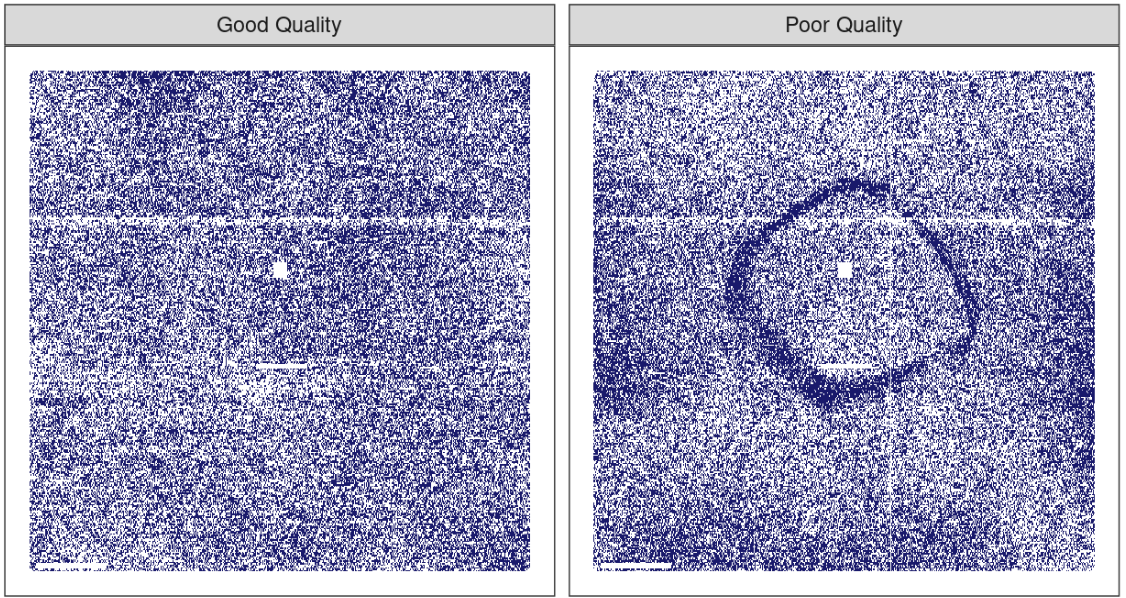
Rys. 2.1: Ocena jakości odczytów z mikroczipa
Wczesną metodą oceny takich zagadnień były modele na poziomie sondy, czyli PLM (Bolstad 2004). Tworzono model statystyczny, który uwzględniał pewne różnice w danych, takie jak chip, sekwencja RNA, typ sekwencji i tak dalej. Jeśli w danych występowałyby inne, nieznane czynniki, to efekty te zostałyby uchwycone w resztach modelu. Gdy reszty zostały wykreślone według ich lokalizacji na chipie, dobrej jakości chip nie wykazywałby żadnych wzorców. W przypadku wystąpienia problemu, pewien rodzaj wzorca przestrzennego byłby dostrzegalny. Często typ wzorca sugerowałby problem (np. odcisk palca) oraz możliwe rozwiązanie (wytarcie chipa i ponowne skanowanie, powtórzenie próbki, itp.) Rysunek 2.1 pokazuje zastosowanie tej metody dla dwóch mikromacierzy (Gentleman i in. 2005). Obrazy pokazują dwie różne wartości kolorystyczne; obszary, które są ciemniejsze to miejsca, gdzie intensywność sygnału była większa niż oczekuje model, podczas gdy jaśniejszy kolor pokazuje wartości niższe niż oczekiwane. Lewy panel pokazuje w miarę losowy wzór, podczas gdy prawy panel wykazuje niepożądany artefakt w środku chipa.
2.1.2 Modele do wnioskowania
Celem modelu inferencyjnego jest podjęcie decyzji dotyczącej pytania badawczego lub sprawdzenie określonej hipotezy, podobnie jak w przypadku testów statystycznych. Model inferencyjny zaczyna się od wcześniej zdefiniowanego przypuszczenia lub pomysłu na temat populacji i tworzy wniosek statystyczny, taki jak szacunek przedziału lub odrzucenie hipotezy.
Na przykład, celem badania klinicznego może być potwierdzenie, że nowa terapia pozwala wydłużyć życie w porównaniu z istniejącą terapią lub brakiem leczenia. Jeśli kliniczny punkt końcowy dotyczyłby przeżycia pacjenta, hipoteza zerowa mogłaby brzmieć, że nowa terapia ma równą lub niższą medianę czasu przeżycia, a hipoteza alternatywna, że nowa terapia ma wyższą medianę czasu przeżycia. Jeśli ta próba byłaby oceniana przy użyciu tradycyjnego testowania istotności hipotezy zerowej poprzez modelowanie, testowanie istotności dałoby wartość \(p\) przy użyciu jakiejś wcześniej zdefiniowanej metodologii opartej na zestawie założeń. Małe wartości dla wartości \(p\) w wynikach modelu wskazywałyby na istnienie przesłanek, że nowa terapia pomaga pacjentom żyć dłużej. Duże wartości \(p\) w wynikach modelu wskazywałyby, że nie udało się wykazać takiej różnicy; ten brak przesłanek mógłby wynikać z wielu powodów, w tym z tego, że terapia nie działa.
Jakie są ważne aspekty tego typu analizy? Techniki modelowania inferencyjnego zazwyczaj dają pewien rodzaj danych wyjściowych o charakterze probabilistycznym, takich jak wartość \(p\), przedział ufności lub prawdopodobieństwo a posteriori. Zatem, aby obliczyć taką wielkość, należy przyjąć formalne założenia probabilistyczne dotyczące danych i procesów, które je wygenerowały. Jakość wyników modelowania statystycznego w dużym stopniu zależy od tych wcześniej określonych założeń, jak również od tego, w jakim stopniu obserwowane dane wydają się z nimi zgadzać. Najbardziej krytycznymi czynnikami są tutaj założenia teoretyczne: “Jeśli moje obserwacje były niezależne, a reszty mają rozkład X, to statystyka testowa Y może być użyta do uzyskania wartości \(p\). W przeciwnym razie wynikowa wartość \(p\) może być niewłaściwa.”
Jednym z aspektów analiz inferencyjnych jest to, że istnieje tendencja do opóźnionego sprzężenia zwrotnego w zrozumieniu, jak dobrze dane odpowiadają założeniom modelu. W naszym przykładzie badania klinicznego, jeśli znaczenie statystyczne (i kliniczne) wskazuje, że nowa terapia powinna być dostępna do stosowania przez pacjentów, mogą minąć lata zanim zostanie ona zastosowana w terenie i zostanie wygenerowana wystarczająca ilość danych do niezależnej oceny, czy pierwotna analiza statystyczna doprowadziła do podjęcia właściwej decyzji.
2.1.3 Modele predykcyjne
Czasami modelowania używamy w celu uzyskania jak najdokładniejszej prognozy dla nowych danych. W tym przypadku głównym celem jest, aby przewidywane wartości (ang. prediction) miały najwyższą możliwą zgodność z prawdziwą wartością (ang. observed).
Prostym przykładem może być przewidywanie przez sprzedającego książki, ile egzemplarzy danej książki powinno być zamówionych do jego sklepu w następnym miesiącu. Nadmierna prognoza powoduje marnowanie miejsca i pieniędzy z powodu nadmiaru książek. Jeśli przewidywanie jest mniejsze niż powinno, następuje utrata potencjału i mniejszy zysk.
Celem tego typu modeli jest raczej estymacja niż wnioskowanie. Na przykład nabywca zwykle nie jest zainteresowany pytaniem typu “Czy w przyszłym miesiącu sprzedam więcej niż 100 egzemplarzy książki X?”, ale raczej “Ile egzemplarzy książki X klienci kupią w przyszłym miesiącu?”. Również, w zależności od kontekstu, może nie być zainteresowania tym, dlaczego przewidywana wartość wynosi X. Innymi słowy, bardziej interesuje go sama wartość niż ocena formalnej hipotezy związanej z danymi. Prognoza może również zawierać miary niepewności. W przypadku nabywcy książek podanie błędu prognozy może być pomocne przy podejmowaniu decyzji, ile książek należy kupić. Może też służyć jako metryka pozwalająca ocenić, jak dobrze zadziałała metoda predykcji.
Jakie są najważniejsze czynniki wpływające na modele predykcyjne? Istnieje wiele różnych sposobów, w jaki można stworzyć model predykcyjny, dlatego w ocenie wpływu poszczególnych czynników kluczowej jest to jak model został opracowany.
Model mechanistyczny może być wyprowadzony przy użyciu podstawowych zasad w celu uzyskania równania modelowego, które zależy od pewnych założeń. Na przykład przy przewidywaniu ilości leku, która znajduje się w organizmie danej osoby w określonym czasie, przyjmuje się pewne formalne założenia dotyczące sposobu podawania, wchłaniania, metabolizowania i eliminacji leku. Na tej podstawie można wykorzystać układ równań różniczkowych do wyprowadzenia określonego równania modelowego. Dane są wykorzystywane do oszacowania nieznanych parametrów tego równania, tak aby można było wygenerować prognozy. Podobnie jak modele inferencyjne, mechanistyczne modele predykcyjne w dużym stopniu zależą od założeń, które definiują ich równania modelowe. Jednakże, w przeciwieństwie do modeli inferencyjnych, łatwo jest formułować oparte na danych stwierdzenia dotyczące tego, jak dobrze model działa, na podstawie tego, jak dobrze przewiduje istniejące dane. W tym przypadku pętla sprzężenia zwrotnego dla osoby zajmującej się modelowaniem jest znacznie szybsza niż w przypadku testowania hipotez.
Modele empiryczne są tworzone przy bardziej niejasnych założeniach. Modele te należą zwykle do kategorii uczenia maszynowego. Dobrym przykładem jest model K-najbliższych sąsiadów (KNN). Biorąc pod uwagę zestaw danych referencyjnych, nowa obserwacja jest przewidywana przy użyciu wartości K najbardziej podobnych danych w zestawie referencyjnym. Na przykład, jeśli kupujący książkę potrzebuje prognozy dla nowej książki, a dodatkowo posiada dane historyczne o istniejących książkach, wówczas model 5-najbliższych sąsiadów może posłużyć do estymacji liczby nowych książek do zakupu na podstawie liczby sprzedaży pięciu książek, które są najbardziej podobne do nowej książki (dla pewnej definicji “podobnej”). Model ten jest zdefiniowany jedynie przez samą funkcję predykcji (średnia z pięciu podobnych książek). Nie przyjmuje się żadnych teoretycznych lub probabilistycznych założeń dotyczących sprzedaży lub zmiennych, które są używane do określenia podobieństwa pomiędzy książkami. W rzeczywistości podstawową metodą oceny adekwatności modelu jest ocena jego precyzji przy użyciu istniejących danych. Jeśli model jest dobrym wyborem, predykcje powinny być zbliżone do wartości rzeczywistych.
2.2 Związki pomiędzy typami modeli
Zwykły model regresji może należeć do którejś z tych trzech klas modeli, w zależności od sposobu jego wykorzystania:
model regresji liniowej może być użyty do opisania trendów w danych;
model analizy wariancji (ANOVA) jest specjalnym rodzajem modelu liniowego, który może być użyty do wnioskowania o prawdziwości hipotezy;
model regresji liniowej wykorzystywany jako model predykcyjny.
Istnieje dodatkowy związek między typami modeli, ponieważ konstrukcje, których celem był opis zjawiska lub wnioskowanie o nim, nie są zwykle wykorzystywane do predykcji, to nie należy całkowicie ignorować ich zdolności predykcyjnych. W przypadku pierwszych dwóch typów modeli, badacz skupia się głównie na wyselekcjonowaniu statystycznie istotnych zmiennych w modelu oraz spełnieniu szeregu założeń pozwalających na bezpieczne wnioskowanie. Takie podejście może być niebezpieczne, gdy istotność statystyczna jest używana jako jedyna miara jakości modelu. Jest możliwe, że ten statystycznie zoptymalizowany model ma słabą dokładność wyrażoną pewną miarą dopasowania. Wiemy więc, że model może nie być używany do przewidywania, ale jak bardzo należy ufać wnioskom z modelu, który ma istotne wartości \(p\), ale fatalną dokładność?
Ważne
Jeśli model nie jest dobrze dopasowany do danych, wnioski uzyskane na jego podstawie mogą być wysoce wątpliwe. Innymi słowy, istotność statystyczna może nie być wystarczającym dowodem na to, że model jest właściwy.
Istnieje również podział samych modeli uczenia maszynowego. Po pierwsze, wiele modeli można skategoryzować jako nadzorowane lub nienadzorowane. Modele nienadzorowane to takie, które uczą się wzorców, skupisk lub innych cech danych, ale nie mają zmiennej wynikowej (nauczyciela). Analiza głównych składowych (PCA), analiza skupień czy autoenkodery są przykładami modeli nienadzorowanych; są one używane do zrozumienia relacji pomiędzy zmiennymi lub zestawami zmiennych bez wyraźnego związku pomiędzy predyktorami i wynikiem. Modele nadzorowane to takie, które mają zmienną wynikową. Regresja liniowa, sieci neuronowe i wiele innych metodologii należą do tej kategorii.
W ramach modeli nadzorowanych można wyróżnić dwie główne podkategorie:
regresyjne - przewidujące zmienną wynikową będącą zmienną o charakterze ilościowym;
klasyfikacyjne - przewidujące zmienną wynikową będącą zmienną o charakterze jakościowym.
Różne zmienne modelu mogą pełnić różne role, zwłaszcza w nadzorowanym uczeniu maszynowym. Zmienna zależna lub objaśniana (ang. outcome) to wartość przewidywana w modelach nadzorowanych. Zmienne niezależne, które są podłożem do tworzenia przewidywań wyniku, są również określane jako predyktory, cechy lub kowarianty (w zależności od kontekstu).
2.3 Proces tworzenie modelu
Po pierwsze, należy pamiętać o chronicznie niedocenianym procesie czyszczenia danych. Bez względu na okoliczności, należy przeanalizować dane pod kątem tego, czy są one odpowiednie do celów projektu i czy są właściwe. Te kroki mogą z łatwością zająć więcej czasu niż cała reszta procesu analizy danych (w zależności od okoliczności).
Czyszczenie danych może również pokrywać się z drugą fazą eksploracji danych, często określaną jako eksploracyjna analiza danych (ang. exploratory data analysis - EDA). EDA wydobywa na światło dzienne to, jak różne zmienne są ze sobą powiązane, ich rozkłady, typowe zakresy zmienności i inne atrybuty. Dobrym pytaniem, które należy zadać w tej fazie, jest “Jak dotarłem do tych danych?”. To pytanie może pomóc zrozumieć, w jaki sposób dane, o których mowa, były próbkowane lub filtrowane i czy te operacje były właściwe. Na przykład podczas łączenia tabel bazy danych może dojść do nieudanego złączenia, które może przypadkowo wyeliminować jedną lub więcej subpopulacji.
Wreszcie, przed rozpoczęciem procesu analizy danych, powinny istnieć jasne oczekiwania co do celu modelu i sposobu oceny jego wydajności. Należy zidentyfikować przynajmniej jedną metrykę wydajności z realistycznymi celami dotyczącymi tego, co można osiągnąć. Typowe metryki statystyczne, to dokładność klasyfikacji (ang. accuracy), odsetek poprawnie i niepoprawnie zaklasyfikowanych sukcesów (przez sukces rozumiemy wyróżnioną klasę), pierwiastek błędu średniokwadratowego i tak dalej. Należy rozważyć względne korzyści i wady tych metryk. Ważne jest również, aby metryka była zgodna z szerszymi celami analizy danych.
Typowy przebieg budowy modelu
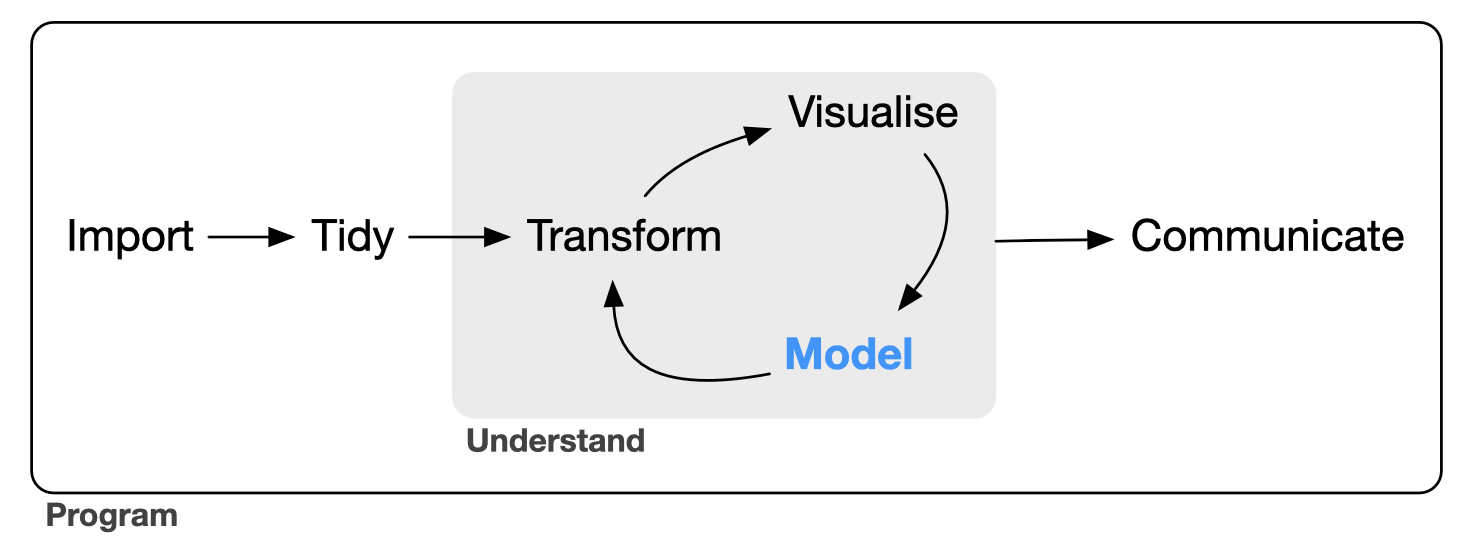
Proces badania danych może nie być prosty. Wickham i in. (2019) przedstawili doskonałą ilustrację ogólnego procesu analizy danych. Import danych i czyszczenie/porządkowanie są pokazane jako początkowe kroki. Kiedy rozpoczynają się kroki analityczne dla zrozumienia relacji panujących pomiędzy predyktorami i/lub zmienną wynikową, nie możemy wstępnie określić, ile czasu mogą zająć. Cykl transformacji, modelowania i wizualizacji często wymaga wielu iteracji.
W ramach czynności zaznaczonych na szarym polu możemy wyróżnić:
eksploracyjna analiza danych - to kombinacja pewnych obliczeń statystycznych i wizualizacji, w celu odpowiedzi na podstawowe pytania i postawienia kolejnych. Przykładowo jeśli na wykresie histogramu lub gęstości zmiennej wynikowej w zadaniu regresyjnym zauważymy wyraźną dwumodalność, to może ona świadczyć, że badana zbiorowość nie jest homogeniczna w kontekście analizowanej zmiennej, a co w konsekwencji może skłonić nas do oddzielnego modelowania zjawisk w każdej z podpopulacji.
inżynieria cech (ang. feature engineering) - zespół czynności mający na celu transformację i selekcję cech w procesie budowania modelu.
tuning modeli - zespół czynności mający na celu optymalizację hiperparametrów modeli, poprzez wybór różnych ich konfiguracji oraz porównanie efektów uczenia.
ocena dopasowania modeli - ocena jakości otrzymanych modeli na podstawie miar oraz wykresów diagnostycznych.
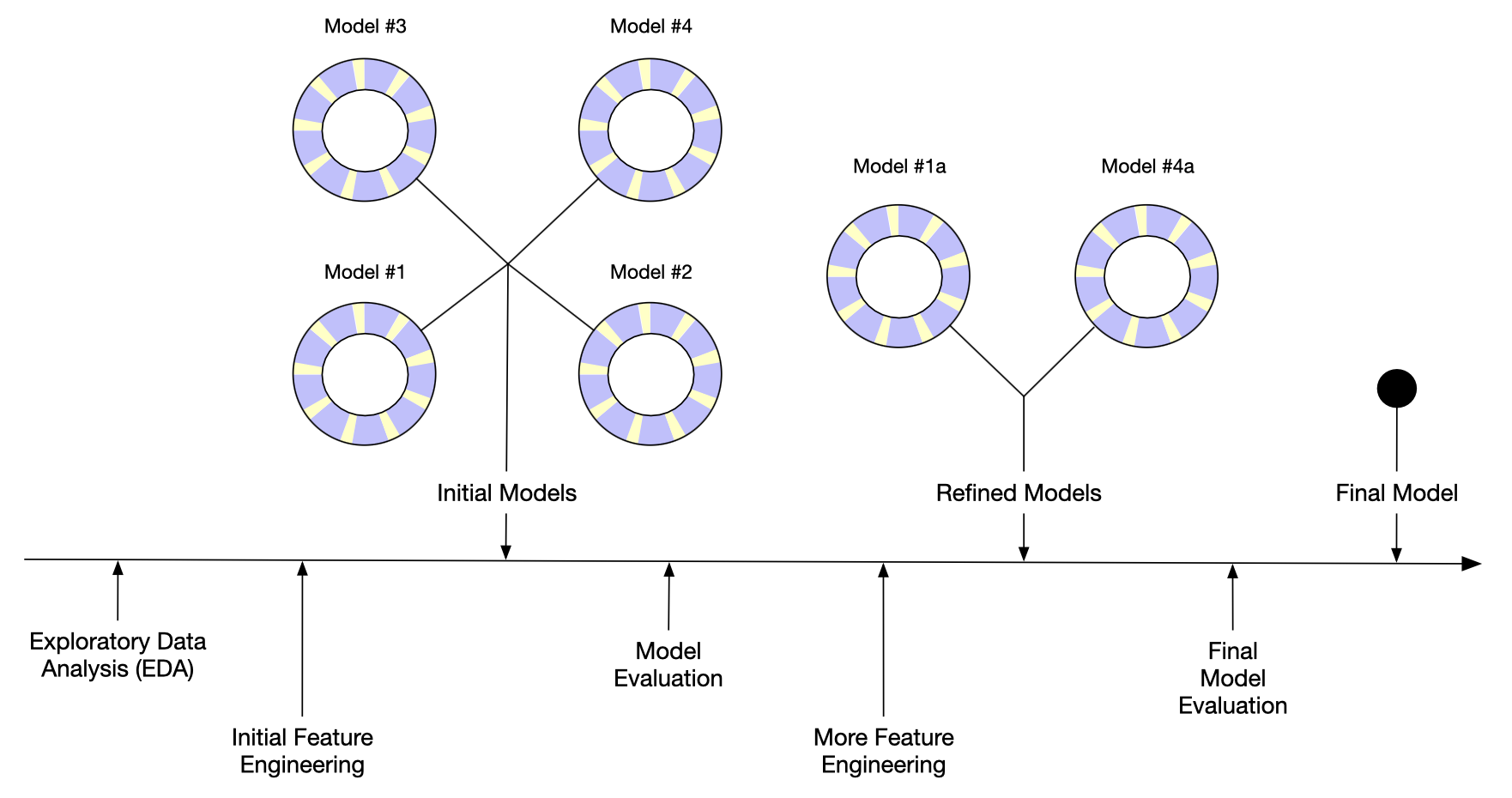
Przykładowy przebieg budowy modelu
Przykładowo w pracy Kuhn i Johnson (2021) autorzy badając natężenie ruchu kolei publicznej w Chicago, przeprowadzili następujące rozumowanie podczas budowy modelu (oryginalna pisownia):
Kod
dt<-tibble::tribble(~Thoughts, ~Activity,"The daily ridership values between stations are extremely correlated.", "EDA","Weekday and weekend ridership look very different.", "EDA","One day in the summer of 2010 has an abnormally large number of riders.", "EDA","Which stations had the lowest daily ridership values?", "EDA","Dates should at least be encoded as day-of-the-week, and year.", "Feature Engineering","Maybe PCA could be used on the correlated predictors to make it easier for the models to use them.", "Feature Engineering","Hourly weather records should probably be summarized into daily measurements.", "Feature Engineering","Let’s start with simple linear regression, K-nearest neighbors, and a boosted decision tree.", "Model Fitting","How many neighbors should be used?", "Model Tuning","Should we run a lot of boosting iterations or just a few?", "Model Tuning","How many neighbors seemed to be optimal for these data?", "Model Tuning","Which models have the lowest root mean squared errors?", "Model Evaluation","Which days were poorly predicted?", "EDA","Variable importance scores indicate that the weather information is not predictive. We’ll drop them from the next set of models.", "Model Evaluation","It seems like we should focus on a lot of boosting iterations for that model.", "Model Evaluation","We need to encode holiday features to improve predictions on (and around) those dates.", "Feature Engineering","Let’s drop KNN from the model list.", "Model Evaluation")dt|>gt::gt()
Thoughts
Activity
The daily ridership values between stations are extremely correlated.
EDA
Weekday and weekend ridership look very different.
EDA
One day in the summer of 2010 has an abnormally large number of riders.
EDA
Which stations had the lowest daily ridership values?
EDA
Dates should at least be encoded as day-of-the-week, and year.
Feature Engineering
Maybe PCA could be used on the correlated predictors to make it easier for the models to use them.
Feature Engineering
Hourly weather records should probably be summarized into daily measurements.
Feature Engineering
Let’s start with simple linear regression, K-nearest neighbors, and a boosted decision tree.
Model Fitting
How many neighbors should be used?
Model Tuning
Should we run a lot of boosting iterations or just a few?
Model Tuning
How many neighbors seemed to be optimal for these data?
Model Tuning
Which models have the lowest root mean squared errors?
Model Evaluation
Which days were poorly predicted?
EDA
Variable importance scores indicate that the weather information is not predictive. We’ll drop them from the next set of models.
Model Evaluation
It seems like we should focus on a lot of boosting iterations for that model.
Model Evaluation
We need to encode holiday features to improve predictions on (and around) those dates.
Feature Engineering
Let’s drop KNN from the model list.
Model Evaluation
Bolstad, Benjamin Milo. 2004. Low-Level Analysis of High-Density Oligonucleotide Array Data: Background, Normalization and Summarization. University of California, Berkeley.
Gentleman, Robert, Vincent Carey, Wolfgang Huber, Sandrine Dudoit, i Rafael Irizarry. 2005. Bioinformatics and Computational Biology Solutions Using R and Bioconductor. Springer.
Kuhn, Max, i Kjell Johnson. 2021. Feature Engineering and Selection: A Practical Approach for Predictive Models. Taylor & Francis Group.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, i in. 2019. „Welcome to the Tidyverse”. Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.