Istnieje kilka etapów tworzenia użytecznego modelu, w tym estymacja parametrów, wybór i tuning modelu oraz ocena wydajności. Na starcie nowego projektu zazwyczaj istnieje skończona pula danych dostępna dla wszystkich tych zadań, o której możemy myśleć jako o dostępnym budżecie danych. W jaki sposób dane powinny być zastosowane do różnych kroków lub zadań? Idea wykorzystania danych jest ważną pierwszą kwestią podczas modelowania, szczególnie jeśli chodzi o walidację empiryczną.
Zagrożenie
Kiedy dane są wielokrotnie wykorzystywane do wielu zadań, zamiast ostrożnie “wydawane” ze skończonego budżetu danych, wzrasta pewne ryzyko, takie jak uwypuklenie obciążenia modelu lub potęgowania efektów wynikających z błędów metodologicznych.
Gdy dysponujemy ogromnym zbiorem danych, mądrą strategią jest przydzielenie określonych podzbiorów danych do różnych zadań, w przeciwieństwie do przydzielenia największej możliwej ilości (lub nawet wszystkich) tylko do estymacji parametrów modelu. Na przykład, jedną z możliwych strategii jest przeznaczenie określonego podzbioru danych do określenia, które predyktory są informacyjne, przed rozważeniem estymacji parametrów w ogóle. Jeśli początkowa pula dostępnych danych nie jest duża, będzie istniało pewne nakładanie się tego, jak i kiedy nasze dane są “wydawane” lub przydzielane, a solidna metodologia wydawania danych okaże się istotna.
5.1 Podział na próbę uczącą i testową
Podstawowym podejściem w empirycznej walidacji modelu jest podział istniejącej puli danych na dwa odrębne zbiory - treningowy i testowy. Jedna część danych jest wykorzystywana do budowy i optymalizacji modelu. Ten zbiór treningowy stanowi zazwyczaj większość danych. Dane te służą dla budowy modelu, poszukiwania optymalnych parametrów modelu, czy selekcji cech istotnych z punktu widzenia predykcji.
Pozostała część danych stanowi zbiór testowy. Jest on trzymany aż do momentu, gdy jeden lub dwa modele zostaną wybrane jako metody najlepiej opisujące badane zjawisko. Zestaw testowy jest wtedy używany jako ostateczny arbiter do określenia dopasowania modelu. Krytyczne jest, aby użyć zbiór testowy tylko raz; w przeciwnym razie staje się on częścią procesu modelowania.
Proporcje w jakich należy podzielić dane nie są wyraźnie sprecyzowane. Choć istnieją prace, jak np. Joseph (2022), które wskazują konkretne reguły podziału zbioru danych na uczący i testowy dla modeli regresyjnych, to nie ma co do tego powszechnej zgody, że tylko jedna proporcja jest optymalna. W przypadku wspomnianej metody próba testowa powinna stanowić
\[
\frac{1}{\sqrt{p}+1},
\]
zbioru danych, gdzie \(p\) oznacza liczbę predyktorów modelu.
Wskazówka
Decydując się na wybór proporcji podziału należy pamiętać, że przy mniejszej ilości danych uczących, oszacowania parametrów mają wysoką wariancję. Z drugiej strony, mniejsza ilość danych testowych prowadzi do wysokiej wariancji w miarach dopasowania (czyli mamy duże różnice pomiędzy dopasowaniem na zbiorze uczącym i testowym).
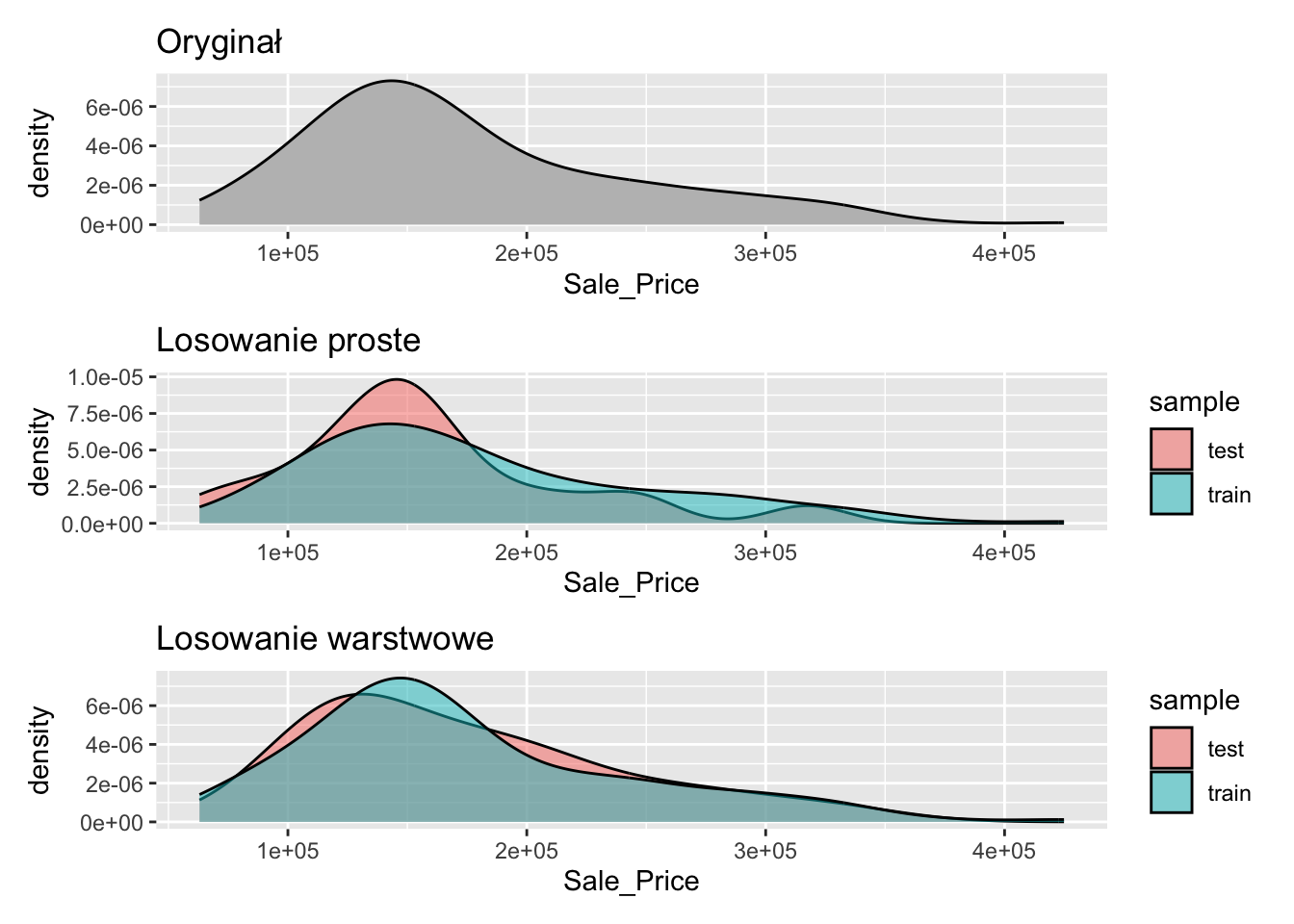
W podziale zbioru danych na uczący i testowy, ważny jest jeszcze jeden aspekt. W jaki sposób podziału dokonujemy. Najpowszechniej stosowany jest podział losowy (losowanie proste). Próbkowanie losowe jest najstarszą i najbardziej popularną metodą dzielenia zbioru danych. Jak sama nazwa wskazuje, losowane są indeksy obserwacji, które będą przyporządkowane do zbioru uczącego. Pozostałe obserwacje będą należeć do zbioru testowego.
Metoda ta ma jednak istotną wadę. Próbkowanie losowe działa poprawnie na zbiorach danych zbalansowanych klasowo, czyli takich, w których liczba próbek w każdej kategorii jest mniej więcej taka sama. W przypadku zbiorów danych niezbalansowanych klasowo, taka metoda podziału danych może tworzyć obciążenie modelu.
Na przykład, jeśli zbiór danych zawiera 100 obrazów, z których 80 należy do kategorii “pies” i 20 należy do kategorii “kot”, a losowe próbkowanie jest stosowane do podziału danych na zbiory uczący i testowy w stosunku 80%-20% (odpowiednio), może się tak zdarzyć, że zbiór treningowy składa się tylko z obrazów psów, podczas gdy zbiór testowy składa się tylko z obrazów kotów. Nawet jeśli nie zdarzy się tak ekstremalny przypadek, to nierównowaga rozkładów w obu zbiorach może być wyraźna.
Losowanie warstwowe zastosowane do podziału zbioru danych łagodzi problem próbkowania losowego w zbiorach danych z niezrównoważonym rozkładem klas. W tym przypadku, rozkład klas w każdym z zestawów treningowych i testowych jest zachowany.
Załóżmy, że zbiór danych składa się z 100 obrazów, z których 60 to obrazy psów, a 40 to obrazy kotów. W takim przypadku próbkowanie warstwowe zapewnia, że 60% obrazów należy do kategorii “pies”, a 40% do kategorii “kot” w zbiorach uczącym i testowym. Oznacza to, że jeśli pożądany jest podział w proporcji 80%-20%, z 80 obrazów w zbiorze treningowym, 48 obrazów (60%) będzie należało do psów, a pozostałe 32 (40%) do kotów.
Rozważmy inny przykład. W zadaniach wykrywania obiektów, pojedyncze obrazy mogą zawierać kilka różnych obiektów należących do różnych kategorii. W zbiorze danych niektóre obrazy mogą zawierać 10 psów, ale tylko 1 osobę, inne mogą zawierać 10 osób i 2 psy, a jeszcze inne mogą zawierać 5 kotów i 5 psów, bez ludzi. W takich przypadkach, losowy podział obrazów może zakłócić rozkład kategorii obiektów. Próbkowanie warstwowe z drugiej strony pozwala podzielić dane w taki sposób, że wynikowy rozkład kategorii obiektów jest zrównoważony.
Wskazówka
W przypadku dużych zbiorów danych różnice pomiędzy losowaniem prostym i warstwowym się zacierają.
Przykład 5.1 Przykładem zastosowania obu wspomnianych technik będzie podział zbioru attrition pakietu modeldata.
Kod
library(tidymodels)# proporcje zmiennej wynikowej w całym zbiorzeset.seed(4)dane<-attrition|>slice_sample(n =100)dane|>count(Attrition)|>mutate(prop =round(n/sum(n)*100, 0))
Attrition n prop
1 No 83 83
2 Yes 17 17
Kod
set.seed(4)# podział losowyrandom_split<-initial_split(dane, prop =0.9)random_split
<Training/Testing/Total>
<90/10/100>
Kod
tr_random<-training(random_split)te_random<-testing(random_split)# podział warstwowystrata_split<-initial_split(dane, prop =0.9, strata =Attrition)strata_split
<Training/Testing/Total>
<89/11/100>
Kod
tr_strata<-training(strata_split)te_strata<-testing(strata_split)# proporcje zmiennej wynikowej w obu zbiorach uczącychtr_random|>count(Attrition)|>mutate(prop =round(n/sum(n)*100, 0))
Co ciekawe parametru strata w funkcji initial_split można też użyć do zmiennej ilościowej. Wówczas algorytm podzieli próbę z zachowaniem proporcji obserwacji w kolejnych kwartylach. Ta technika może się okazać szczególnie ważna w przypadku gdy zmienna wynikowa ma znaczącą asymetrię rozkładu.
Rys. 5.1: Porównanie próbkowań dla zmiennej typu ilościowego
Wskazówka
Proporcja użyta do podziału, w dużym stopniu zależy od kontekstu rozpatrywanego problemu. Zbyt mała ilość danych w zbiorze treningowym ogranicza zdolność modelu do znalezienia odpowiednich oszacowań parametrów. I odwrotnie, zbyt mała ilość danych w zbiorze testowym obniża jakość oszacowań wydajności. Niektórzy statystycy unikają zbiorów testowych w ogóle, ponieważ uważają, że wszystkie dane powinny być używane do estymacji parametrów. Chociaż argument ten jest słuszny, dobrą praktyką modelowania jest posiadanie bezstronnego zestawu obserwacji jako ostatecznego arbitra jakości modelu. Zestawu testowego należy unikać tylko wtedy, gdy dane są drastycznie małe.
Jeszcze jedna uwaga na temat losowego podziału zbioru na uczący i testowy. W jednej sytuacji podział losowy i warstwowy nie są najlepszym rozwiązaniem - chodzi o szeregi czasowe lub dane zawierające znaczący czynnik zmienności w czasie. Wówczas stosuje się podział zbioru za pomocą funkcji initial_time_split, która parametrem prop określa jaka proporcja obserwacji z początku zbioru danych będzie wybrana do zbioru uczącego1.
1 zakłada się, że dane są posortowane wg czasu
Opisując cele podziału danych, wyróżniliśmy zbiór testowy jako dane, które powinny być wykorzystane do właściwej oceny działania modelu na modelu końcowym (modelach). To rodzi pytanie: “Jak możemy określić, co jest najlepsze, jeśli nie mierzymy wydajności aż do zbioru testowego?”.
Często słyszy się o zbiorach walidacyjnych jako odpowiedzi na to pytanie, szczególnie w literaturze dotyczącej sieci neuronowych i głębokiego uczenia. U początków sieci neuronowych badacze zdali sobie sprawę, że mierzenie wydajności poprzez przewidywanie na podstawie zbioru treningowego prowadziło do wyników, które były zbyt optymistyczne (nierealistycznie). Prowadziło to do modeli, które były nadmiernie dopasowane, co oznaczało, że osiągały bardzo dobre wyniki na zbiorze treningowym, ale słabe na zbiorze testowym. Aby ograniczyć ten problem, wybierano ze zbioru uczącego niewielki zbiór walidacyjny i użyto go do pomiaru wydajności podczas trenowania sieci. Gdy poziom błędu na zbiorze walidacyjnym zaczynał rosnąć, trening był wstrzymywany. Innymi słowy, zbiór walidacyjny był środkiem do uzyskania przybliżonego poczucia, jak dobrze model działał przed zbiorem testowym.
W przypadku danych dotyczących mieszkań w Ames, nieruchomość jest traktowana jako niezależna jednostka eksperymentalna. Można bezpiecznie założyć, że statystycznie dane z danej nieruchomości są niezależne od innych nieruchomości. W przypadku innych zastosowań nie zawsze tak jest:
Na przykład w przypadku danych podłużnych (ang. longitudinal data) ta sama niezależna jednostka eksperymentalna może być mierzona w wielu punktach czasowych. Przykładem może być osoba w badaniu medycznym.
Partia wyprodukowanego produktu może być również uważana za niezależną jednostkę doświadczalną. W powtarzanych pomiarach, replikowane punkty danych z partii są zbierane w wielu momentach.
Johnson i in. (2018) opisują eksperyment, w którym próbki różnych drzew były pobierane w górnej i dolnej części pnia. Tutaj drzewo jest jednostką eksperymentalną, a hierarchię danych stanowi próbka w obrębie części pnia dla każdego drzewa.
Kuhn i Johnson (2019) zawiera inne przykłady, w których dla pojedyncze obserwacje mierzone są kilkukrotnie, losowanie przypadków wśród wierszy nie zapewni niezależności obserwacji. Wówczas powinno się losować całe zestawy obserwacji przyporządkowanych do jednostki eksperymentalnej. Operatem losowania powinna być lista jednostek eksperymentalnych.
Ważne
Problem wycieku informacji (ang. data leakage) występuje, gdy w procesie modelowania wykorzystywane są dane spoza zbioru treningowego
Na przykład, w konkursach uczenia maszynowego, dane zbioru testowego mogą być dostarczone bez prawdziwych wartości zmiennej wynikowej, aby model mógł być rzetelnie oceniony. Jedną z potencjalnych metod poprawy wyniku może być dopasowanie modelu przy użyciu obserwacji zbioru treningowego, które są najbardziej podobne do wartości zbioru testowego. Chociaż zbiór testowy nie jest bezpośrednio wykorzystywany do dopasowania modelu, nadal ma duży wpływ. Ogólnie rzecz biorąc, ta technika jest wysoce problematyczna, ponieważ zmniejsza błąd generalizacji modelu w celu optymalizacji wydajności na określonym zbiorze danych. Istnieją bardziej subtelne sposoby, w jakie dane z zestawu testowego mogą być wykorzystywane podczas szkolenia. Zapisywanie danych treningowych w oddzielnej ramce danych od zbioru testowego jest jednym sposobem zapewnienia, aby wyciek informacji nie nastąpił przez przypadek.
Po drugie, techniki podpróbkowania (ang. subsampling) zbioru treningowego mogą łagodzić pewne problemy (np. nierównowagę klas). Jest to ważna i powszechna technika, która celowo powoduje, że dane zbioru treningowego odbiegają od populacji, z której dane zostały pobrane. Ważne jest, aby zbiór testowy nadal odzwierciedlał to, co model napotkałby w środowisku naturalnym.
Na początku tego rozdziału, ostrzegaliśmy przed używaniem tych samych danych do różnych zadań. W dalszej części tej książki omówimy metodologie wykorzystania danych, które pozwolą zmniejszyć ryzyko związane z tendencyjnością, nadmiernym dopasowaniem i innymi problemami.
Johnson, Dan, Phoebe Eckart, Noah Alsamadisi, Hilary Noble, Celia Martin, i Rachel Spicer. 2018. „Polar Auxin Transport Is Implicated in Vessel Differentiation and Spatial Patterning During Secondary Growth in Populus”. American Journal of Botany 105 (2): 186–96. https://doi.org/10.1002/ajb2.1035.
Joseph, V. Roshan. 2022. „Optimal Ratio for Data Splitting”. Statistical Analysis and Data Mining: The ASA Data Science Journal 15 (4): 531–38. https://doi.org/10.1002/sam.11583.