W poprzednich rozdziałach pokazano, jak wyszukiwanie oparte o siatkę przyjmuje wstępnie zdefiniowany zestaw wartości kandydujących, ocenia je, a następnie wybiera najlepsze ustawienia. Iteracyjne metody wyszukiwania realizują inną strategię. Podczas procesu wyszukiwania przewidują one, które wartości należy przetestować w następnej kolejności.
W tym rozdziale przedstawiono dwie metody wyszukiwania. Najpierw omówimy optymalizację bayesowską, która wykorzystuje model statystyczny do przewidywania lepszych ustawień parametrów. Następnie rozdział opisuje metodę globalnego wyszukiwania zwaną symulowanym wyżarzaniem (ang. simulated annealing).
Do ilustracji wykorzystujemy te same dane dotyczące charakterystyki komórek, co w poprzednim rozdziale, ale zmieniamy model. W tym rozdziale użyjemy modelu maszyny wektorów nośnych (ang. Support Vector Machine), ponieważ zapewnia on ładne dwuwymiarowe wizualizacje procesów wyszukiwania. Dwa dostrajane parametry w optymalizacji to wartość kosztu SVM i parametr jądra funkcji radialnej \(\sigma\). Oba parametry mogą mieć znaczący wpływ na złożoność i wydajność modelu.
Model SVM wykorzystuje iloczyn skalarny i z tego powodu konieczne jest wyśrodkowanie i przeskalowanie predyktorów. Obiekty tidymodels: svm_rec, svm_spec i svm_wflow definiują proces tworzenia modelu:
Kod
library(tidymodels)library(finetune)tidymodels_prefer()data(cells)cells<-cells%>%select(-case)set.seed(1304)cell_folds<-vfold_cv(cells)svm_rec<-recipe(class~., data =cells)%>%step_YeoJohnson(all_numeric_predictors())%>%step_normalize(all_numeric_predictors())svm_spec<-svm_rbf(cost =tune(), rbf_sigma =tune())%>%set_engine("kernlab")%>%set_mode("classification")svm_wflow<-workflow()%>%add_model(svm_spec)%>%add_recipe(svm_rec)
Oto domyślne zakresy tuningowanych parametrów:
Kod
cost()rbf_sigma()
Dla ilustracji, zmieńmy nieco zakres parametrów jądra, aby poprawić wizualizacje wyszukiwania:
Zanim omówimy szczegóły dotyczące wyszukiwania iteracyjnego i jego działania, zbadajmy związek między dwoma parametrami dostrajania SVM a obszarem pod krzywą ROC dla tego konkretnego zestawu danych. Skonstruowaliśmy bardzo dużą regularną siatkę, składającą się z 2500 wartości kandydujących, i oceniliśmy siatkę przy użyciu resamplingu. Jest to oczywiście niepraktyczne w regularnej analizie danych i ogromnie nieefektywne. Jednakże, wyjaśnia ścieżkę, którą powinien podążać proces wyszukiwania i gdzie występuje numerycznie optymalna wartość (wartości).
Rys. 12.1: Mapa ciepła średniego obszaru pod krzywą ROC dla siatki o dużej gęstości wartości dostrajania parametrów. Najlepszy punkt jest oznaczony kropką w prawym górnym rogu.
Rys. 12.1 pokazuje wyniki oceny tej siatki, przy czym jaśniejszy kolor odpowiada wyższej (lepszej) wydajności modelu. W dolnej przekątnej przestrzeni parametrów znajduje się duży obszar, który jest stosunkowo płaski i charakteryzuje się słabą wydajnością. Grzbiet najlepszej wydajności występuje w prawej górnej części przestrzeni. Czarna kropka wskazuje najlepsze ustawienia. Przejście od płaskiego obszaru słabych wyników do grzbietu najlepszej wydajności jest bardzo ostre. Występuje również gwałtowny spadek obszaru pod krzywą ROC tuż po prawej stronie grzbietu.
Procedury wyszukiwania, które będziemy przestawiać, wymagają przynajmniej kilku statystyk obliczonych na podstawie resamplingu. W tym celu poniższy kod tworzy małą regularną siatkę, która znajduje się w płaskiej części przestrzeni parametrów. Funkcja tune_grid() dokonuje próbkowania tej siatki:
Ta początkowa siatka pokazuje dość równoważne wyniki, przy czym żaden pojedynczy punkt nie jest znacznie lepszy od pozostałych. Wyniki te mogą być wykorzystane przez funkcje iteracyjnego dostrajania jako wartości początkowe.
12.1 Optymalizacja bayesowska
Techniki optymalizacji bayesowskiej analizują bieżące wyniki próbkowania i tworzą model predykcyjny, aby zasugerować wartości parametrów dostrajania, które nie zostały jeszcze ocenione. Sugerowana kombinacja parametrów jest następnie ponownie próbkowana. Wyniki te są następnie wykorzystywane w innym modelu predykcyjnym, który rekomenduje więcej wartości kandydatów do testowania, i tak dalej. Proces ten przebiega przez ustaloną liczbę iteracji lub do momentu, gdy nie pojawią się dalsze poprawy. Shahriari i in. (2016) i Frazier (2018) są dobrymi wprowadzeniami do optymalizacji bayesowskiej.
Podczas korzystania z optymalizacji bayesowskiej, podstawowe problemy to sposób tworzenia modelu i wybór parametrów rekomendowanych przez ten model. Najpierw rozważmy technikę najczęściej stosowaną w optymalizacji bayesowskiej, czyli model procesu gaussowskiego.
12.1.1 Model procesu gaussowskiego
Modele procesu gaussowskiego (GP) (Schulz, Speekenbrink, i Krause 2016), to techniki statystyczne, które mają swoją historię w statystyce przestrzennej (pod nazwą metod krigingu). Mogą być wyprowadzone na wiele sposobów, w tym jako model Bayesowski.
Matematycznie, GP jest zbiorem zmiennych losowych, których wspólny rozkład prawdopodobieństwa jest wielowymiarowy normalny. W kontekście naszych zastosowań jest to zbiór metryk wydajności dla wartości kandydujących parametrów dostrajania. Dla początkowej siatki czterech próbek, realizacje tych czterech zmiennych losowych wynosiły 0.8639, 0.8625, 0.8627 i 0.8659. Zakłada się, że mają rozkład wielowymiarowy normalny. Wejściami definiującymi zmienne niezależne dla modelu GP są odpowiednie wartości dostrajania parametrów (przedstawione w Tab. 12.1).
Tab. 12.1: Wartości startowe w procedurze poszukiwania optymalnych parametrów
ROC
cost
rbf_sigma
0.8639
0.01562
1e-06
0.8625
2.00000
1e-06
0.8627
0.01562
1e-04
0.8659
2.00000
1e-04
Modele procesów gaussowskich są określone przez ich funkcje średniej i kowariancji, choć to ta ostatnia ma większy wpływ na charakter modelu GP. Funkcja kowariancji jest często parametryzowana w kategoriach wartości wejściowych (oznaczanych jako \(x\)). Przykładowo, powszechnie stosowaną funkcją kowariancji jest funkcja wykładnicza kwadratowa:
gdzie \(\sigma_{i,j}^2\) jest wariancją błędu modelu równą zero jeśli \(i=j\). Możemy to interpretować jako, że wraz ze wzrostem odległości pomiędzy dwoma kombinacjami parametrów, kowariancja pomiędzy metrykami wydajności rośnie wykładniczo. Z równania wynika również, że zmienność metryki wynikowej jest minimalizowana w punktach, które już zostały zaobserwowane (tzn. gdy \(|x_i - x_j|^2\) wynosi zero). Charakter tej funkcji kowariancji pozwala procesowi gaussowskiemu reprezentować wysoce nieliniowe zależności między wydajnością modelu a dostrajaniem parametrów, nawet jeśli istnieje tylko niewielka ilość danych.
Ważną zaletą tego modelu jest to, że ponieważ określony jest pełny model prawdopodobieństwa, przewidywania dla nowych wejść mogą odzwierciedlać cały rozkład wyniku. Innymi słowy, nowe statystyki wydajności mogą być przewidywane zarówno pod względem średniej jak i wariancji.
Na podstawie początkowej siatki czterech wyników, model GP jest dopasowywany, następnie są obliczane z modelu predykcje dla kandydatów, a piąta kombinacja parametrów dostrajania jest wybierana. Obliczamy szacunkową wydajność dla nowej konfiguracji, GP jest ponownie dopasowywany do pięciu istniejących wyników (i tak dalej).
12.1.2 Funkcja akwizycji
Jak wykorzystać model procesu gaussowskiego po dopasowaniu do aktualnych danych? Naszym celem jest wybranie następnej kombinacji dostrajania parametrów, która najprawdopodobniej da “lepsze wyniki” niż obecna najlepsza. Jednym z podejść do tego jest stworzenie dużego zbioru kandydatów, a następnie wykonanie prognoz średniej i wariancji dla każdego z nich. Korzystając z tych informacji, wybieramy najkorzystniejszą wartość parametru dostrajania.
Klasa funkcji celu, zwanych funkcjami akwizycji, ułatwia kompromis pomiędzy średnią a wariancją. Przypomnijmy, że przewidywana wariancja modeli GP zależy głównie od tego, jak bardzo są one oddalone od istniejących danych. Kompromis pomiędzy przewidywaną średnią i wariancją dla nowych kandydatów jest często postrzegany przez pryzmat eksploracji i eksploatacji:
Eksploracja (ang. exploration) - powoduje wybór tych regionów, w których jest mniej obserwowanych modeli kandydujących. W ten sposób nadaje się większą wagę kandydatom o wyższej wariancji i koncentruje się na poszukiwaniu nowych wyników.
Eksploatacja (ang. exploitation) - zasadniczo opiera się istniejących wynikach, w celu odnalezienia najlepszej wartości średniej.
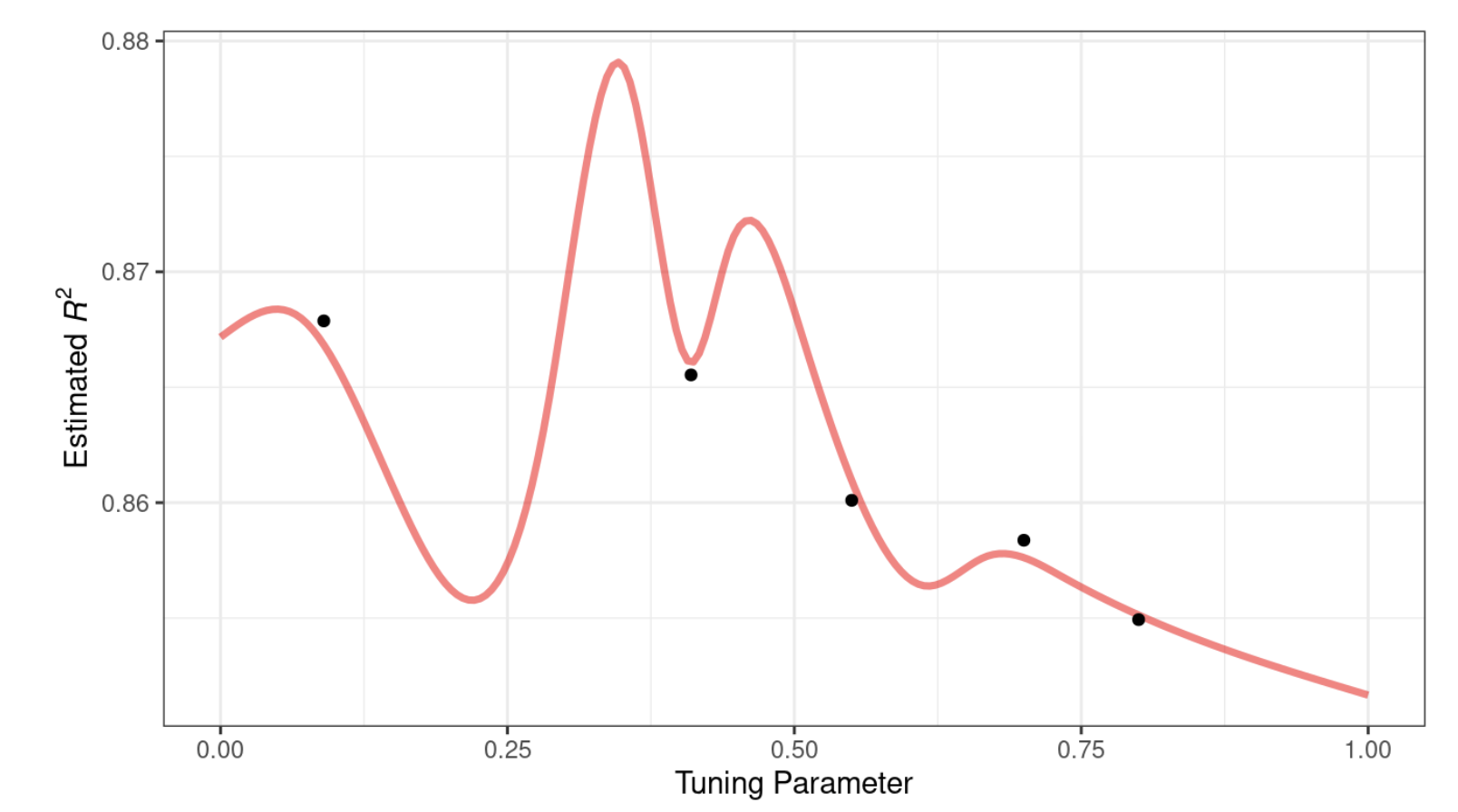
Aby zademonstrować, spójrzmy na przykład z jednym parametrem, który ma wartości pomiędzy [0, 1], a metryką wydajności jest \(R^2\). Prawdziwa funkcja jest pokazana na Rys. 12.2 wraz z pięcioma wartościami kandydującymi, które mają istniejące wyniki jako punkty.
Rys. 12.2: Hipotetyczny rzeczywisty profil wydajności dla arbitralnie wybranego parametru dostrajania, z pięcioma szacowanymi punktami
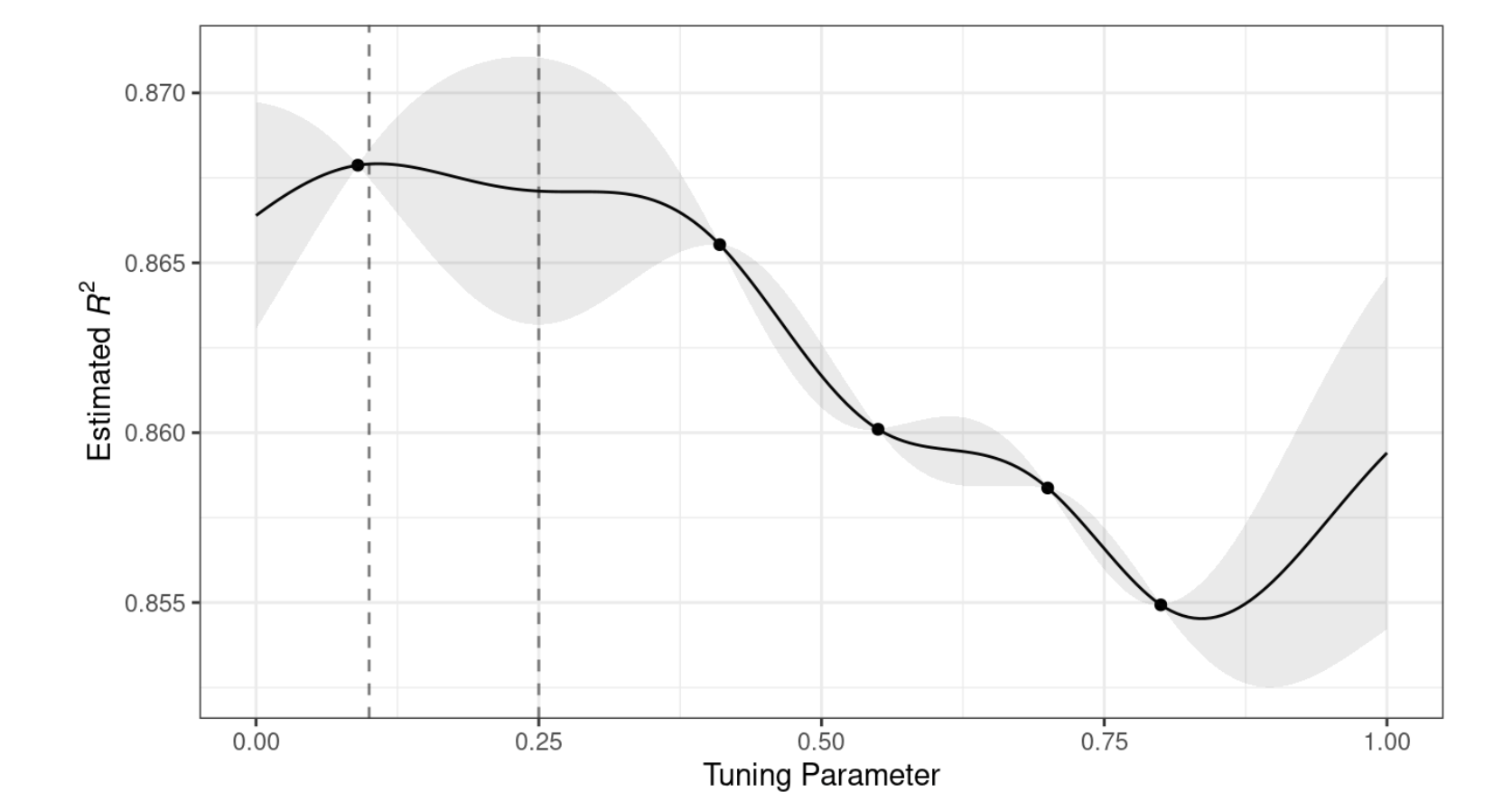
Dla tych danych dopasowanie modelu GP przedstawiono na Rys. 12.3. Zacieniowany obszar wskazuje średnią \(\pm\) 1 błąd standardowy. Dwie pionowe linie wskazują dwa punkty kandydujące, które są później bardziej szczegółowo badane. Zacieniowany obszar ufności pokazuje funkcję wykładniczej wariancji kwadratowej; staje się ona bardzo duża między punktami i zbiega do zera w istniejących punktach danych.
Rys. 12.3: Przykładowy przebieg procesu gaussowskiego z zaznaczoną funkcją średniej i wariancji
Ta nieliniowa funkcja przechodzi przez każdy obserwowany punkt, ale model nie jest doskonały. Nie ma obserwowanych punktów w pobliżu prawdziwego optimum ustawienia, a w tym regionie dopasowanie mogłoby być znacznie lepsze. Pomimo tego, model GP może skutecznie wskazać nam właściwy kierunek.
Z punktu widzenia czystej eksploatacji, najlepszym wyborem byłoby wybranie wartości parametru, który ma najlepszą średnią predykcję. W tym przypadku byłaby to wartość 0,106, tuż na prawo od istniejącego najlepszego zaobserwowanego punktu na poziomie 0,09.
Jako sposób na zachęcenie do eksploracji, prostym (ale nie często stosowanym) podejściem jest znalezienie parametru dostrajania związanego z największym przedziałem ufności.
Jedną z najczęściej stosowanych funkcji akwizycji jest oczekiwana poprawa. Pojęcie poprawy wymaga wartości dla bieżących najlepszych wyników (w przeciwieństwie do podejścia opartego na przedziałach ufności). Ponieważ GP może opisać nowy punkt kandydacki za pomocą rozkładu, możemy ważyć fragmenty rozkładu, które wykazują poprawę, używając prawdopodobieństwa wystąpienia poprawy.
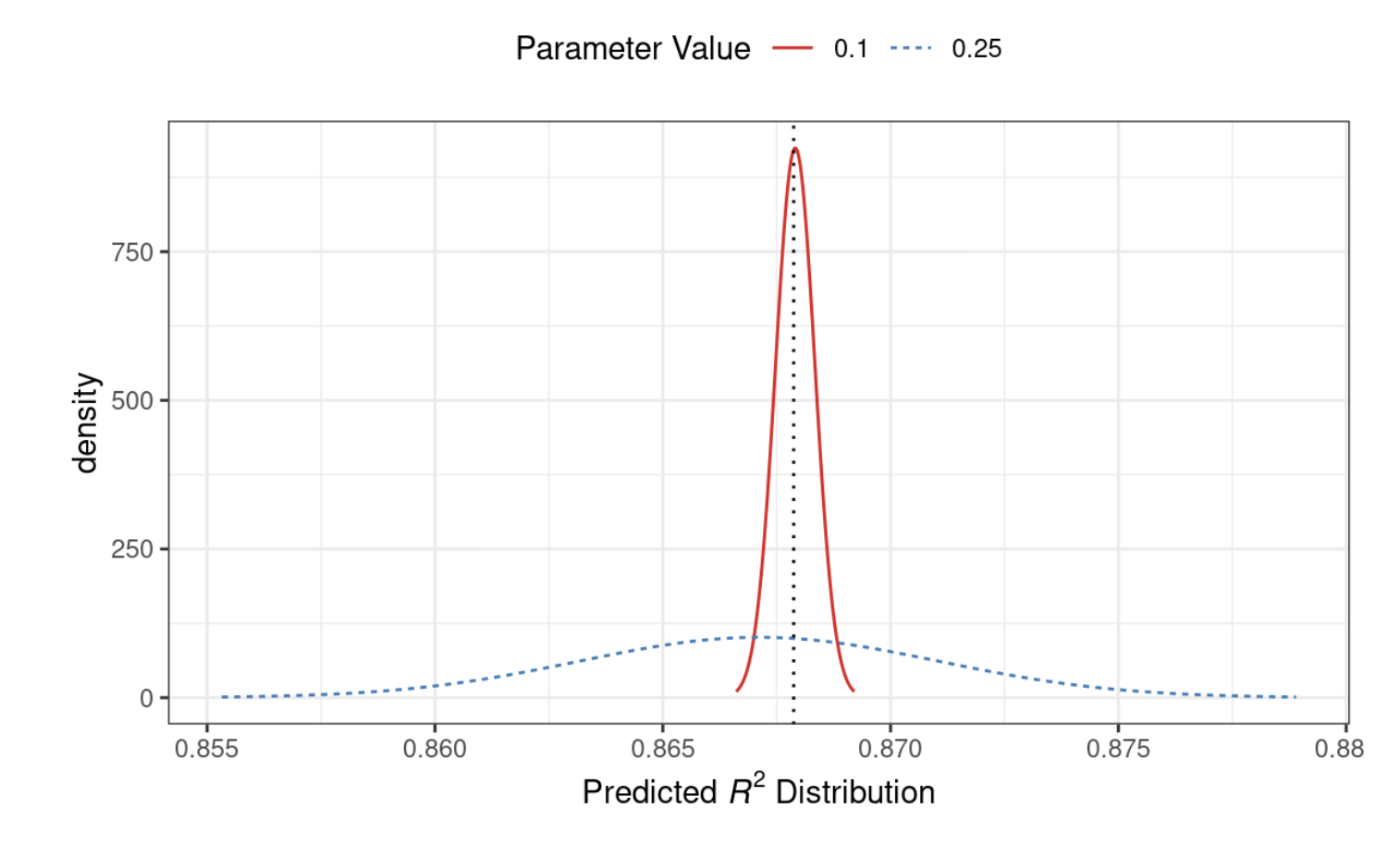
Na przykład, rozważmy dwie wartości parametrów kandydujących 0,10 i 0,25 (wskazane przez pionowe linie na Rys. 12.3). Używając dopasowanego modelu GP, ich przewidywane \(R^2\) są pokazane na Rys. 12.3 wraz z linią odniesienia dla aktualnych najlepszych wyników.
Rys. 12.4: Przewidywane rozkłady wydajności dla dwóch próbkowanych wartości parametrów dostrajania
Rozpatrując tylko średnią \(R^2\) lepszym wyborem jest wartość parametru 0,10 (patrz Tab. 12.1). Rekomendacja parametru dostrajania dla 0,25 ma gorsze przewidywanie średnie niż aktualny najlepszy kandydat. Jednakże, ponieważ ma wyższą wariancję, ma większy ogólny obszar prawdopodobieństwa powyżej aktualnego najlepszego. W rezultacie ma większą oczekiwaną poprawę:
Tab. 12.2: Oczekiwana poprawa dla dwóch kandydujących parametrów dostrajania.
Parameter.Value
Mean
Std.Dev
Expected.Improvment
0.10
0.8679
0.0004317
0.000190
0.25
0.8671
0.0039301
0.001216
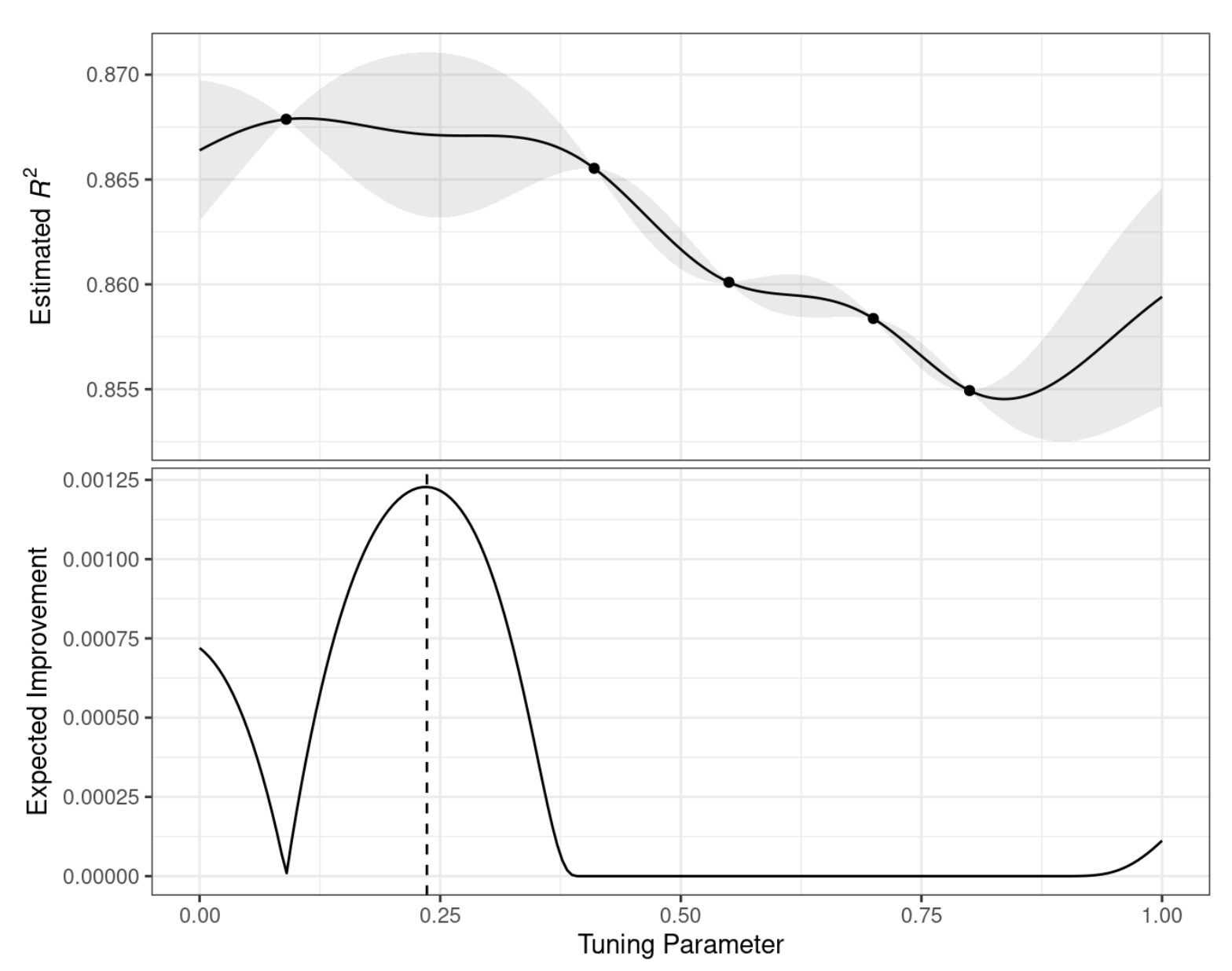
Kiedy oczekiwana poprawa jest obliczana w całym zakresie dostrajania parametrów, zalecany punkt do próbkowania jest znacznie bliższy 0,25 niż 0,10, jak pokazano na Rys. 12.5.
Rys. 12.5: Szacowany profil wydajności wygenerowany przez model procesu gaussowskiego (górny panel) oraz oczekiwana poprawa (dolny panel). Pionowa linia wskazuje punkt maksymalnej poprawy.
Aby zaimplementować wyszukiwanie iteracyjne poprzez optymalizację bayesowską, należy użyć funkcji tune_bayes(). Jej składnia jest bardzo podobna do tune_grid(), z kilkoma dodatkowymi argumentami:
iter to maksymalna liczba iteracji wyszukiwania.
initial może być liczbą całkowitą, obiektem utworzonym przy pomocy tune_grid(), albo jedną z funkcji wyścigowych. Użycie liczby całkowitej określa rozmiar konstrukcji wypełniającej przestrzeń, która jest próbkowana przed pierwszym modelem GP.
objective jest argumentem, dla którego należy użyć funkcji akwizycji. Pakiet tune zawiera funkcje takie jak exp_improve() lub conf_bound().
Argument param_info, w tym przypadku określa zakres parametrów, jak również wszelkie transformacje.
no_improve to liczba całkowita, która zatrzyma wyszukiwanie, jeśli ulepszone parametry nie zostaną odkryte w ciągu iteracji no_improve.
uncertain jest również liczbą całkowitą (lub Inf), używaną do ustalenia liczby przejść algorytmu wg reguły eksploatacji bez poprawy, aby następnie wybrać próbę z zakresu z wysoką wariancją, po to żeby dokonać eksploracji.
verbose jest parametrem, który decyduje co będzie się wyświetlało podczas przebiegu algorytmu.
Użyjmy pierwszych wyników SVM jako początkowego podłoża dla modelu GP. Przypomnijmy, że w tym zastosowaniu chcemy zmaksymalizować obszar pod krzywą ROC.
Kod
ctrl<-control_bayes(verbose =TRUE)set.seed(1403)svm_bo<-svm_wflow%>%tune_bayes( resamples =cell_folds, metrics =roc_res, initial =svm_initial, param_info =svm_param, iter =25, control =ctrl)
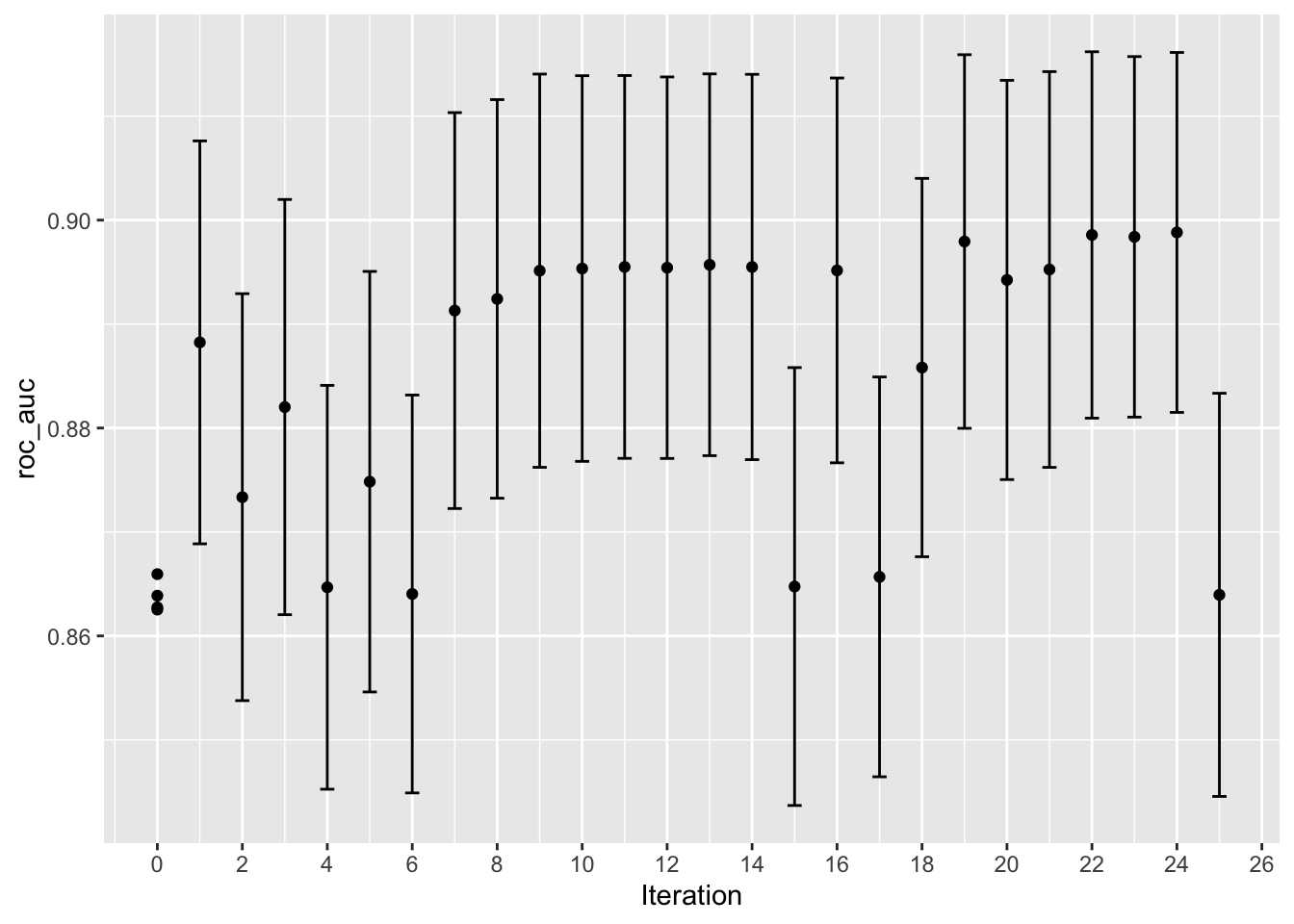
Rys. 12.6: Jakość dopasowania modelu w poszczególnych iteracjach OB
Poniższa animacja wizualizuje wyniki wyszukiwania. Czarne “x” pokazują wartości początkowe zawarte w svm_initial. Niebieski panel u góry po lewej stronie pokazuje przewidywaną średnią wartość obszaru pod krzywą ROC. Czerwony panel na górze po prawej stronie pokazuje przewidywaną zmienność wartości ROC, podczas gdy dolny wykres wizualizuje oczekiwaną poprawę. W każdym panelu ciemniejsze kolory wskazują mniej atrakcyjne wartości (np. małe wartości średnie, duże zróżnicowanie i małe ulepszenia).
Rys. 12.7: Przykład działania optymalizacji bayesowskiej
Powierzchnia przewidywanej średniej jest bardzo niedokładna w pierwszych kilku iteracjach wyszukiwania. Pomimo tego, pomaga ona poprowadzić proces w rejon dobrej wydajności. W ciągu pierwszych dziesięciu iteracji, wyszukiwanie jest dokonywane w pobliżu optymalnego miejsca.
Podczas gdy najlepsza kombinacja dostrajania parametrów znajduje się na granicy przestrzeni parametrów, optymalizacja bayesowska często wybierze nowe punkty poza granicami przestrzeni parametrów.
Powyższy przykład startował z punktów startowych wybranych nieco arbitralnie ale nieco lepsze wyniki można osiągnąć stosując losowe wypełnienie przestrzeni parametrów.
12.2 Symulowane wyżarzanie
Symulowane wyżarzanie (ang. simulated annealing) (Kirkpatrick, Gelatt, i Vecchi 1983; Laarhoven i Aarts 1987); jest nieliniową procedurą wyszukiwania zainspirowaną procesem stygnięcia metalu. Jest to metoda globalnego wyszukiwania, która może efektywnie poruszać się po wielu różnych obszarach poszukiwań, w tym po funkcjach nieciągłych. W przeciwieństwie do większości procedur optymalizacji opartych na gradiencie, symulowane wyżarzanie może ponownie ocenić poprzednie rozwiązania.
Proces użycia symulowanego wyżarzania rozpoczyna się od wartości początkowej i rozpoczyna kontrolowany losowy spacer przez przestrzeń parametrów. Każda nowa wartość parametru-kandydata jest niewielką perturbacją poprzedniej wartości, która utrzymuje nowy punkt w lokalnym sąsiedztwie.
Punkt kandydujący jest oceniana przy zastosowaniu resamplingu, aby uzyskać odpowiadającą mu wartość wydajności. Jeśli osiąga ona lepsze wyniki niż poprzednie parametry, jest akceptowana jako nowa najlepsza i proces jest kontynuowany. Jeśli wyniki są gorsze niż poprzednia wartość, procedura wyszukiwania może nadal używać tego parametru do określenia dalszych kroków. Zależy to od dwóch czynników. Po pierwsze, prawdopodobieństwo zatrzymania złego kandydata maleje wraz z pogorszeniem się wyników. Innymi słowy, tylko nieco gorszy wynik od obecnie najlepszego ma większą szansę na akceptację niż ten z dużym spadkiem wydajności. Drugim czynnikiem jest liczba iteracji wyszukiwania. Symulowane wyżarzanie próbuje zaakceptować mniej suboptymalnych wartości w miarę postępu wyszukiwania. Z tych dwóch czynników prawdopodobieństwo akceptacji złego wyniku można sformalizować jako:
gdzie \(i\) jest numerem iteracji, \(c\) jest stałą określoną przez użytkownika, \(D_i\) jest procentową różnicą pomiędzy starą i nową wartością (gdzie wartości ujemne oznaczają gorsze wyniki). Dla złego wyniku określamy prawdopodobieństwo akceptacji i porównujemy je z liczbą wylosowaną z rozkładu jednostajnego. Jeśli liczba ta jest większa od wartości prawdopodobieństwa, wyszukiwanie odrzuca bieżące parametry i następna iteracja tworzy swoją wartość kandydata w sąsiedztwie poprzedniej wartości. W przeciwnym razie następna iteracja tworzy kolejny zestaw parametrów na podstawie bieżących (suboptymalnych) wartości.
Zagrożenie
Prawdopodobieństwa akceptacji symulowanego wyżarzania pozwalają na postępowanie w złym kierunku, przynajmniej na krótką metę, z potencjałem znalezienia znacznie lepszego regionu przestrzeni parametrów w dłuższej perspektywie.
Mapa ciepła na Rys. 12.8 pokazuje, jak prawdopodobieństwo akceptacji może się zmieniać w zależności od iteracji, wydajności i współczynnika określonego przez użytkownika.
Rys. 12.8: Mapa ciepła prawdopodobieństwa akceptacji symulowanego wyżarzania dla różnych wartości współczynnika
Użytkownik może dostosować współczynniki \(c\), aby znaleźć profil prawdopodobieństwa, który odpowiada jego potrzebom. W finetune::control_sim_anneal(), domyślnym dla tego argumentu cooling_coef jest 0.02. Zmniejszenie tego współczynnika zachęci wyszukiwanie do bycia bardziej wyrozumiałym dla słabych wyników.
Proces ten trwa przez określoną ilość iteracji, ale może zostać zatrzymany, jeśli w ciągu określonej liczby iteracji nie pojawią się globalnie najlepsze wyniki. Bardzo pomocne może być ustawienie progu restartu. Jeśli wystąpi ciąg niepowodzeń, funkcja ta powraca do ostatnich globalnie najlepszych ustawień parametrów i zaczyna od nowa.
Najważniejszym szczegółem jest określenie sposobu perturbacji parametrów dostrajania z iteracji na iterację. W literaturze można znaleźć wiele metod na to. My stosujemy metodę podaną przez Bohachevsky, Johnson, i Stein (1986) zwaną uogólnionym symulowanym wyżarzaniem. Dla ciągłych parametrów dostrajania definiujemy mały promień, aby określić lokalne “sąsiedztwo”. Na przykład załóżmy, że są dwa parametry dostrajania i każdy z nich jest ograniczony przez zero i jeden. Proces symulowanego wyżarzania generuje losowe wartości na otaczającym promieniu i losowo wybiera jedną z nich jako aktualną wartość kandydacką.
Wielkość promienia kontroluje, jak szybko wyszukiwanie bada przestrzeń parametrów. Im większy jest promień tym szybciej przestrzeń parametrów będzie przeszukiwana przez algorytm ale jednocześnie mniej dokładnie.
Dla zilustrowania użyjemy dwóch głównych parametrów dostrajania glmnet:
Wielkość kary (penalty). Domyślny zakres tego parametru to od \(10^{-10}\) do \(10^0\). Najczęściej jest podawany w skali logarytmicznej o podstawie 10.
Proporcja kary lasso (mixture) - wartość pomiędzy 0 i 1 określająca balans pomiędzy karą L1 i L2.
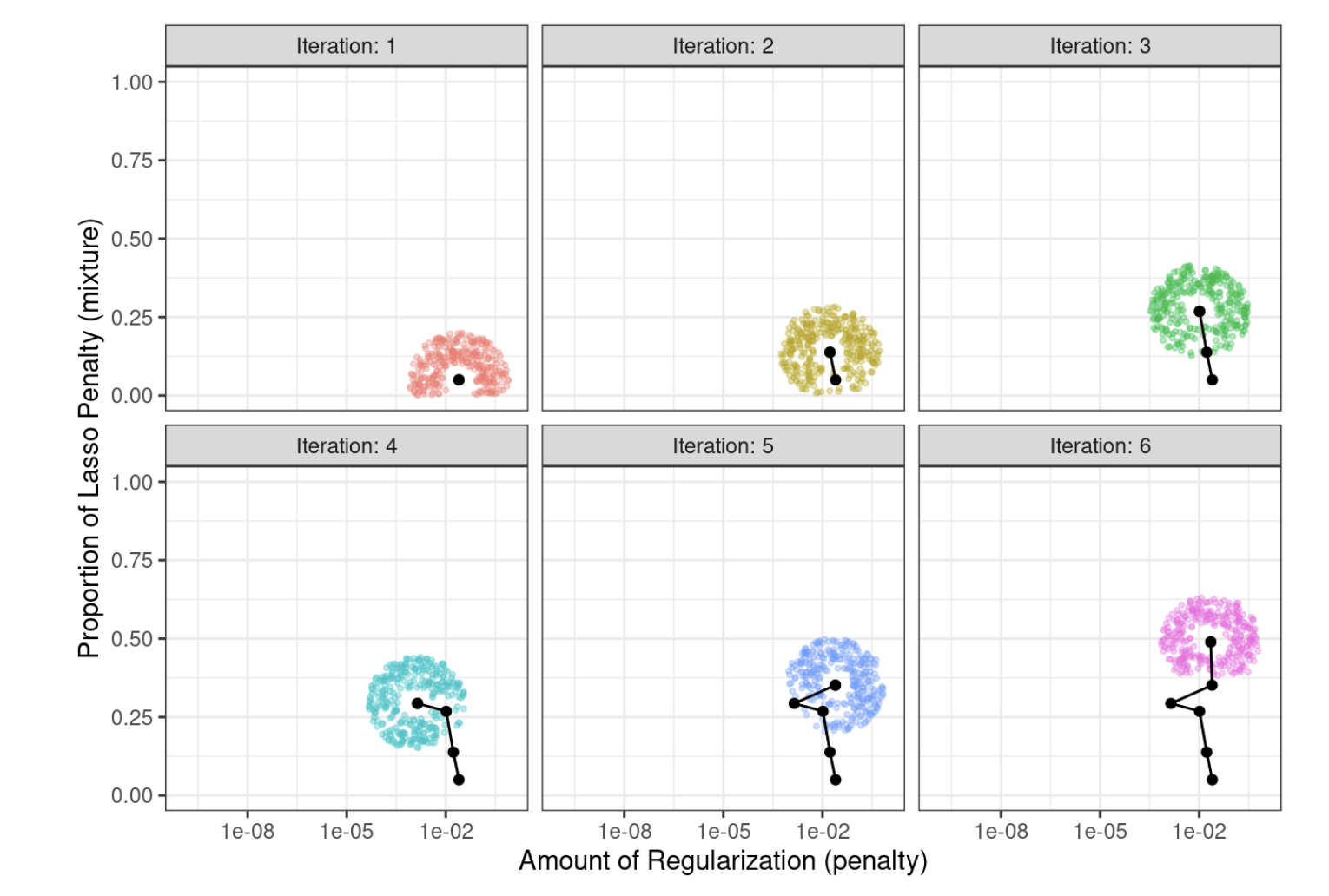
Proces rozpoczyna się od wartości początkowych penalty = 0,025 i mixture = 0,050. Używając promienia, który losowo waha się między 0,050 a 0,015, dane są odpowiednio skalowane, losowe wartości są generowane na promieniach wokół punktu początkowego, a następnie jedna jest losowo wybierana jako kandydat. Dla ilustracji przyjmiemy, że wszystkie wartości kandydujące faktycznie poprawiają wydajność modelu. Korzystając z nowej wartości, generowany jest zestaw nowych losowych sąsiadów, wybierany jest jeden, i tak dalej. Rys. 12.9 przedstawia sześć iteracji sukcesywnie podążających do lewego górnego rogu.
Rys. 12.9: Kilka iteracji procesu symulowanego wyżarzania
Zauważmy, że podczas niektórych iteracji zestawy kandydatów wzdłuż promienia wykluczają punkty poza granicami parametrów. Ponadto, nasza implementacja przesuwa wybór kolejnych konfiguracji dostrajania parametrów od nowych wartości, które są bardzo podobne do poprzednich konfiguracji.
Dla parametrów kategorycznych i całkowitych, każdy z nich jest generowany z określonym wcześniej prawdopodobieństwem. Argument flip w control_sim_anneal() może być użyty do określenia tego prawdopodobieństwa. Dla parametrów całkowitoliczbowych, używana jest najbliższa wartość całkowita.
Przeszukiwanie metodą symulowanego wyżarzania może nie być optymalna w przypadku, gdy wiele parametrów jest nienumerycznych lub całkowitoliczbowych o niewielu unikalnych wartościach. W tych przypadkach jest prawdopodobne, że ten sam zestaw kandydatów może być testowany więcej niż raz.
Aby zaimplementować wyszukiwanie iteracyjne poprzez symulowane wyżarzanie, użyj funkcji tune_sim_anneal(). Składnia tej funkcji jest niemal identyczna jak tune_bayes(). Nie ma żadnych opcji dotyczących funkcji akwizycji czy próbkowania niepewności. Funkcja control_sim_anneal() posiada pewne szczegóły, które definiują lokalne sąsiedztwo i harmonogram chłodzenia:
no_improve jest liczbą całkowitą, która zatrzyma wyszukiwanie, jeśli w ciągu iteracji określonym przez no_improve nie zostaną odkryte globalnie najlepsze wyniki. Przyjęte suboptymalne lub odrzucone parametry liczą się jako “brak poprawy”.
restart to liczba iteracji, która musi minąć bez poprawy jakości modelu, po której następuje przejście do najlepszego poprzednio ustalonego zestawu parametrów.
radius to wektor liczbowy w przedziale (0, 1), który określa minimalny i maksymalny promień lokalnego sąsiedztwa wokół punktu początkowego.
flip to wartość prawdopodobieństwa określająca szanse zmiany wartości parametrów kategorycznych lub całkowitych.
cooling_coef jest współczynnikiem \(c\) w \(\exp(c\times D_i \times i)\), który moduluje jak szybko prawdopodobieństwo akceptacji maleje w trakcie iteracji. Większe wartości cooling_coef zmniejszają prawdopodobieństwo akceptacji suboptymalnego ustawienia parametrów.
Dla danych dotyczących segmentacji komórek składnia jest bardzo spójna z poprzednio stosowanymi funkcjami:
Kod
ctrl_sa<-control_sim_anneal(verbose =TRUE, no_improve =10L)set.seed(1404)svm_sa<-svm_wflow%>%tune_sim_anneal( resamples =cell_folds, metrics =roc_res, initial =svm_initial, param_info =svm_param, iter =50, control =ctrl_sa)
Tab. 12.6: Najlepsze kombinacje parametrów na podstawie SA
cost
rbf_sigma
.metric
.estimator
mean
n
std_err
.config
.iter
16.749920
0.002398614
roc_auc
binary
0.8985179
10
0.007916078
Iter35
35
10.629737
0.004059190
roc_auc
binary
0.8975137
10
0.008203966
Iter45
45
21.940934
0.001216970
roc_auc
binary
0.8973481
10
0.008280488
Iter37
37
9.413835
0.002056779
roc_auc
binary
0.8971685
10
0.008342496
Iter34
34
3.110379
0.004869128
roc_auc
binary
0.8969694
10
0.008168916
Iter41
41
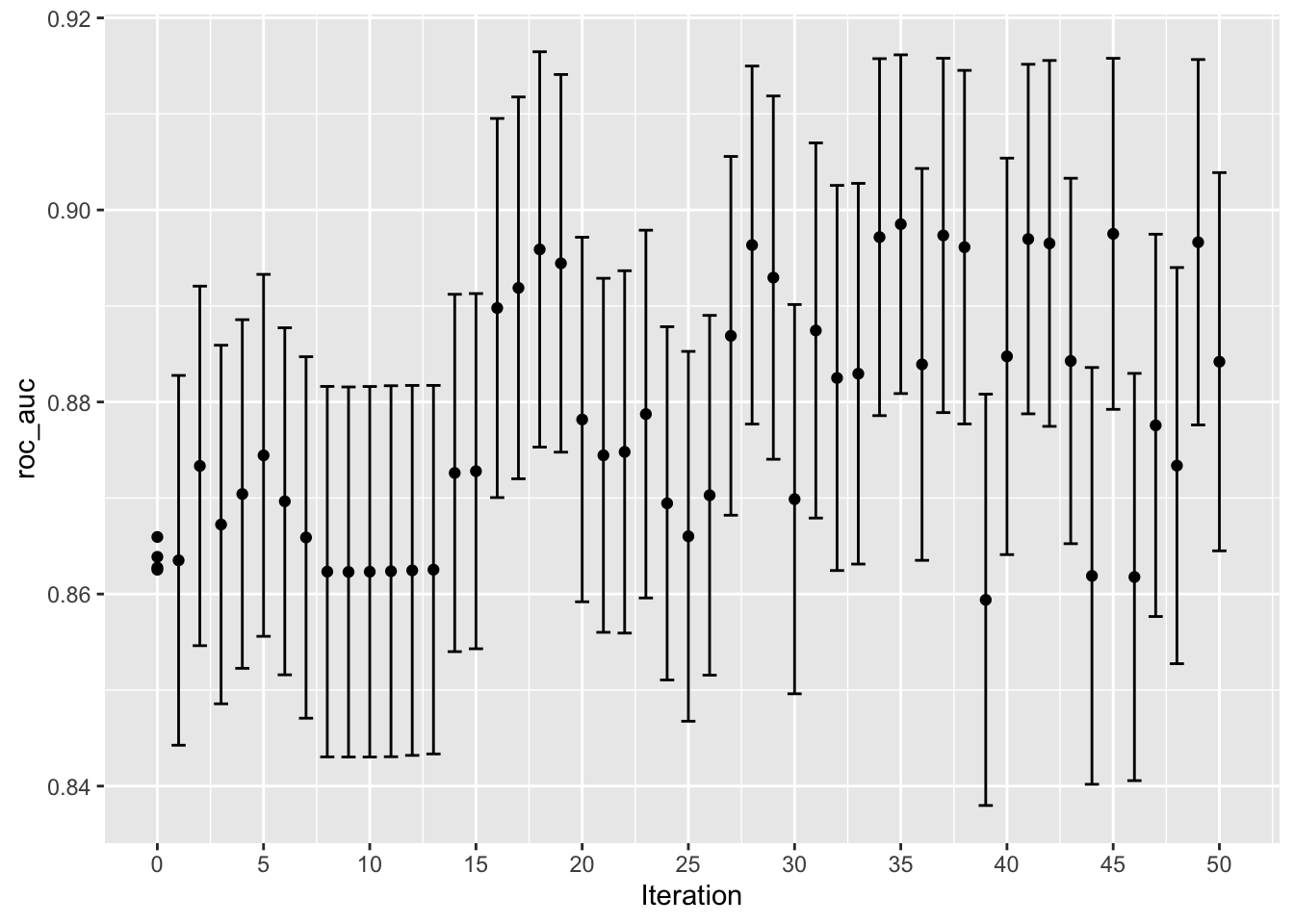
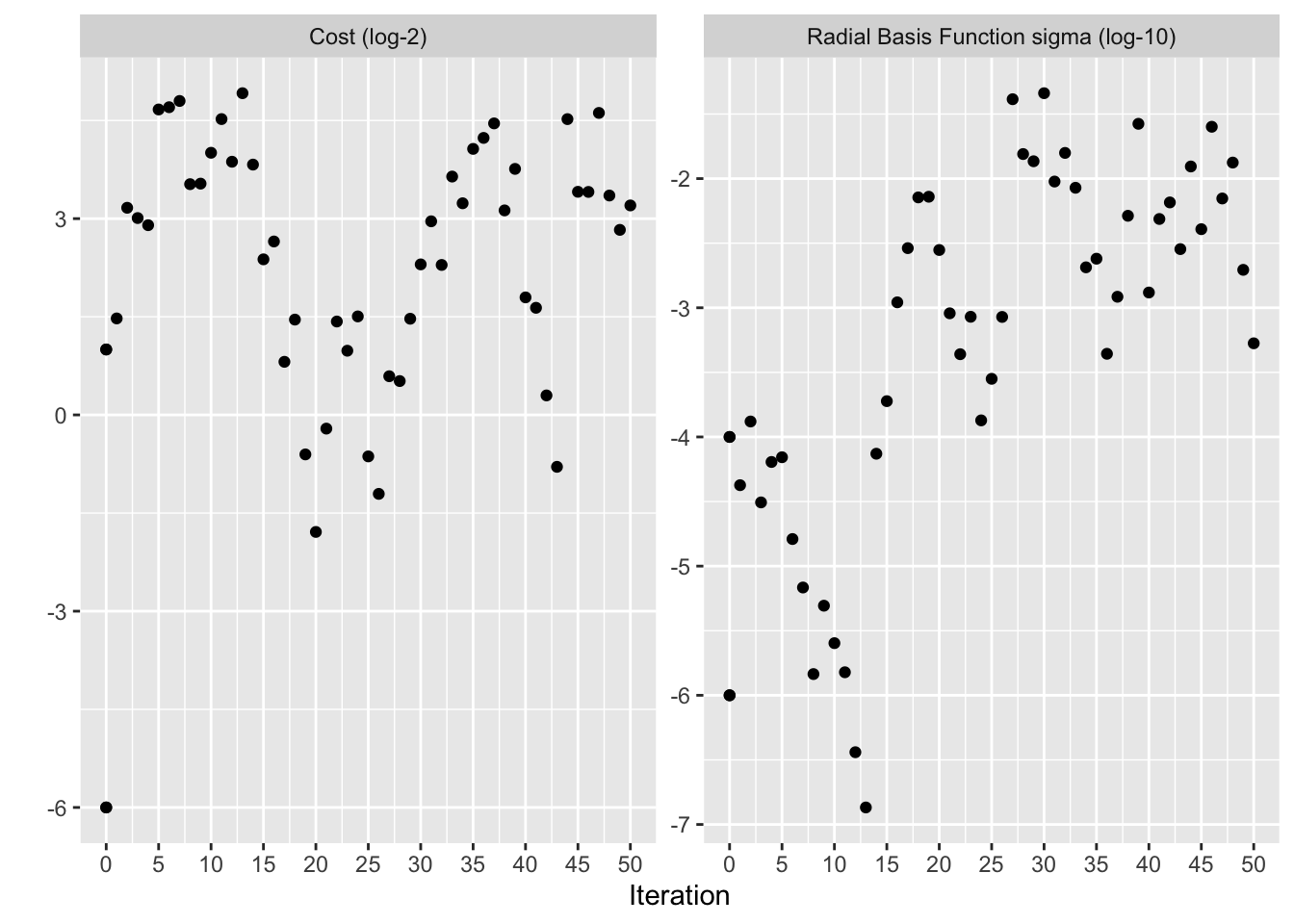
Podobnie jak w przypadku innych funkcji tune_*(), odpowiadająca im funkcja autoplot() tworzy wizualną ocenę wyników. Użycie autoplot(svm_sa, type = "performance") pokazuje wydajność w czasie iteracji (Rys. 12.10), podczas gdy autoplot(svm_sa, type = "parameters") przedstawia wydajność w zależności od konkretnych wartości dostrajania parametrów (Rys. 12.11).
Bohachevsky, Ihor O., Mark E. Johnson, i Myron L. Stein. 1986. „Generalized Simulated Annealing for Function Optimization”. Technometrics 28 (3): 209–17. https://doi.org/10.1080/00401706.1986.10488128.
Schulz, Eric, Maarten Speekenbrink, i Andreas Krause. 2016. „A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions”. http://dx.doi.org/10.1101/095190.
Shahriari, Bobak, Kevin Swersky, Ziyu Wang, Ryan P. Adams, i Nando de Freitas. 2016. „Taking the Human Out of the Loop: A Review of Bayesian Optimization”. Proceedings of the IEEE 104 (1): 148–75. https://doi.org/10.1109/jproc.2015.2494218.