

Kod
library(tidymodels)
tidymodels_prefer()
coef_penalty <- 0.1
spec <- linear_reg(penalty = coef_penalty) %>% set_engine("glmnet")Poszukiwanie optymalnego modelu za pomocą siatek parametrów jest czynnością żmudną i zajmuje sporo czasu. Same funkcje pakietu tune są już w pewnym stopniu zoptymalizowane pod kątem poszukiwania najlepszych rozwiązań. W przypadku modeli, których parametry można przeszukiwać bazując na wiedzy pochodzącej z wcześniejszych epok estymacji, to funkcje tune z tego korzystają. Przykładowo, dajmy na to, że uczymy model PLS (ang. Partial Least Squares), który co do zasady jest podobny do zastosowania PCA na predyktorach, a następnie przewidywaniu wartości wynikowej, z tą różnicą, że w PLS tworzone składowe są dobierane tak aby zmaksymalizować korelację pomiędzy nimi a zmienną wynikową. Wówczas do obliczenia budowy modelu z 10 składowymi procedura przebiega identycznie jak w modelu z 9 składowymi, z tą różnicą, że dodatkowo ostatnia składowa jest obliczana. Wówczas aby zaoszczędzić czas procedura tuningu modelu względem liczby składowych, których zakres przeszukiwania był powiedzmy [0,10], korzysta ze wspomnianej iteracyjnej metody budowania modelu PLS. To znacząco przyspiesza czas dostrajania modelu. Oczywiście nie wszystkie modele mają tą własność, ale te które mają korzystają z tej procedury nazywanej optymalizacją podprocesów (ang. submodel optimization).
W innych przypadkach, chcąc przyspieszyć procedurę tuningu, musimy stosować paralelizację procedury dostrajania. W pakiecie tune możliwe jest zastosowanie paralelizacji na dwa sposoby. Podczas dostrajania modeli poprzez wyszukiwanie w siatce, istnieją dwie odrębne pętle: jedna nad foldami (zewnętrzna pętla) i druga nad unikalnymi kombinacjami parametrów (wewnętrzna pętla).
Domyślnie pakiet tune paralelizuje tylko nad próbkami (pętla zewnętrzna). Jest to optymalny scenariusz, gdy metody wstępnego przetwarzania (preprocessing) są kosztowne oblczeniowo. Istnieją jednak dwa potencjalne minusy tego podejścia:
Aby zilustrować działanie przetwarzania równoległego, użyjemy przypadku, w którym istnieje 7 wartości parametrów dostrajania modelu, przy 5-krotnej walidacji krzyżowej. Rys. 11.1 pokazuje, jak zadania są przydzielane procesom robotniczym.
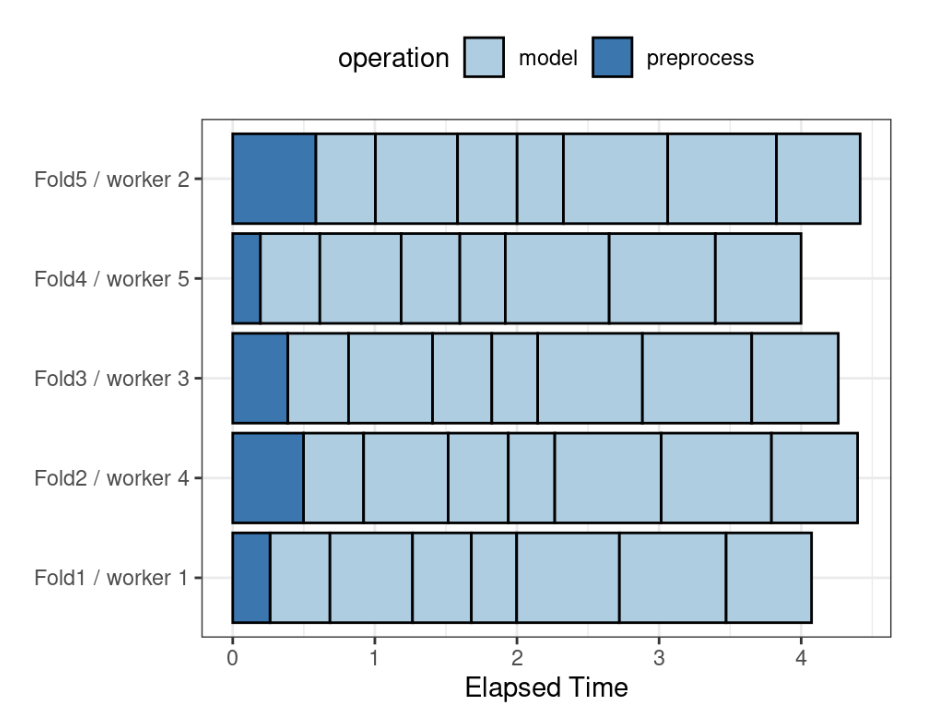
Zauważ, że każdy fold jest przypisany do własnego procesu roboczego, a ponieważ dostrajane są tylko parametry modelu, przetwarzanie wstępne jest przeprowadzane raz na fold/rdzeń. Jeśli użyto by mniej niż pięciu rdzeni, niektóre rdzenie otrzymaliby do przeliczenia kilka foldów.
W funkcjach sterujących tune_*() argument parallel_over kontroluje sposób wykonania procesu. Aby użyć tej strategii paralelizacji, argumentem jest parallel_over = "resamples".
Zamiast równoległego przetwarzania tylko nad zewnętrzną pętlą, alternatywny schemat łączy pętle nad foldami i modelami w jedną pętlę. W tym przypadku paralelizacja występuje teraz nad pojedynczą pętlą. Na przykład, jeśli używamy 5-krotnej walidacji krzyżowej z \(M\) wartościami parametrów dostrajania, pętla jest wykonywana przez \(5 \times M\) iteracji. Zwiększa to liczbę potencjalnych rdzeni, które można wykorzystać. Jednak praca związana ze wstępnym przetwarzaniem danych jest powtarzana wielokrotnie. Jeśli te kroki są wymagające obliczeniowo, to podejście to będzie nieefektywne. W tidymodels, zestawy walidacyjne są traktowane jako pojedynczy fold. W takich przypadkach ten schemat paralelizacji byłby najlepszy.
Rys. 11.2 ilustruje delegowanie zadań do robotników w tym schemacie; użyty jest ten sam przykład, ale z 10 rdzeniami.
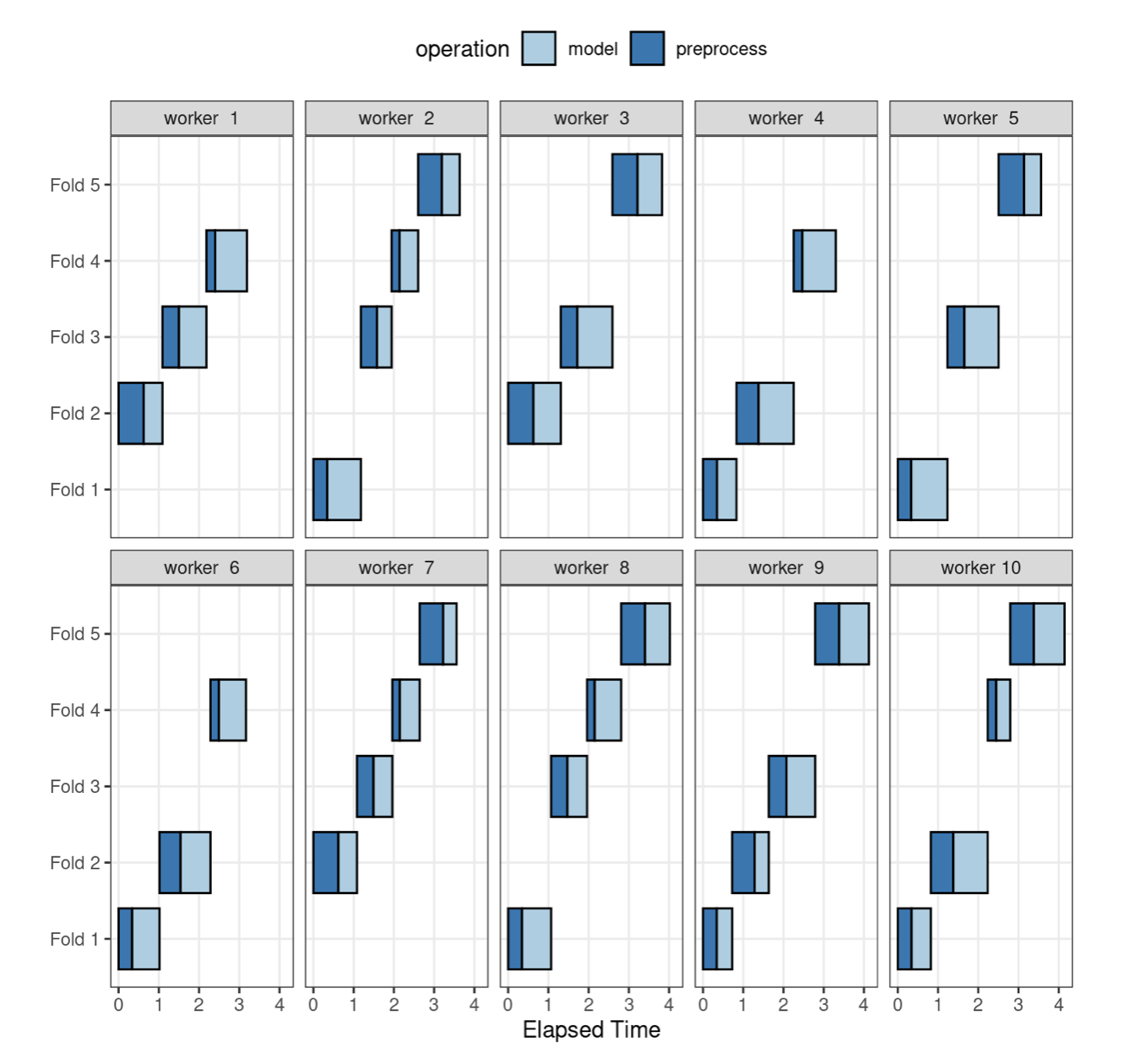
Tutaj każdy proces roboczy obsługuje wiele foldów, a przetwarzanie wstępne jest niepotrzebnie powtarzane. Na przykład, dla pierwszego foldu, preprocessing został wykonany siedem razy zamiast raz. Dla tego schematu argumentem funkcji sterującej jest parallel_over = "everything".
Aby porównać różne schematy paralelizacji, dostroiliśmy drzewo wzmacniane za pomocą silnika xgboost, używając zestawu danych składającego się z 4000 próbek, z 5-krotną walidacją krzyżową i 10 modelami kandydującymi. Dane te wymagały pewnego podstawowego przetwarzania wstępnego. Przetwarzanie wstępne było obsługiwane na trzy różne sposoby:
dplyr poza przepisami (oznaczone jako “none” w późniejszych wykresach).Oceniliśmy ten proces przy użyciu zmiennej liczby rdzeni i przy użyciu dwóch opcji parallel_over, na komputerze z 10 fizycznymi rdzeniami i 20 wirtualnymi rdzeniami (poprzez hyper-threading). Najpierw rozważmy surowe czasy wykonania na Rys. 11.3.
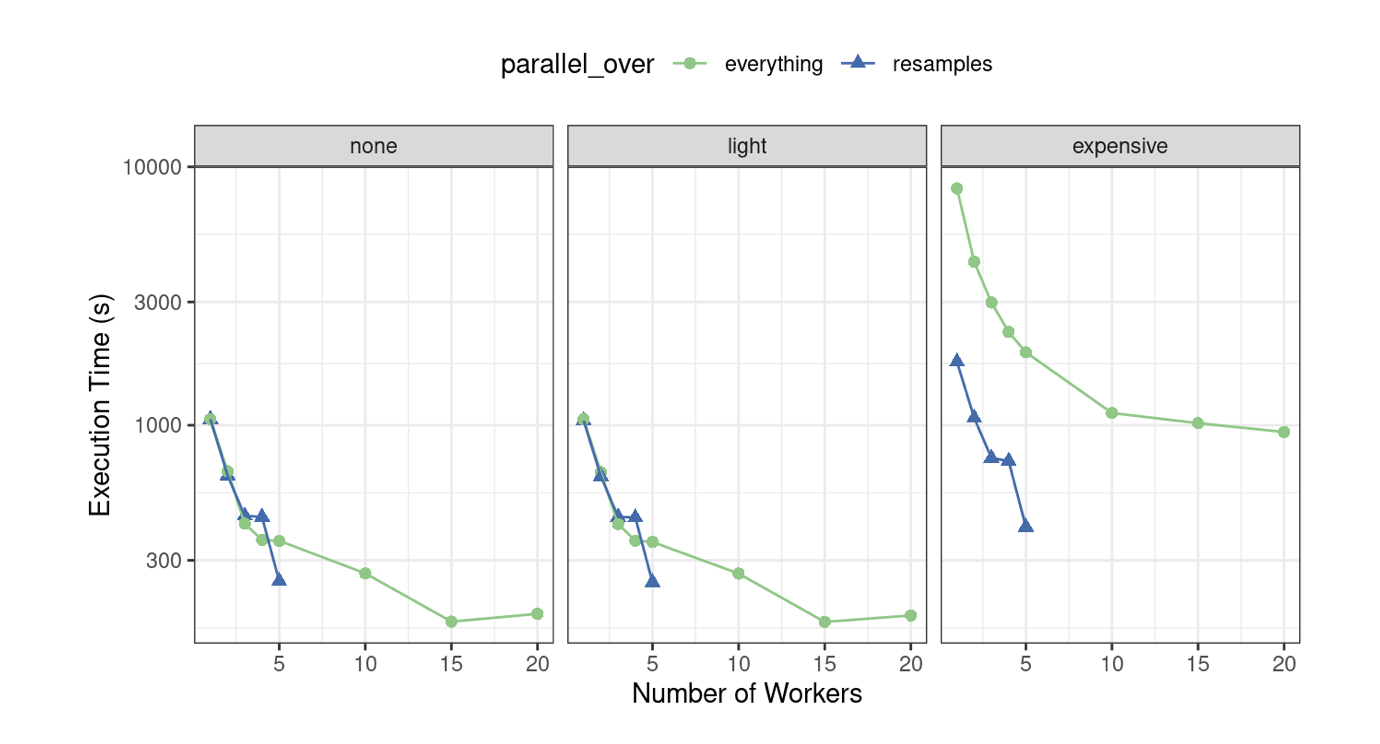
Ponieważ było tylko pięć foldów, liczba rdzeni używanych, gdy parallel_over = "resamples" jest ograniczona do pięciu. Porównanie krzywych w pierwszych dwóch panelach dla “none” i “light” daje następujące wnioski:
parallel_over = "wszystko" z wieloma rdzeniami. Jednak, jak widać na Rys. 11.3, większość korzyści z przetwarzania równoległego występuje w pierwszych pięciu rdzeniach.W przypadku z drogim krokiem wstępnego przetwarzania, istnieje znaczna różnica w czasach wykonywania. Użycie parallel_over = "everything" jest problematyczne, ponieważ nawet przy użyciu wszystkich rdzeni, nigdy nie osiąga czasu wykonania, który parallel_over = "everything" osiąga przy użyciu tylko pięciu rdzeni. Dzieje się tak dlatego, że kosztowny krok wstępnego przetwarzania jest niepotrzebnie powtarzany w schemacie obliczeniowym.
Na Rys. 11.4 możemy również obejrzeć te dane w kategoriach przyrostu prędkości.
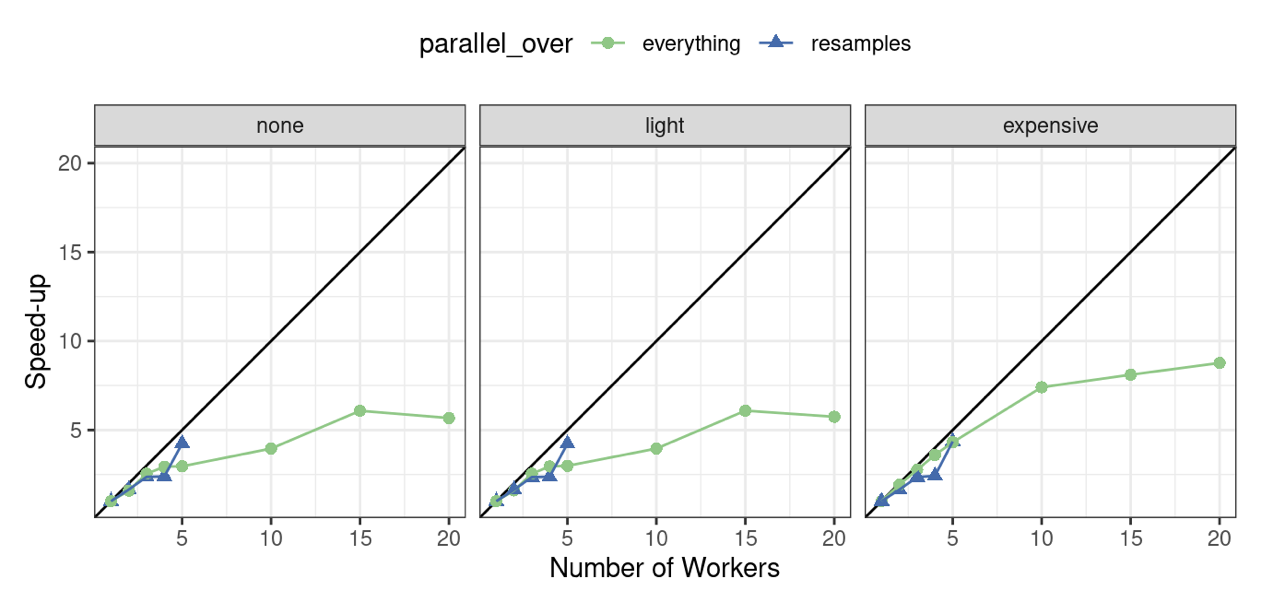
Najlepsze przyspieszenie pracy, dla tych danych, występują, gdy parallel_over = "resamples" i gdy obliczenia wstępne są drogie. Jednak w tym ostatnim przypadku należy pamiętać, że poprzednia analiza wskazuje, że ogólne dopasowanie modelu jest wolniejsze.
Jaka jest korzyść z zastosowania metody optymalizacji submodelu w połączeniu z przetwarzaniem równoległym? Model klasyfikacyjny C5.0 został również uruchomiony równolegle przy użyciu dziesięciu rdzeni. Obliczenia równoległe zajęły 13,3 sekundy, co oznacza 7,5-krotne przyspieszenie (w obu przypadkach zastosowano sztuczkę optymalizacji submodelu). Dzięki sztuczce optymalizacji podmodelu i przetwarzaniu równoległemu uzyskano 282-krotny wzrost prędkości w stosunku do najbardziej podstawowego kodu przeszukiwania siatki.
Należy pamiętać, że korzyść z wykonywania równoległych obliczeń dla modeli zoptymalizowanych obliczeniowo nie będzie tak duża, jak dla modeli niezoptymalizowanych.
Jeśli definiujemy zmienną, która ma być użyta jako parametr modelu, a następnie przekazujemy ją do funkcji takiej jak linear_reg(), zmienna ta jest zazwyczaj zdefiniowana w środowisku globalnym.
library(tidymodels)
tidymodels_prefer()
coef_penalty <- 0.1
spec <- linear_reg(penalty = coef_penalty) %>% set_engine("glmnet")Modele utworzone za pomocą pakietu parsnip zapisują argumenty takie jak te jako quosures; są to obiekty śledzące zarówno nazwę obiektu, jak i środowisko, w którym istnieje:
spec$args$penalty<quosure>
expr: ^coef_penalty
env: globalZauważ, że mamy env: global, ponieważ ta zmienna została utworzona w środowisku globalnym. Specyfikacja modelu zdefiniowana przez spec działa poprawnie, gdy jest uruchamiana w zwykłej sesji użytkownika, ponieważ sesja ta również korzysta ze środowiska globalnego; R może łatwo znaleźć obiekt coef_penalty. Kiedy taki model jest szacowany z równoległymi rdzeniami, może zawieść. W zależności od konkretnej technologii, która jest używana do przetwarzania równoległego, rdzenie mogą nie mieć dostępu do globalnego środowiska. Podczas pisania kodu, który będzie uruchamiany równolegle, dobrym pomysłem jest wstawianie rzeczywistych danych do obiektów, a nie referencji do obiektu. Pakiety rlang i dplyr mogą być w tym bardzo pomocne. Na przykład, operator !! może wstawić pojedynczą wartość do obiektu:
spec <- linear_reg(penalty = !!coef_penalty) %>% set_engine("glmnet")
spec$args$penalty<quosure>
expr: ^0.1
env: emptyTeraz wyjście to ^0,1, wskazując, że jest to wartość zamiast odniesienia do obiektu. Kiedy masz wiele zewnętrznych wartości do wstawienia do obiektu, operator !!! może pomóc:
mcmc_args <- list(chains = 3, iter = 1000, cores = 3)
linear_reg() %>% set_engine("stan", !!!mcmc_args)Linear Regression Model Specification (regression)
Engine-Specific Arguments:
chains = 3
iter = 1000
cores = 3
Computational engine: stan Selektory receptur to kolejne miejsce, w którym możesz chcieć uzyskać dostęp do zmiennych globalnych. Załóżmy, że masz krok receptury, który powinien użyć wszystkich predyktorów w danych komórkowych (cells), które zostały zmierzone za pomocą drugiego kanału optycznego. Możemy utworzyć wektor tych nazw kolumn:
library(stringr)
ch_2_vars <- str_subset(names(cells), "ch_2")
ch_2_vars[1] "avg_inten_ch_2" "total_inten_ch_2"Moglibyśmy twardo zakodować je w kroku receptury, ale lepiej byłoby odwołać się do nich programowo na wypadek zmiany danych. Mamy dwa sposoby, aby to zrobić to:
Ten ostatni jest lepszy dla przetwarzania równoległego, ponieważ wszystkie potrzebne informacje są osadzone w obiekcie receptury.
Jednym z problemów z przeszukiwaniem siatki jest to, że wszystkie modele muszą być dopasowane we wszystkich foldach, zanim jakiekolwiek dostrajanie parametrów może być ocenione. Byłoby pomocne, gdyby zamiast tego, w pewnym momencie podczas dostrajania parametrów, można było przeprowadzić analizę przejściową w celu wyeliminowania wszelkich naprawdę bezużytecznych kandydatów na parametry. Byłoby to podobne do analizy daremności w badaniach klinicznych. Jeśli nowy lek działa zbyt słabo (lub dobrze), to potencjalnie nieetyczne jest czekanie na zakończenie badania, by podjąć decyzję.
W uczeniu maszynowym podobną funkcję zapewnia zbiór technik zwanych metodami wyścigowymi (ang. racing method) (Maron i Moore 1993). W tym przypadku proces strojenia ocenia wszystkie modele na początkowym podzbiorze foldów. W oparciu o wartości metryk wydajności, niektóre zestawy parametrów nie są brane pod uwagę w kolejnych etapach dostrajania.
Na przykład, w procesie tuningu perceptronu wielowarstwowego z siatką regularną, badamy jak wyglądałyby wyniki tylko po pierwszych trzech foldach? Używając technik podobnych do tych z rozdziału o porównywaniu modeli, możemy dopasować model, w którym zmienną wynikową jest obszar pod krzywą ROC, a predyktorem jest wskaźnik dla kombinacji parametrów. Model uwzględnia efekt resample-to-resample i tworzy oszacowania punktowe i przedziałowe dla każdej kombinacji parametrów. Wynikiem modelu są jednostronne 95% przedziały ufności, które mierzą stratę wartości ROC w stosunku do aktualnie najlepiej działających parametrów, jak pokazano na rysunku 13.9.
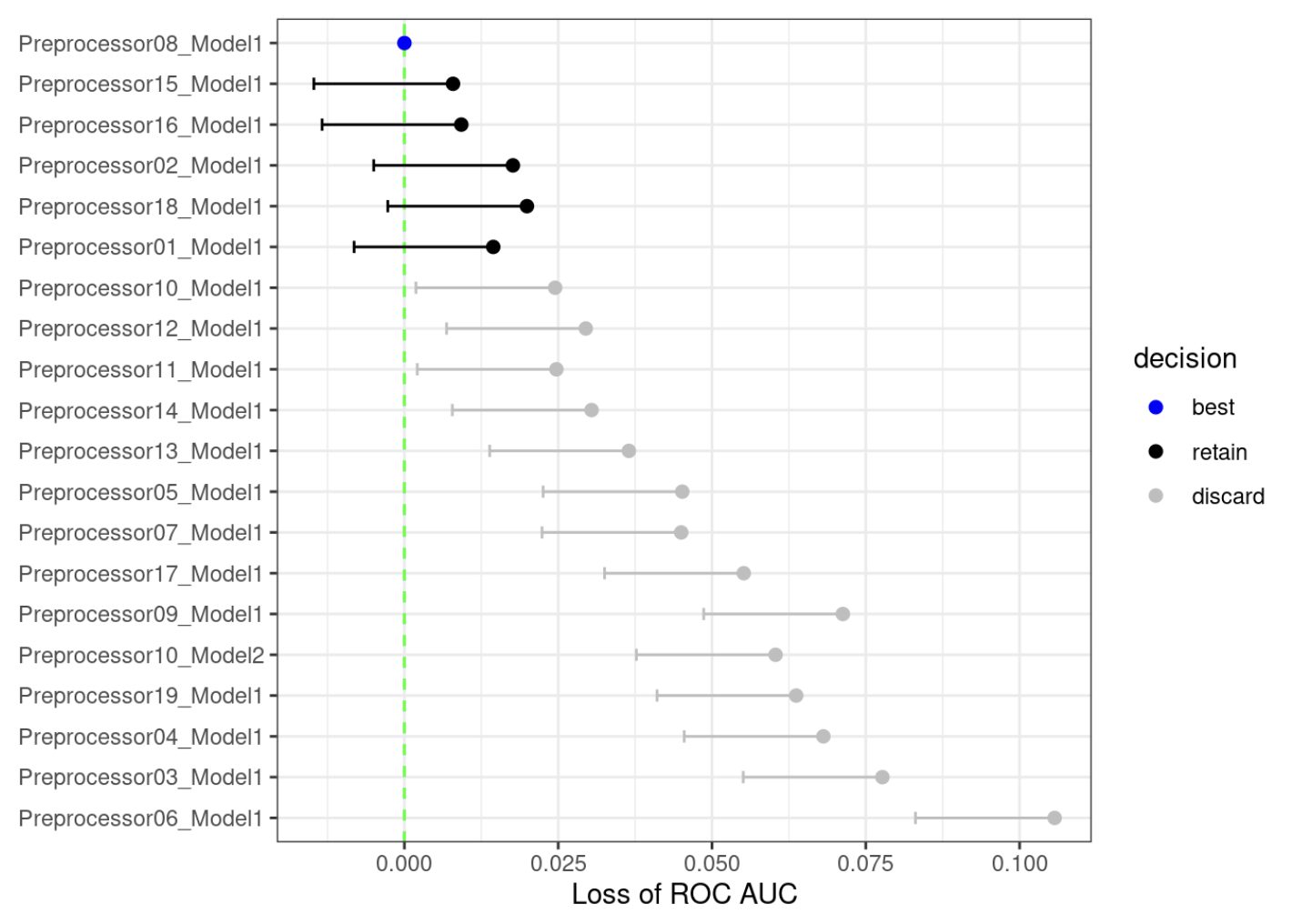
Każdy zestaw parametrów, którego przedział ufności zawiera zero, nie daje podstaw by twierdzić, że jego wydajność jest statystycznie różna od najlepszych wyników. Zachowujemy 6 najlepszych ustawień i są one ponownie próbkowane. Pozostałe 14 podmodeli nie jest już rozpatrywane.
Metody wyścigowe mogą być bardziej efektywne niż podstawowe przeszukiwanie siatki, o ile analiza pośrednia jest szybka, a niektóre ustawienia parametrów mają słabą wydajność. Jest to również najbardziej pomocne, gdy model nie ma możliwości wykorzystania predykcji submodelu.
Pakiet finetune zawiera funkcje dla metody wyścigowej. Funkcja tune_race_anova() przeprowadza model ANOVA w celu przetestowania statystycznej istotności różnych konfiguracji modelu. Składnia pozwalająca odtworzyć pokazane wcześniej filtrowanie to:
library(finetune)
mlp_spec <-
mlp(hidden_units = tune(), penalty = tune(), epochs = tune()) %>%
set_engine("nnet", trace = 0) %>%
set_mode("classification")
mlp_param <- extract_parameter_set_dials(mlp_spec)
data(cells)
cells <- cells %>% select(-case)
set.seed(1304)
cell_folds <- vfold_cv(cells)
mlp_rec <-
recipe(class ~ ., data = cells) %>%
step_YeoJohnson(all_numeric_predictors()) %>%
step_normalize(all_numeric_predictors()) %>%
step_pca(all_numeric_predictors(), num_comp = tune()) %>%
step_normalize(all_numeric_predictors())
mlp_wflow <-
workflow() %>%
add_model(mlp_spec) %>%
add_recipe(mlp_rec)
mlp_param <-
mlp_wflow %>%
extract_parameter_set_dials() %>%
update(
epochs = epochs(c(50, 200)),
num_comp = num_comp(c(0, 40))
)
roc_res <- metric_set(roc_auc)
set.seed(1308)
mlp_sfd_race <-
mlp_wflow %>%
tune_race_anova(
cell_folds,
grid = 20,
param_info = mlp_param,
metrics = roc_res,
control = control_race(verbose_elim = TRUE)
)Argumenty są odzwierciedleniem argumentów funkcji tune_grid(). Funkcja control_race() posiada opcje dotyczące procedury eliminacji. Jak pokazano na powyższej animacji, rozważane były dwie kombinacje parametrów po ocenie pełnego zestawu próbek. show_best() zwraca najlepsze modele (uszeregowane według wydajności), ale zwraca tylko konfiguracje, które nigdy nie zostały wyeliminowane:
show_best(mlp_sfd_race, n = 10)# A tibble: 10 × 10
hidden_units penalty epochs num_comp .metric .estimator mean n std_err
<int> <dbl> <int> <int> <chr> <chr> <dbl> <int> <dbl>
1 4 1.26e- 3 112 9 roc_auc binary 0.893 4 0.0102
2 8 8.14e- 1 177 15 roc_auc binary 0.890 10 0.00966
3 5 1.30e-10 89 5 roc_auc binary 0.889 5 0.0106
4 1 7.08e- 9 106 24 roc_auc binary 0.888 3 0.00379
5 3 1.23e- 1 55 36 roc_auc binary 0.888 3 0.00662
6 2 7.91e- 4 164 7 roc_auc binary 0.883 5 0.0123
7 5 4.91e- 7 132 12 roc_auc binary 0.883 4 0.0103
8 7 6.53e- 8 69 18 roc_auc binary 0.883 3 0.00932
9 2 7.99e- 3 161 32 roc_auc binary 0.882 3 0.0125
10 3 4.02e- 2 151 10 roc_auc binary 0.881 7 0.0154
# ℹ 1 more variable: .config <chr>Istnieją również inne techniki analizy pośredniej do odrzucania pewnych konfiguracji parametrów.
