W celu przedstawienia zasad próbkowania przytoczymy przykład z zestawem danych ames, na którym dokonywaliśmy już modelowania (regresja liniowa)1. Oprócz modelu liniowego zbudujemy również las losowy, który jest bardzo elastycznym modelem nie wymagającym wstępnego przetwarzania.
1 z przykładu w poprzednim rozdziale
Przykład 7.1
Kod
library(tidymodels)tidymodels_prefer()set.seed(44)ames<-ames|>mutate(Sale_Price =log10(Sale_Price))ames_split<-initial_split(ames, prop =0.80, strata =Sale_Price)ames_train<-training(ames_split)ames_test<-testing(ames_split)lm_model<-linear_reg()|>set_engine("lm")ames_rec<-recipe(Sale_Price~Neighborhood+Gr_Liv_Area+Year_Built+Bldg_Type+Latitude+Longitude, data =ames_train)%>%step_log(Gr_Liv_Area, base =10)|>step_other(Neighborhood, threshold =0.01, id ="my_id")|>step_dummy(all_nominal_predictors())|>step_interact(~Gr_Liv_Area:starts_with("Bldg_Type_"))|>step_ns(Latitude, Longitude, deg_free =20)lm_wflow<-workflow()|>add_model(lm_model)|>add_recipe(ames_rec)lm_fit<-fit(lm_wflow, ames_train)rf_model<-rand_forest(trees =1000)|>set_engine("ranger")|>set_mode("regression")rf_wflow<-workflow()|>add_formula(Sale_Price~Neighborhood+Gr_Liv_Area+Year_Built+Bldg_Type+Latitude+Longitude)|>add_model(rf_model)rf_fit<-rf_wflow|>fit(data =ames_train)
Ponieważ kilkukrotnie będziemy wywoływać podsumowanie modeli za pomocą metryk, to stworzymy funkcję, którą będziemy mogli stosować wielokrotnie.
Kod
estimate_perf<-function(model, dat){# Capture the names of the `model` and `dat` objectscl<-match.call()obj_name<-as.character(cl$model)data_name<-as.character(cl$dat)data_name<-gsub("ames_", "", data_name)# Estimate these metrics:reg_metrics<-metric_set(rmse, rsq)model|>predict(dat)|>bind_cols(dat|>select(Sale_Price))|>reg_metrics(Sale_Price, .pred)|>select(-.estimator)|>mutate(object =obj_name, data =data_name)}
Aby porównać modele zostaną obliczone miary RMSE i \(R^2\) dla obu modeli na zbiorze uczącym.
Na podstawie powyższych wyników można by wyciągnąć wniosek, że model lasu losowego jest znacznie lepszy, ponieważ obie miary wyraźnie lepsze są w tym przypadku. W taką pułapkę łapie się większość osób stawiających pierwsze kroki w ML. Ale już porównując te modele na próbie testowej widzimy, że różnice pomiędzy modelami się zacierają.
Kod
estimate_perf(rf_fit, ames_test)
# A tibble: 2 × 4
.metric .estimate object data
<chr> <dbl> <chr> <chr>
1 rmse 0.0702 rf_fit test
2 rsq 0.838 rf_fit test
Kod
estimate_perf(lm_fit, ames_test)
# A tibble: 2 × 4
.metric .estimate object data
<chr> <dbl> <chr> <chr>
1 rmse 0.0760 lm_fit test
2 rsq 0.808 lm_fit test
Skąd takie różnice?
Wiele modeli predykcyjnych jest w stanie uczyć się złożonych zależności. W statystyce są one powszechnie określane jako low bias models. Wiele modeli uczenia maszynowego typu black-box ma niski poziom błędu systematycznego, co oznacza, że mogą one odtwarzać złożone relacje. Inne modele (takie jak regresja liniowa/logistyczna, analiza dyskryminacyjna i inne) nie są tak elastyczne i są uważane za modele o wysokim współczynniku błędu (ang. high bias models).
W przypadku modelu o niskim obciążeniu, wysoki stopień zdolności predykcyjnej może czasami spowodować, że model prawie zapamiętuje dane ze zbioru treningowego. Jako oczywisty przykład, można rozważyć model 1-najbliższego sąsiada. Zawsze będzie zapewniał doskonałe przewidywania dla zestawu treningowego, niezależnie od tego, jak dobrze naprawdę działa dla innych zestawów danych. Modele losowego lasu są podobne; predykcja na zbiorze uczącym zawsze spowoduje nieprawdziwie optymistyczne oszacowanie wydajności.
Brak znaczących różnic w dopasowaniu modelu regresji na obu zbiorach wynika z małej złożoności modelu, a co za tym idzie niskiej wariancji modelu.
Powyższy przykład pokazuje, że ocena modeli na zbiorze uczącym nie jest właściwym podejściem, ponieważ może zwrócić zbyt optymistyczny poziom dopasowania. A skoro zbiór testowy nie powinien być używany natychmiast, a predykcja na zbiorze treningowym jest złym pomysłem, to co należy zrobić? Rozwiązaniem są metody ponownego próbkowania (ang. resampling), takie jak walidacja krzyżowa lub zestawy walidacyjne.
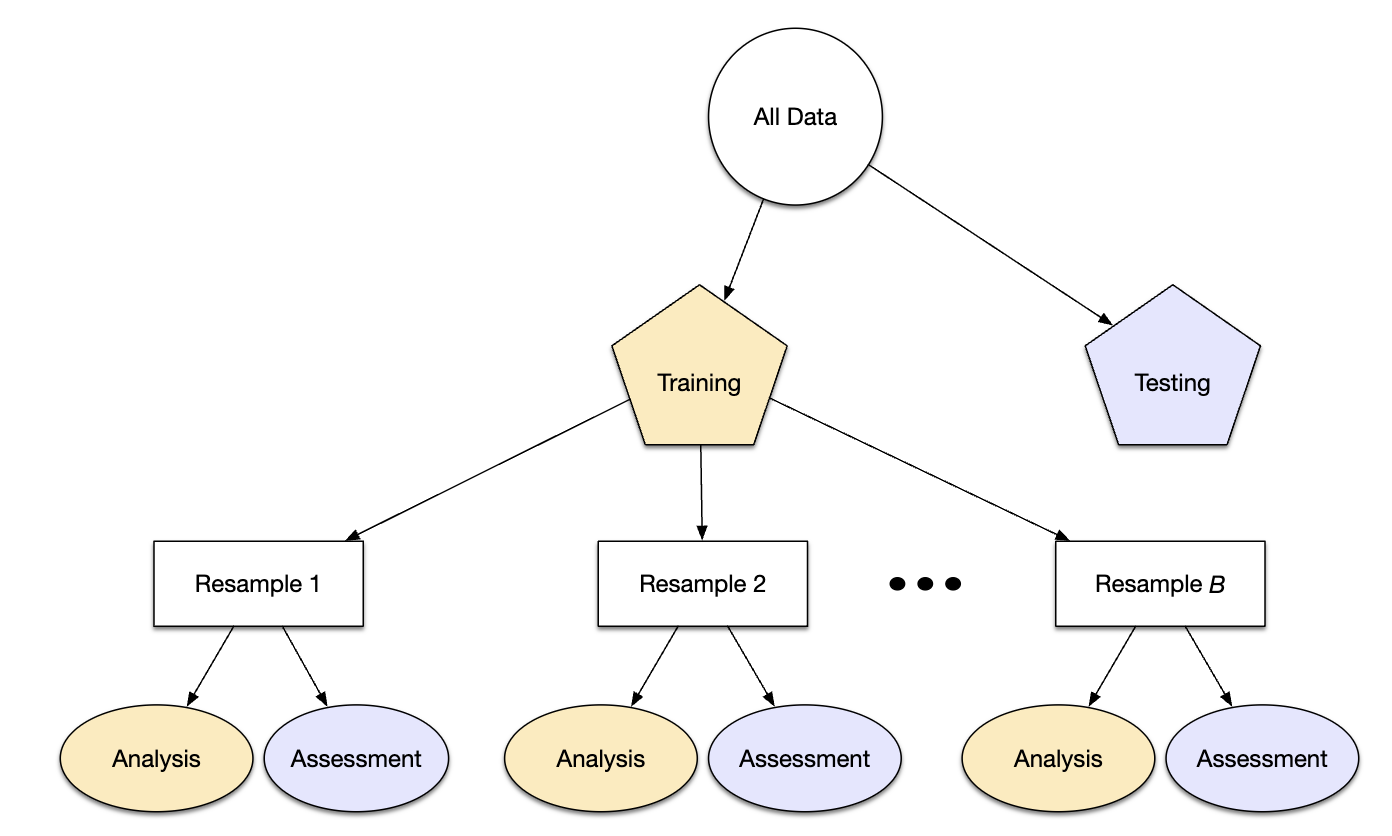
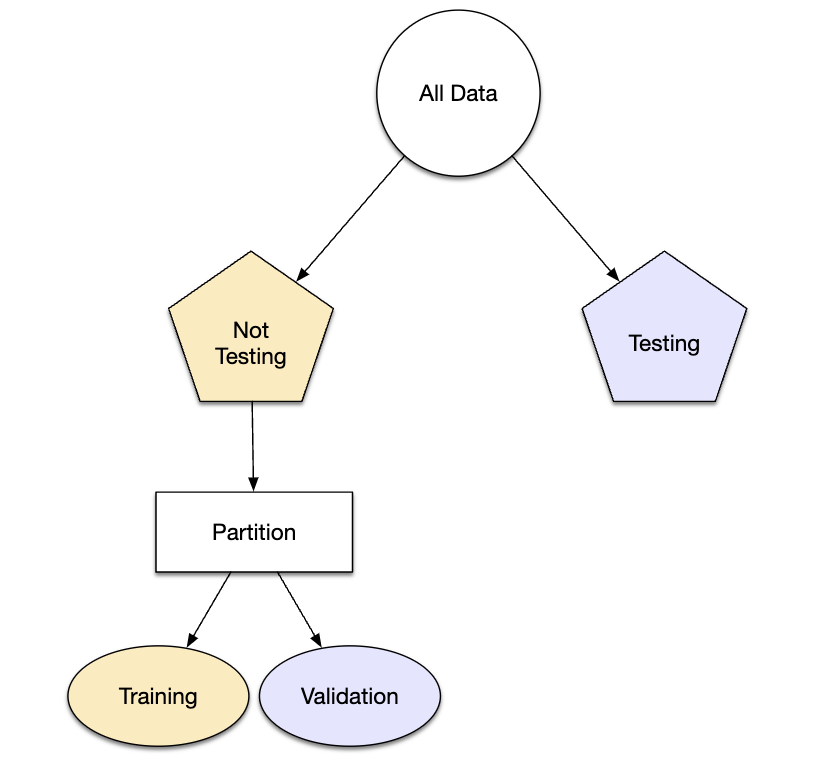
Metody resamplingu są empirycznymi systemami symulacji, które emulują proces używania pewnych danych do modelowania i innych danych do oceny. Większość metod resamplingu jest iteracyjna, co oznacza, że proces ten jest powtarzany wielokrotnie. Schemat na Rys. 7.1 ilustruje, jak generalnie działają metody resamplingu.
Rys. 7.1: Przykład podziału zbioru danych z wykorzystaniem resamplingu
Resampling jest przeprowadzany tylko na zbiorze treningowym. Zbiór testowy nie bierze w nim udziału. Dla każdej iteracji ponownego próbkowania dane są dzielone na dwie podpróbki, na których:
Model jest dopasowywany za pomocą zbioru analitycznego (ang. analysis set).
Model jest oceniany za pomocą zbioru do oceny (ang. assessment set).
Te dwie próby danych są w pewnym sensie analogiczne do zestawów treningowych i testowych. Używany przez nas język analizy i oceny pozwala uniknąć pomyłek związanych z początkowym podziałem danych. Te zbiory danych wzajemnie się wykluczają. Schemat podziału stosowany do tworzenia zbiorów analizy i oceny jest zazwyczaj cechą definiującą metodę.
Załóżmy, że przeprowadzono 20 iteracji ponownego próbkowania. Oznacza to, że 20 oddzielnych modeli jest dopasowywanych do zbiorów analiz, a odpowiadające im zbiory oceny dają 20 zbiorów statystyk wydajności. Ostateczne oszacowanie wydajności dla modelu jest średnią z 20 powtórzeń statystyki. Średnia ta ma bardzo dobre właściwości uogólniające i jest znacznie lepsza niż szacunki na zbiorze uczącym.
7.1 Walidacja krzyżowa
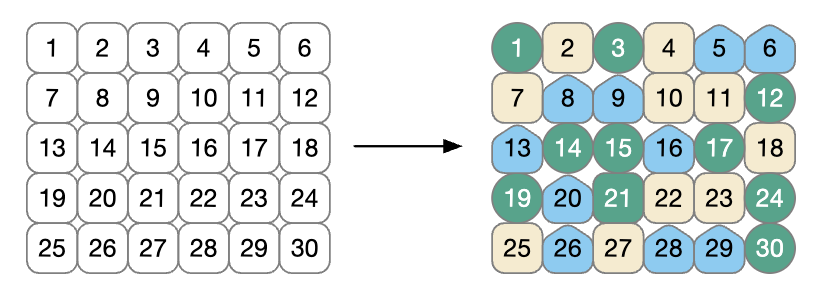
Walidacja krzyżowa (ang. cross-validation) jest dobrze ugruntowaną metodą próbkowania. Chociaż istnieje wiele odmian, najbardziej powszechną metodą walidacji krzyżowej jest \(V\)-krotna walidacja krzyżowa. Dane są losowo dzielone na \(V\) zbiorów o mniej więcej równej wielkości (zwanych krotkami lub foldami). Dla ilustracji, \(V = 3\) jest pokazane na Rys. 7.2 dla zbioru danych składającego się z 30 punktów zbioru treningowego z losowym przydziałem foldów. Liczba wewnątrz symboli to numer próbki.
Rys. 7.2: 3-krotny sprawdzian krzyżowy
Kolory symboli na Rys. 7.2 reprezentują ich losowo przypisane foldy.
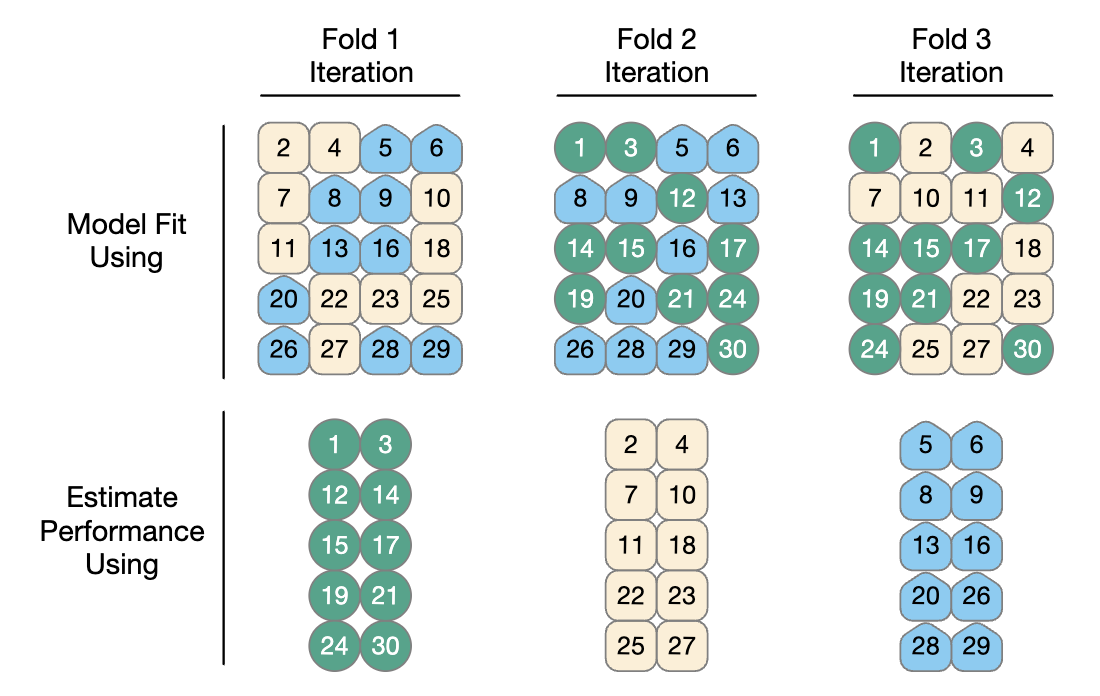
W przypadku trzykrotnej walidacji krzyżowej trzy iteracje próbkowania przedstawiono na Rys. 7.3. Dla każdej iteracji jeden fold jest zatrzymywany do oceny modelu, a pozostałe foldy są używane do uczenia modelu. Proces ten jest kontynuowany dla każdego folda, tak że trzy modele dają trzy zestawy statystyk dopasowania.
Rys. 7.3: Zastosowanie foldów w uczeniu i ocenie dopasowania modeli
Gdy \(V = 3\), zbiory analiz stanowią 2/3 zbioru treningowego, a każdy zbiór oceny stanowi odrębną 1/3. Końcowa estymacja resamplingu wydajności uśrednia każdą z \(V\) replik.
Użycie \(V = 3\) jest dobrym wyborem do zilustrowania walidacji krzyżowej, ale jest to zły wybór w praktyce, ponieważ jest zbyt mało foldów, aby wygenerować wiarygodne szacunki. W praktyce wartości \(V\) to najczęściej 5 lub 10; raczej preferujemy 10-krotną walidację krzyżową jako domyślną, ponieważ jest ona wystarczająco duża, aby uzyskać dobre wyniki w większości sytuacji.
Jakie są skutki zmiany \(V\)? Większe wartości powodują, że szacunki z próbkowania mają mały błąd/obciążenie, ale znaczną wariancję. Mniejsze wartości \(V\) mają duży błąd, ale niską wariancję. Preferujemy 10-krotne, ponieważ szum jest zmniejszony przez replikacje, ale obciążenie już nie.
Kod
set.seed(1001)ames_folds<-vfold_cv(ames_train, v =10)ames_folds
Kolumna o nazwie splits zawiera informacje o tym, jak podzielone zostaną dane (podobnie jak obiekt używany do tworzenia początkowej partycji trening/test). Chociaż każdy podział ma zagnieżdżoną kopię całego zbioru treningowego, R jest na tyle inteligentny, że nie tworzy kopii danych w pamięci. Metoda print wewnątrz tibble pokazuje częstość występowania każdego z nich: [2107/235] wskazuje, że około dwóch tysięcy próbek znajduje się w zbiorze analitycznym, a 235 w tym konkretnym zbiorze oceniającym.
7.2 Sprawdzian krzyżowy z powtórzeniami
Najważniejszą odmianą walidacji krzyżowej jest \(V\)-krotna walidacja krzyżowa z powtórzeniami. W zależności od rozmiaru danych i innych cech, ocena modelu uzyskana w wyniku \(V\)-krotnej walidacji krzyżowej może być nadmiernie zaszumiona. Podobnie jak w przypadku wielu problemów statystycznych, jednym ze sposobów zmniejszenia szumu jest zebranie większej ilości danych. W przypadku walidacji krzyżowej oznacza to uśrednienie więcej niż \(V\) statystyk.
Aby stworzyć \(R\) powtórzeń \(V\)-krotnej walidacji krzyżowej, ten sam proces generowania foldów jest wykonywany \(R\) razy, aby wygenerować \(R\) zbiorów złożonych z \(V\) podzbiorów. Zamiast uśredniania \(V\) statystyk, \(V\times R\) wartości daje ostateczną estymację resamplingu.
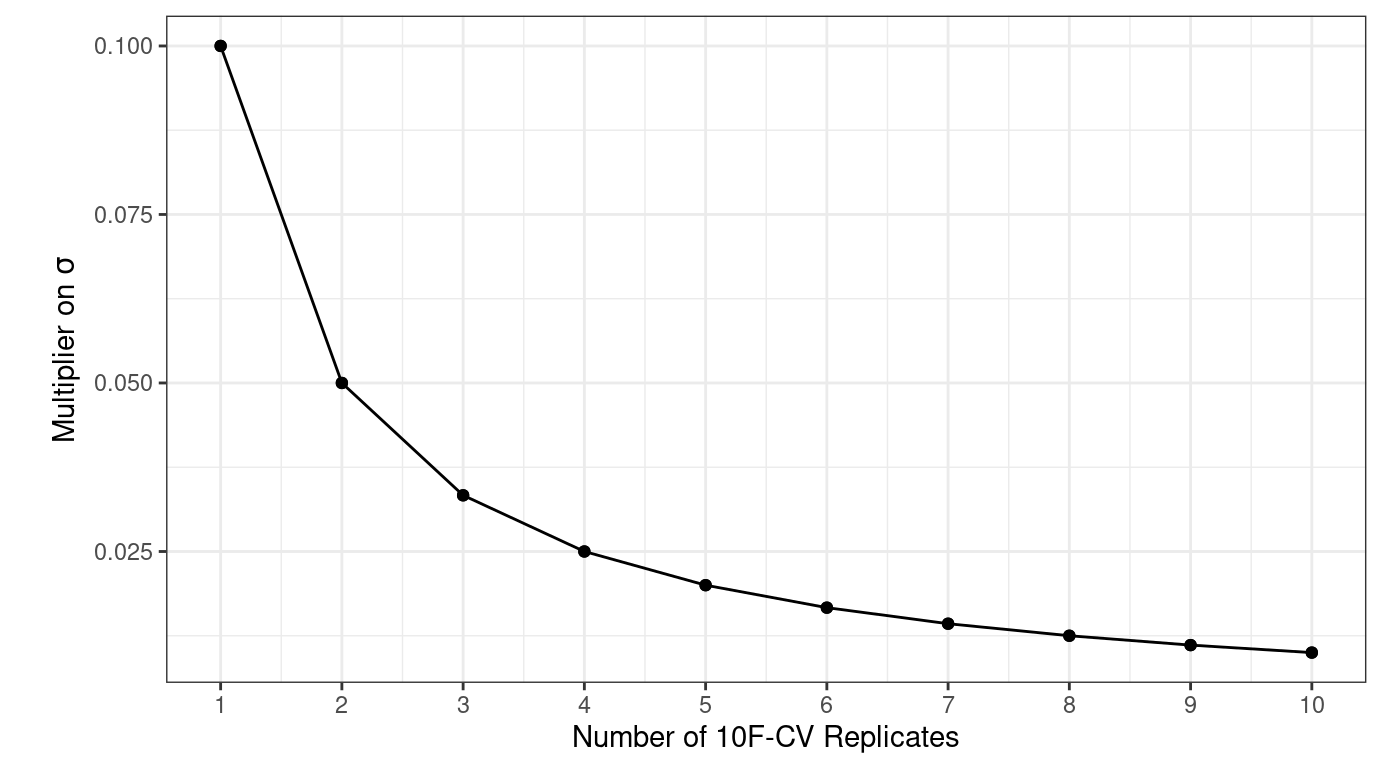
Rozważmy dane ames. Średnio, 10-krotna walidacja krzyżowa używa zestawów oceny, które zawierają około 234 obserwacji. Jeśli RMSE jest wybraną statystyką, możemy oznaczyć odchylenie standardowe tego oszacowania jako \(\sigma\). Przy 10-krotnej walidacji krzyżowej błąd standardowy średniej RMSE wynosi \(\sigma/\sqrt{10}\). Podczas gdy ta wielkość może charakteryzować się jeszcze dużym szumem, powtórzenia zmniejszają błąd standardowy do \(\sigma/\sqrt{10R}\). Dla 10-krotnej walidacji krzyżowej z \(R\) powtórzeniami, wykres na Rys. 7.4 pokazuje, jak szybko błąd standardowy maleje wraz z liczbą powtórzeń.
Rys. 7.4: Wielkość błędu standardowego estymacji w zależności od liczby powtórzeń walidacji krzyżowych
Generalnie zwiększanie liczby replikacji nie ma dużego wpływu na błąd standardowy estymacji, chyba że bazowa wartość \(\sigma\) jest duża, wówczas faktycznie warto zwiększać liczbę replikacji.
Jedną z odmian walidacji krzyżowej jest walidacja krzyżowa typu Leave-One-Out (LOO). Jeśli mamy \(n\) próbek zbioru treningowego, \(n\) modeli jest dopasowywanych przy użyciu \(n - 1\) wierszy zbioru treningowego. Każdy model przewiduje pojedynczy wykluczony punkt danych. Na koniec próbkowania \(n\) prognoz jest łączonych w celu uzyskania pojedynczej statystyki dopasowania
Metody LOO są gorsza w porównaniu z prawie każdą inną metodą oceny dopasowania. Dla wszystkich oprócz patologicznie małych próbek, LOO jest obliczeniowo złożony i może nie mieć dobrych właściwości statystycznych. Chociaż pakiet rsample zawiera funkcję loo_cv(), obiekty te nie są mocno zintegrowane z pakietami tidymodels.
7.4 Walidacja metodą Monte-Carlo
Innym wariantem \(V\)-krotnej walidacji krzyżowej jest walidacja krzyżowa Monte-Carlo (ang. Monte-Carlo Cross-Validation - MCCV) (Xu i Liang 2001). Podobnie jak w sprawdzianie krzyżowym, przydziela ona ustaloną część danych do zbiorów oceny. Różnica między MCCV a zwykłą walidacją krzyżową polega na tym, że w przypadku MCCV ta część danych jest za każdym razem wybierana losowo. Przez to powstają zestawy oceny, które nie wykluczają się wzajemnie.
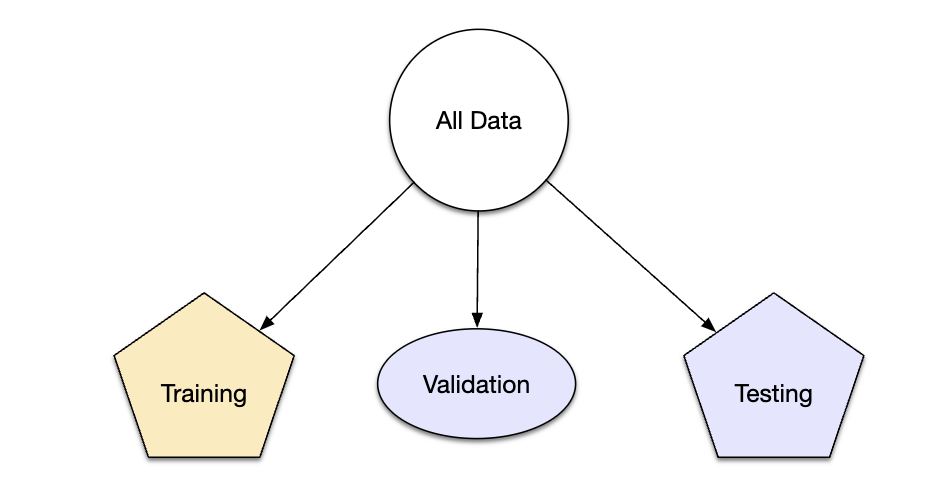
We wcześniejszych rozdziałach wspominana była metoda z wykorzystaniem zbioru walidacyjnego. Polega ona na tym, że przy tworzeniu podziału zbioru na uczący i testowy, dodatkowo zbiór uczący dzieli się na właściwy uczący i walidacyjny (patrz Rys. 7.5). Zbiór walidacyjny jest wykorzystywany do oceny dopasowania modelu, np. w procesie optymalizacji hiperparametrów modelu.
Rys. 7.5: Podział zbiorów na uczący, testowy i walidacyjny
Podziału można dokonać też od razu dzieląc cały zbiór danych na trzy części (patrz Rys. 7.6).
Rys. 7.6: Podział na trzy zbiory
Zbiory walidacyjne są często wykorzystywane, gdy pierwotna pula danych jest bardzo duża. W tym przypadku, pojedyncza duża partia danych jest wystarczająca do scharakteryzowania dopasowania modelu bez konieczności wykonywania wielu iteracji próbkowania.
# Validation Set Split (0.75/0.25)
# A tibble: 1 × 2
splits id
<list> <chr>
1 <split [1756/586]> validation
7.6 Bootstrapping
Bootstrap został pierwotnie wynaleziony jako metoda aproksymacji próbkowego rozkładu statystyki, którego własności teoretyczne są nieznane (Davison i Hinkley 1997). Wykorzystanie jej do szacowania dopasowania modelu jest wtórnym zastosowaniem tej metody.
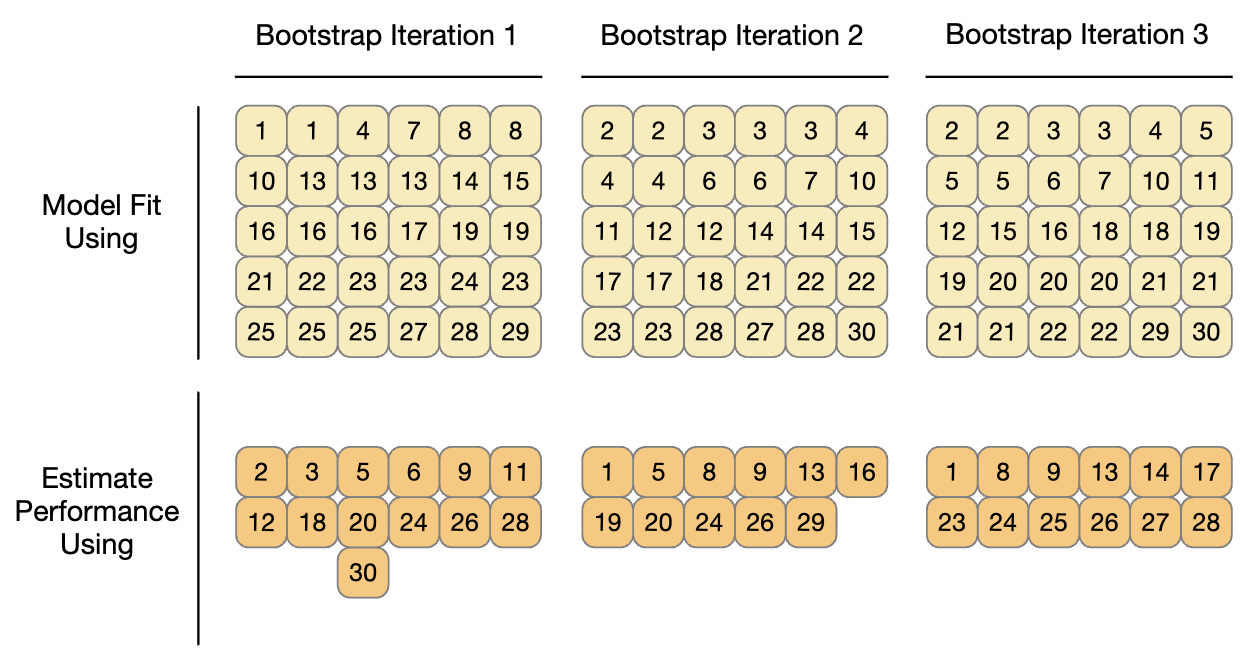
Próbka bootstrapowa zbioru treningowego to próbka, która ma ten sam rozmiar co zbiór treningowy, ale jest losowana ze zwracaniem. Oznacza to, że niektóre obserwacje zbioru treningowego są wielokrotnie wybierane do zbioru analitycznego. Każdy punkt danych ma 63,2% szans na włączenie do zbioru uczącego przynajmniej raz. Zestaw oceny zawiera wszystkie próbki zestawu treningowego, które nie zostały wybrane do zestawu analitycznego (średnio 36,8% zestawu treningowego). Podczas bootstrappingu zestaw oceny jest często nazywany próbką poza workiem (ang. Out-Of-Bag).
Dla zbioru treningowego składającego się z 30 próbek, schemat trzech próbek bootstrapowych przedstawiono na Rys. 7.7
Próbki bootstrapowe dają oszacowania dopasowania, które mają bardzo niską wariancję (w przeciwieństwie do walidacji krzyżowej), ale są pesymistyczne w ocenie obciążenia. Oznacza to, że jeśli prawdziwa dokładność modelu wynosi 90%, bootstrap będzie miał tendencję do oszacowania wartości mniejszej niż 90%. Wielkość błędu systematycznego nie może być określona empirycznie z wystarczającą dokładnością. Dodatkowo, wielkość błędu systematycznego zmienia się w zależności od skali dopasowania. Na przykład obciążenie będzie prawdopodobnie inne, gdy dokładność wynosi 90% w porównaniu z 70%.
Bootstrap jest również wykorzystywany wewnątrz wielu modeli. Na przykład, wspomniany wcześniej model lasu losowego zawierał 1000 indywidualnych drzew decyzyjnych. Każde drzewo było produktem innej próbki bootstrapowej zbioru treningowego.
7.7 Kroczące próbkowanie źródła
Gdy dane mają istotny składnik czasowy (jak np. szeregi czasowe), metoda próbkowania powinna pozwolić na oszacowanie sezonowych i okresowych trendów w szeregach czasowych. Technika, która losowo próbkuje wartości ze zbioru treningowego, nie pozwoli na oszacowanie tych wzorców.
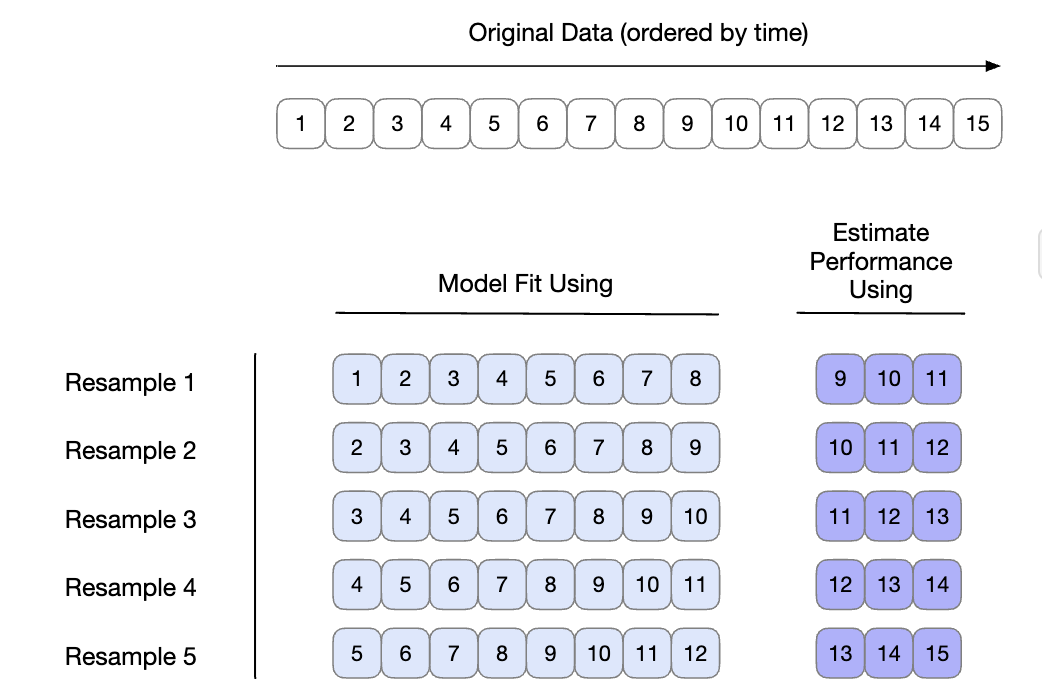
Kroczące próbkowanie źródła (ang. rolling forecast origin resampling) jest metodą, która emuluje sposób, w jaki dane szeregów czasowych są często partycjonowane w praktyce, estymując parametry modelu na danymych historycznych i oceniając go z najnowszymi danymi (Hyndman i Athanasopoulos 2018). Dla tego typu resamplingu określa się rozmiar zbiorów analiz i ocen. Pierwsza iteracja resamplingu wykorzystuje te rozmiary, zaczynając od początku serii. Druga iteracja wykorzystuje te same rozmiary danych, ale przesuwa się o ustaloną liczbę próbek.
Rys. 7.8: Próbkowanie kroczące ze źródła
Dla zilustrowania, zbiór treningowy składający się z piętnastu próbek został ponownie próbkowany z rozmiarem zbioru analizy wynoszącym osiem próbek i zbioru oceny wynoszącym trzy. W drugiej iteracji odrzucono pierwszą próbkę zbioru uczącego, a oba zbiory danych przesunięto do przodu o jeden. W tej konfiguracji uzyskuje się pięć próbek, jak pokazano na Rys. 7.8.
Istnieją dwie różne konfiguracje tej metody:
Zestaw analiz może narastać (w przeciwieństwie do utrzymywania tego samego rozmiaru). Po pierwszym początkowym zestawie analitycznym nowe próbki mogą narastać bez odrzucania wcześniejszych danych. W rezultacie oznacza to, że po nauczeniu i ocenie dopasowania modelu na Resample 1, model jest uczony na zbiorze rozszerzonym o obserwację 9, czyli na danych od 1 do 9. Następnie oceniany na obserwacjach od 10 do 12, itd.
Próbki nie muszą być zwiększane o jeden. Na przykład, w przypadku dużych zestawów danych, blok przyrostowy może wynosić tydzień lub miesiąc zamiast dnia.
7.8 Oszacowanie dopasowania z wykorzystaniem resamplingu
Każda z metod resamplingu omówionych w tym rozdziale może być wykorzystana do oceny procesu modelowania (w tym przetwarzania wstępnego, dopasowania modelu itp.). Metody te są skuteczne, ponieważ do trenowania modelu i oceny modelu wykorzystywane są różne grupy danych. Przebiega on w następujący sposób:
Podczas resamplingu zbiór analityczny jest używany do wstępnego przetwarzania danych, a następnie przetworzonych danych używa do dopasowania modelu.
Statystyki przetwarzania wstępnego opracowane przez zbiór analiz są stosowane do zbioru oceny. Prognozy ze zbioru oceny wskazują wydajność modelu na nowych danych.
Ta sekwencja powtarza się dla każdej próby. Jeśli istnieje \(B\) prób, wówczas mamy \(B\) powtórzeń każdej z metryk dopasowania. Ostateczna ocena jest średnią tych \(B\) statystyk. Jeśli \(B = 1\), jak w przypadku zbioru walidacyjnego, pojedyncze statystyki reprezentują ogólne dopasowanie.
Kod
# ustawiamy kontrolę resamplingu w ten sposbów aby zapisać predykcje i # nauczony przepływ - domyślnie nie są zapisywanekeep_pred<-control_resamples(save_pred =TRUE, save_workflow =TRUE)set.seed(1003)rf_res<-rf_wflow|>fit_resamples(resamples =ames_folds, control =keep_pred)rf_res
Chociaż te kolumny listy mogą wyglądać zniechęcająco, można je łatwo przekonfigurować za pomocą tidymodels. Na przykład, aby zwrócić metryki wydajności w bardziej użytecznym formacie:
Kod
collect_metrics(rf_res)
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 0.0719 10 0.00322 Preprocessor1_Model1
2 rsq standard 0.839 10 0.00776 Preprocessor1_Model1
Aby uzyskać metryki dla każdej próby, należy użyć opcji summarize = FALSE. Natomiast aby uzyskać predykcje z poszczególnych foldów użyjemy:
Kolumna .row jest liczbą całkowitą, która odpowiada numerowi wiersza oryginalnego zestawu treningowego, tak aby te wyniki mogły być odpowiednio połączone z oryginalnymi danymi.
Wskazówka
Dla niektórych metod resamplingu, takich jak bootstrap lub walidacja krzyżowa z powtórzeniami, otrzymamy wiele predykcji na wiersz oryginalnego zestawu treningowego. Aby uzyskać jedną statystykę (średnią z predykcji) użyj collect_predictions(object, summarize = TRUE).
Kod
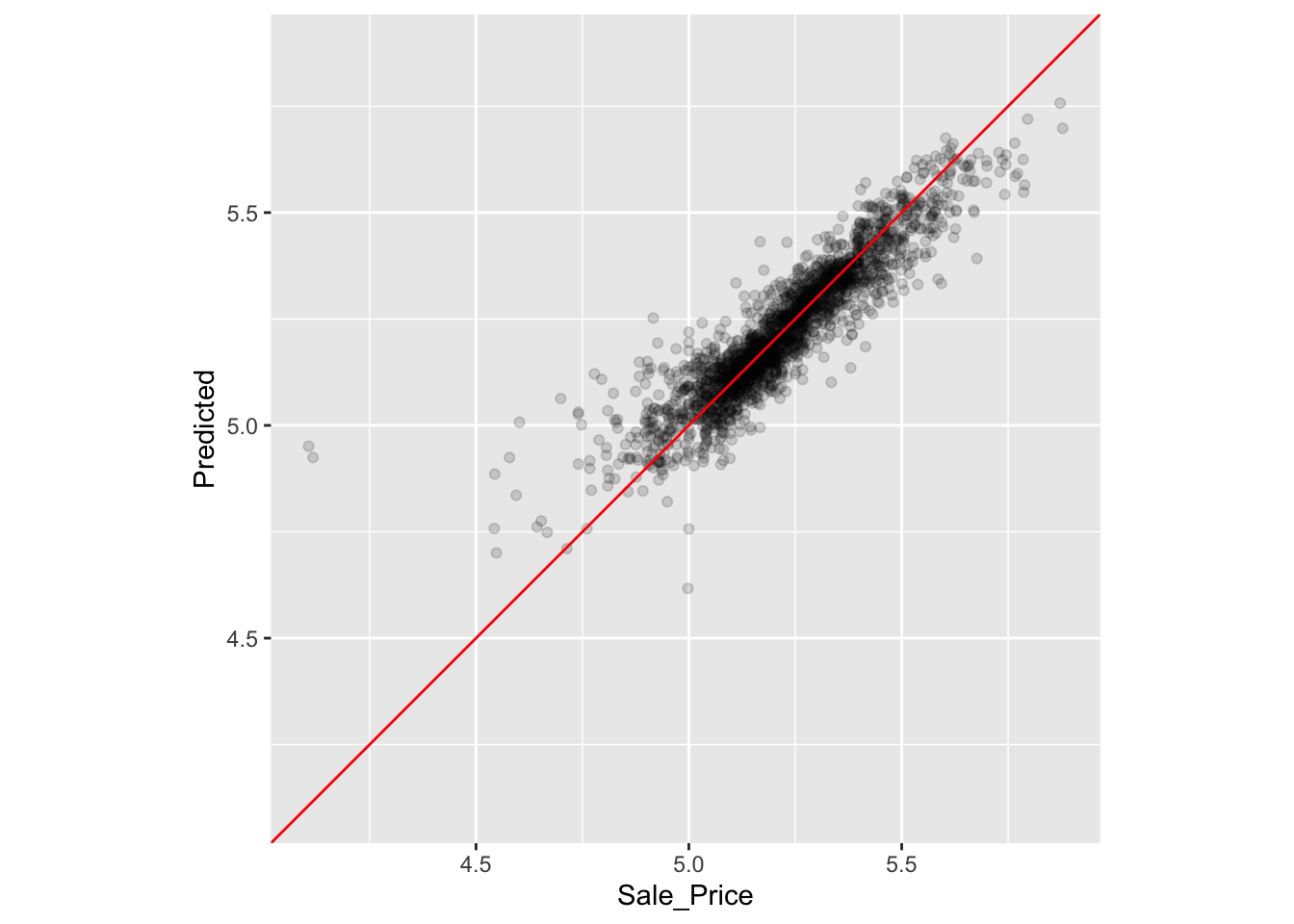
assess_res|>ggplot(aes(x =Sale_Price, y =.pred))+geom_point(alpha =.15)+geom_abline(color ="red")+coord_obs_pred()+ylab("Predicted")
Rys. 7.9: Porównanie predykcji z modelu z obserwowanymi wartościami na podstawie wyników resamplingu
W zbiorze treningowym znajdują się dwa domy o niskiej zaobserwowanej cenie sprzedaży, których cena jest znacznie zawyżona przez model. Które to domy? Dowiedzmy się tego z wyniku assess_res:
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 0.0752 1 NA Preprocessor1_Model1
2 rsq standard 0.827 1 NA Preprocessor1_Model1
Jak widać wyniki te są zbliżone do otrzymanych z wykorzystaniem próby testowej.
7.9 Przetwarzanie równoległe
Pakiet tune używa pakietu foreach do przeprowadzenia obliczeń równoległych. Obliczenia te mogą być podzielone pomiędzy rdzenie procesora na tym samym komputerze lub na różnych komputerach, w zależności od wybranej technologii.
Liczbę dostępnych rdzeni można wykryć za pomocą:
Kod
# Liczba fizycznych rdzeniparallel::detectCores(logical =FALSE)
[1] 8
Kod
# liczba logicznych rdzeni parallel::detectCores(logical =TRUE)
[1] 8
Różnica między tymi dwoma wartościami jest związana z typem procesora. Na przykład większość procesorów Intela wykorzystuje hyperthreading2, który tworzy dwa wirtualne rdzenie dla każdego fizycznego rdzenia. Dodatkowe zasoby mogą poprawić wydajność, jednak rzadko można je stosować na wszystkich rdzeniach fizycznych, ponieważ pewne zasoby są potrzebne do obsługi hyperthreadingu.
2 wielowątkowość współbieżna
W przypadku fit_resamples() i innych funkcji w pakiecie tune, przetwarzanie równoległe występuje, gdy użytkownik zarejestruje pakiet równoległego przetwarzania. Owe pakiety definiują sposób wykonywania przetwarzania równoległego. W systemach operacyjnych Unix i macOS jedną z metod podziału obliczeń jest rozgałęzienie wątków. Aby to umożliwić, załaduj pakiet doMC i zarejestruj liczbę równoległych rdzeni dla foreach:
Kod
# tylko w Unix i macOSlibrary(doMC)registerDoMC(cores =4)
To daje instrukcje dla fit_resamples(), aby uruchomić 1/4 obliczeń na każdym z czterech rdzeni. Aby zresetować obliczenia do przetwarzania sekwencyjnego:
Kod
registerDoSEQ()
Alternatywnie, inne podejście do paralelizacji obliczeń wykorzystuje gniazda sieciowe. Pakiet doParallel umożliwia tę metodę (możliwą do wykorzystania przez wszystkie systemy operacyjne):
Jeszcze innym pakietem R, który ułatwia przetwarzanie równoległe, jest pakiet future. Podobnie jak foreach, zapewnia on wykonywanie równoległych obliczeń na wybranej liczbie rdzeni. Pakiet ten jest używany w połączeniu z foreach poprzez pakiet doFuture.
Przetwarzanie równoległe z pakietem tune ma tendencję do zapewnienia liniowego przyspieszenia dla pierwszych kilku rdzeni. Oznacza to, że przy dwóch rdzeniach obliczenia są dwukrotnie szybsze. W zależności od typu danych i modelu, wzrost prędkości spada, tak że po włączeniu czterech czy pięciu rdzeni prędkość nie wzrośnie 4- czy 5-krotnie. Użycie większej liczby rdzeni nadal będzie skracać czas potrzebny do wykonania zadania; po prostu ich efektywność spada wraz z włączeniem dodatkowych rdzeni.
Zakończmy ostatnią uwagą na temat obliczeń równoległych. Dla każdej z tych technologii, wymagania dotyczące pamięci wzrastają z każdym dodatkowym rdzeniem. Na przykład, jeśli bieżący zestaw danych zajmuje 2 GB pamięci i używane są trzy rdzenie, całkowite zapotrzebowanie na pamięć wyniesie 8 GB (2 dla każdego procesu roboczego plus oryginał). Użycie zbyt wielu rdzeni może spowodować znaczne spowolnienie obliczeń (i komputera).
7.10 Przechowywanie wyników resamplingu
Modele utworzone podczas próbkowania nie są zapisywane. Modele te są trenowane w celu oceny dopasowania i zazwyczaj nie potrzebujemy ich po obliczeniu miar dopasowania. Jeśli określone podejście do modelowania okaże się najlepszą opcją dla naszego zestawu danych, wtedy najlepszym wyborem jest ponowne dopasowanie modelu do całego zestawu uczącego, aby parametry modelu mogły być oszacowane przy użyciu większej ilości danych.
Podczas gdy te modele utworzone podczas resamplingu nie są zachowywane, istnieje metoda na zapisanie ich lub części składników. Opcja extract funkcji control_resamples() określa funkcję, która przyjmuje pojedynczy argument; my użyjemy x. Gdy zostanie wykonana, x przekazuje w wyniku dopasowany obiekt przepływu, niezależnie od tego, czy przekazałeś fit_resamples() z przepływem. Przypomnijmy, że pakiet workflows posiada funkcje, które mogą wyciągać różne składniki obiektów (np. model, recepturę itp.).
Kod
ames_rec<-recipe(Sale_Price~Neighborhood+Gr_Liv_Area+Year_Built+Bldg_Type+Latitude+Longitude, data =ames_train)%>%step_other(Neighborhood, threshold =0.01)|>step_dummy(all_nominal_predictors())|>step_interact(~Gr_Liv_Area:starts_with("Bldg_Type_"))|>step_ns(Latitude, Longitude, deg_free =20)lm_wflow<-workflow()|>add_recipe(ames_rec)|>add_model(linear_reg()|>set_engine("lm"))lm_fit<-lm_wflow|>fit(data =ames_train)# wyciągnijmy przepisextract_recipe(lm_fit, estimated =TRUE)# wyciągnijmy modelget_model<-function(x){extract_fit_parsnip(x)|>tidy()}# tak działa na pojedynczym modeluget_model(lm_fit)
Może się to wydawać zawiłą metodą zapisywania wyników modelu. Jednakże, extract jest elastyczna i nie zakłada, że użytkownik będzie zapisywał tylko jedną tibble dla każdej próbki. Na przykład, metoda tidy() może być uruchomiona zarówno na przepisie jak i na modelu. W tym przypadku zwrócona zostanie lista dwóch tibble.